ডাটা সাইন্সের সমস্যা সমাধান করার জন্য কোন টেমপ্লেট নেই। প্রতিটি নতুন ডেটাসেট এবং নতুন সমস্যার সাথে রোডম্যাপ পরিবর্তিত হয়। কিন্তু আমরা বিভিন্ন প্রকল্পে অনুরূপ পদক্ষেপ দেখতে পারি। আমি উচ্চমাধ্যমিক ডাটা সাইন্সের বিজ্ঞানীদের একটি উদাহরণ হিসাবে পরিবেশন করার জন্য একটি পরিষ্কার ওয়ার্কফ্লো তৈরি করতে চেয়েছিলেন। আমি ডাটা সাইন্সের বিজ্ঞানীদের সাথে কাজ করা মানুষদেরকে ডাটা সাইন্সকে সহজে বুঝতে সহায়তা করতে চেয়েছিলাম।
এটি একটি উচ্চ স্তরের ওভারভিউ এবং এই ওভারভিউতে প্রতিটি ধাপ (এবং প্রায় প্রত্যেক বাক্য) নিজস্বভাবে সমাধান করা যেতে পারে। হস্টি এবং তিবশিরানী এবং স্ট্যানফোর্ড এ অ্যান্ড্রু এনজির মেশিন লার্নিং কোর্সের মত অনেক কোর্স স্ট্যাটিক্যাল লার্নিং অভিক্ষেপের মত অনেক বই, আরো বিস্তারিতভাবে এই বিষয়ের মধ্যে যান। ডাটা সাইন্স সম্প্রদায় মহান সাহিত্য এবং মহান সম্পদপূর্ণ। আপনি আকর্ষণীয় খুঁজে পেতে কোনো বিষয় গভীরভাবে ডুব নিশ্চিত করুন।
সংক্ষিপ্ত বিবরণ
১.অবজেক্টিভ
২.ইমপোর্টিং ডাটা
৩.ডাটা এক্সপ্লোরেশন এন্ড ডাটা ক্লিনিং
৪.বেসলাইন মডেলিং
৫.সেকেন্ডারি মডেলিং
৬.কমুনিকেটিং রেজাল্টস
৭. কনক্লুশন
৮.রিসোর্সেস
পরিশেষে, আমি বলতে চাই যে এই প্রক্রিয়া সম্পূর্ণরূপে রৈখিক নয়।আপনি তথ্য সম্পর্কে আরও জানতে আরও কিছু দেখুন এবং নতুন সমস্যা বের করে এই পথ ধরে সল্ভ করুন।
চলুন শুরু করি!
১.অবজেক্টিভ
সমস্যাটি কি সমাধান করার চেষ্টা করছেন? সমীকরণ থেকে মডেলিং, মূল্যায়ন ম্যাট্রিক্স এবং ডেটা বিজ্ঞান সরান। আপনার কোম্পানীর সমস্যা কি? আপনি কি সম্পর্কে আরও জানতে চান? স্পষ্টতইভাবেই আপনার সমস্যাটি বর্ণনা করে সমাধান করা প্রথম ধাপ এবং কোন সমস্যা ছাড়াই।
এই কর্মপ্রবাহের জন্য, আমরা IMDB.com এ সর্বোচ্চ স্থান পাওয়া চলচ্চিত্র বিশ্লেষণ করতে যাচ্ছি। আমি বাজেট, রানটাইম, এবং ওয়েবসাইটের মতামতের উপর ভিত্তি করে আইএমডিবি মুভি রেটিং পূর্বাভাসের একটি মডেল তৈরি করতে চাই।
২.ইমপোর্টিং ডাটা
ডেটা বিভিন্ন উৎস থেকে আসতে পারে আপনি আপনার স্থানীয় মেশিন থেকে সিএসভি ফাইল আমদানি করতে পারেন, এসকিউএল ব্যবহার করতে পারেন অথবা ইন্টারনেট থেকে তথ্য ছাঁটাই করতে ওয়েব স্ক্রাপার ব্যবহার করতে পারেন। আমি পাইথন লাইব্রেরির ব্যবহার করতে চাই, পান্ডস, ডাটা আমদানি করতে। পান্ডাস একটি মহান ওপেন সোর্স ডেটা বিশ্লেষণ লাইব্রেরী। আমরা এই ওয়ার্কফ্লোর ডেটা পরিষ্কারকরণের ধাপে পান্ডস ব্যবহার করব।
এই উদাহরণের জন্য, আমরা আমাদের স্থানীয় মেশিন থেকে তথ্য আমদানি করতে যাচ্ছি। আমি Kaggle.com থেকে একটি ডেটা সেট ব্যবহার করব। ডেটাসেটটির নাম “এই দশক শীর্ষস্থানীয় ইংরেজী চলচ্চিত্র” এবং এটি একটি CSV ফাইলে ছিল।
Top Ranked English Movies Of This Decade.


আমি এক্ষুণি বলতে চাই যে এই ডেটাসেটটি খুবই ছোট। পর্যবেক্ষণ সংখ্যা তুলনামূলকভাবে কম। কিন্তু কারণ এই একটি উদাহরণ সমস্যা, আমি ঠিক আছি এই কার্যধারার সঙ্গে এগিয়ে । শিল্পে, আপনি অবশ্যই একটি বড় ডেটাসেট চাইবেন।
৩.ডাটা এক্সপ্লোরেশন এন্ড ডাটা ক্লিনিং
এখন যে আমাদের পান্ডাসে আমদানি করা আমাদের তথ্য আছে, আমরা আমাদের ডাটাফ্রেমের প্রথম কয়েকটি সারি খুঁজে পেতে পারি।

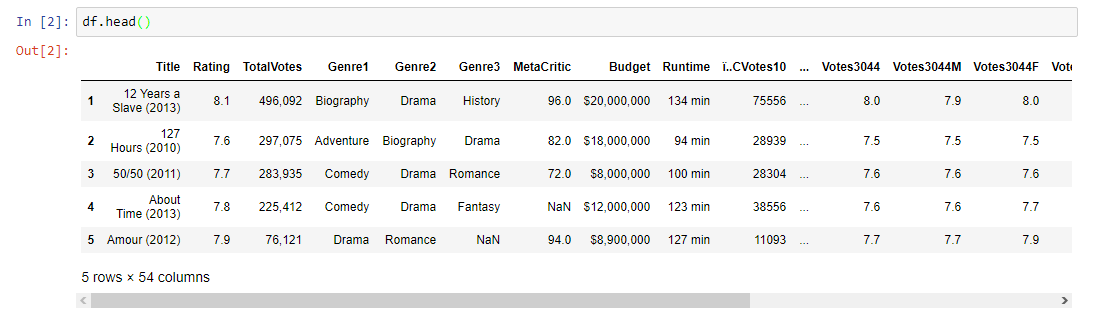
তিনটি পার্থক্য আছে যা আমি পেতে থেকে যেতে চাই এই তত্ত্বাবধানে শিক্ষণ বা অপর্যাপ্ত শিক্ষণ কি? এটি একটি শ্রেণীবিভাগ সমস্যা বা এটি একটি রিগ্রেশন সমস্যা? এটি একটি ভবিষ্যদ্বাণী সমস্যা বা একটি অভূতপূর্ব সমস্যা?
সুপারভাইজড লার্নিং বা আনসুপারভাইজড লার্নিংঃ
সুপারভাইজড লার্নিং এর সাথে, আমরা স্পষ্টভাবে নির্ভরশীল এবং স্বতন্ত্র ভেরিয়েবলগুলি লেবেলযুক্ত করেছি। নির্ভরশীল ভেরিয়েবল (আমাদের লক্ষ্য) পরিচিত। যদি আমরা একটি রৈখিক রিগ্রেশন দেখছি, আমাদের y ভেরিয়েবল স্পষ্ট। যদি আমাদের একটি পরিষ্কারভাবে লেবেলযুক্ত y ভেরিয়েবল থাকে, তাহলে আমরা নজরদারি শেখার কাজ করছি কারণ কম্পিউটারটি আমাদের পরিষ্কারভাবে লেবেলকৃত ডেটাসেট থেকে শিখছে। এটা আমাদের x ভেরিয়েবল এবং আমাদের y ভেরিয়েবলের মধ্যে সম্পর্ক শিখছে। তত্ত্বাবধানে শিক্ষার পুনর্বিবেচনা এবং শ্রেণিবদ্ধ সমস্যাগুলির মধ্যে ভাগ করা যায়। অনির্বাচিত শেখার সঙ্গে, আমরা একটি স্পষ্ট নির্ভরশীল পরিবর্তনশীল না। আমাদের x ভেরিয়েবলের একটি বৈশিষ্ট্য ম্যাট্রিক্স এবং কোন yভেরিয়েবল নেই । আনসুপারভাইজড লার্নিং সমস্যাগুলির ক্লাস্টারিং এবং সংস্থাগুলি তৈরি করতে পারে। আমি এই ওভারভিউর মধ্যে ক্লাস্টারিং পাইনি , কিন্তু এটা শিখার জন্য অনেক ভালো স্কিলসেট। উপরন্তু, আনসুপারভাইজড লার্নিং তথ্য অনুসন্ধানের দৃষ্টিকোণ থেকে উপকারী হতে পারে।
ক্লাসিফিকেশন বা রিগ্রেশনঃ
এখন আমরা জানি যে আমাদের একটি সুপারভাইজড লার্নিং সমস্যা আছে, আমরা এটি একটি শ্রেণীবিভাজন বা রিগ্রেশন সমস্যা কিনা তা নির্ধারণ করতে পারি । আমি y ভেরিয়েবলটি দেখি এবং এটি নির্ধারণ করি যে ঐ ভেরিয়েবলটি একটি ধারাবাহিক বা বিচ্ছিন্ন পরিবর্তনশীল। ক্রমবর্ধমান y ভেরিয়েবল ক্লাসিফিকেশনের সেটিংসে পড়ে এবং ক্রমাগত পরিমাণগত ভেরিয়েবল রিগ্রেশন সেটিংসে পড়ে। যেখানে নির্ধারণ করা হবে একটি শ্রেণিবদ্ধ সমস্যাকে একটি উদাহরণে বা একটি ক্রেডিট কার্ড লেনদেন হয় না প্রতারণাপূর্ণ। এটি একটি বাইনারি ক্লাসিফিকেশন সমস্যা কারণ প্রতিটি লেনদেন প্রতারণামূলক বা প্রতারণামূলক নয়। একটি রিগ্রেশন সমস্যা সর্বোত্তম উদাহরণ বর্গ ফুটেজ, বেডরুম সংখ্যা, এবং লট আকার মত বৈশিষ্ট্য উপর ভিত্তি করে একটি ঘর দাম নির্ধারণ করা হয়।
প্রেডিকশন বা ইনফারেন্স:
একটি প্রেডিকশন সেটিংয়ে, আমরা চাই আমাদের মডেলে একটি মূল্যবরাদ্দ করতে তা হলও y , বিভিন্ন বৈশিষ্ট্য দেওয়া । উপরে আমাদের রিগ্রেশন উদাহরণ থেকে, আমরা ভোজন করতে চাই আমাদের মডেলের একটি ঘর যেটির আছে 1500 বর্গ ফুট, 2 বেডরুম, এবং 0.50 একর প্রচুর । আমাদের মডেল তখন প্রেডিকশন করবে যে ঘর মূল্য ছিল $ 200,000 । একটি নিছক সেটিংসে, আমরা জানতে চাই কিভাবে একটি বৈশিষ্ট্য (x ভেরিয়েবল) আউটপুটে (y ভেরিয়েবল) প্রভাবিত করে। আমরা দেখতে পারি কিভাবে একটি বাড়ির দাম বাড়বে যখন আপনি বাড়িতে একটি অতিরিক্ত বেডরুমের যোগ করুন।
আপনার ডেটা সায়েন্সের সমস্যা সমাধান করার সময় এই তিনটি প্রশ্ন অনেক দিক নির্দেশনা প্রদান করতে পারে।
আমাদের উদাহরণে, আমরা মেটাট্রেটিক রেটিং, বাজেট, রানটাইম এবং ভয়েস থেকে আইএমডিবি রেটিং সম্পর্কে ভবিষ্যদ্বাণী করতে রিগ্রেশন (তত্ত্বাবধানে শিক্ষার) ব্যবহার করতে যাচ্ছি।
কোডিং অংশে ফিরে! চলুন আমরা নির্ধারণ করি যে কোন ভেরিয়েবলটি আমাদের লক্ষ্য এবং যা আমরা মনে করি গুরুত্বপূর্ণ।
আমাদের লক্ষ্য হল কলাম শিরোনাম নির্ধারণ করা এবং আমাদের বৈশিষ্ট্যগুলি নিম্নোক্ত কলামগুলি হতে যাচ্ছে: মেটা ক্রাইটিক, বাজেট, রানটাইম, ভয়েস, ভোটসন এবং মোটভোট। আমি এই বিশ্লেষণের জন্য প্রয়োজন নেই এমন সব কলামগুলি সরিয়ে দেব।

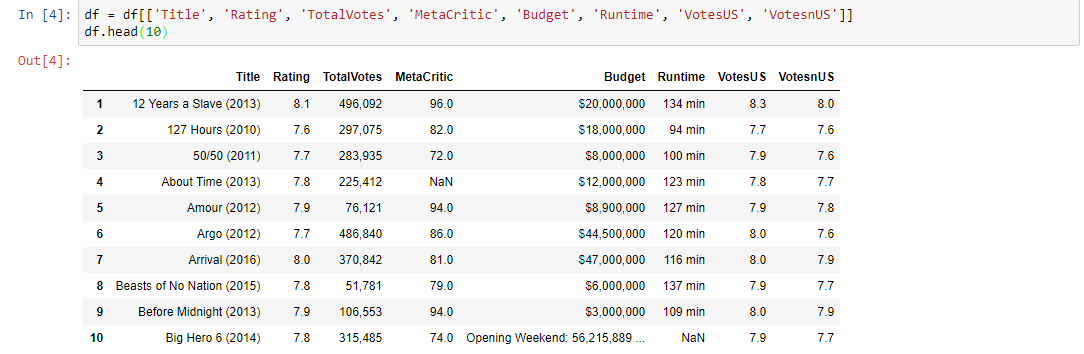
পান্ডা এবং ম্যাটপ্লটলিব (একটি জনপ্রিয় পাইথন প্লটিং লাইব্রেরি) আমাদের অনুসন্ধানের বেশির ভাগ ক্ষেত্রে সহায়তা করতে যাচ্ছে। অনুসন্ধানকারী তথ্য বিশ্লেষণ (ইডিএ) ডেটা বিজ্ঞানীকে তার সাথে কাজ করে এমন ডেটা সম্পর্কে সত্যিই শিখতে পারে। অনেক তথ্য বিজ্ঞানীরা নিজেদের EDA তে ফিরে আসেন এবং পরে তিনি EDA তে খুঁজে পেয়েছেন যে এই পদ্ধতিতে প্রক্রিয়াটি চলছে। EDA(Exploratory data analysis) দেয় একটি সুযোগ ডেটা সায়েন্টিস্টকে তিনি যে তথ্য এর সাথে কাজ করছেন সে সম্পর্কে জানতে সত্যিকারে ।
প্রথম জিনিস আমি চেক করি তথ্যের ধরণ । সঠিক বিন্যাসে সমস্ত মান গ্রহণ করা গুরুত্বপূর্ণ। এটি স্ট্রিংগুলি থেকে স্ট্রিপিং অক্ষরগুলিকে অন্তর্ভুক্ত করতে পারে, পূর্ণসংখ্যাগুলিকে ফ্লোটে রূপান্তর করতে পারে, অথবা অনেক অন্যান্য জিনিসগুলি।








অনুপস্থিত মান এবং নাল মান সাধারণ। কখনও কখনও তাদের মধ্যে খুব সামান্য তথ্য দিয়ে খুব বড় ম্যাট্রিক্স আছে। এটি স্পার ম্যাট্রিক্স হিসাবে পরিচিত হয়। নিখোঁজ এবং নাল মানগুলি পরিচালনা করা সম্পূর্ণ বিষয় নিজের । এই বিষয়টি অনুপস্থিত ডেটা অপবাদ হিসাবে পরিচিত এবং আমি এখানে এটি পেতে পারি না । এই বিষয়ে আরো তথ্য সন্ধান করতে ভুলবেন না, বিশেষ করে যদি আপনি স্পার ম্যাট্রিক্সে চালান আমাদের উদ্দেশ্যের জন্য, কেবল নাল মান সঙ্গে সিনেমা ড্রপ যাচ্ছে। এটি সর্বদা সেরা ধারণা না, কিন্তু আমি এই বিশ্লেষণে তাই করতে নির্বাচিত করেছি।








আপনার ডেটাতে পান্ডাস এর সঙ্গে EDA পরিচালনা করতে পারেন এমন অনেকগুলি উপায় রয়েছে। হারিয়ে যাওয়া মানগুলি পরীক্ষা করা, ডেটা প্রকারগুলি পরীক্ষা করা এবং ডেটা বিন্যাসকরণ কেবল হিমশৈলের টুকরা। অনন্য মান সংখ্যা সন্ধান করুন। আপনার কলামগুলির সংক্ষিপ্ত পরিসংখ্যান পেতে ডেস্ক্রাইব মেথড হিসেবে পান্ডস ব্যবহার করুন । পান্ডাস ডাটা বিশ্লেষণ প্রক্রিয়ার জন্য একটি অত্যন্ত দরকারী হাতিয়ার এবং ডাটা ক্লিনিং এর সাথে সাথে পান্ডাস ডেটা সায়েন্টিস্টদের কাছে অপরিহার্য হাতিয়ার হিসেবে পরিচিত হয়ে উঠছে।
EDA শেষ অংশ প্লটিং করা হয়। প্লট করা খুবই গুরুত্বপূর্ণ কারণ এটি আপনাকে আপনার ডেটা নিরীক্ষণ করতে সহায়তা করে। হিস্টোগ্রাম, স্প্রেটার ম্যাট্রিক্স, এবং বক্স প্লোটগুলি আপনার ডেটা সমস্যাতে অন্তর্দৃষ্টি আরেকটি স্তর প্রদান করতে ব্যবহার করা যেতে পারে। এই উদাহরণের জন্য, আমরা একটি স্প্রেটার ম্যাট্রিক্স তৈরি করতে পান্ডাস ব্যবহার করব।

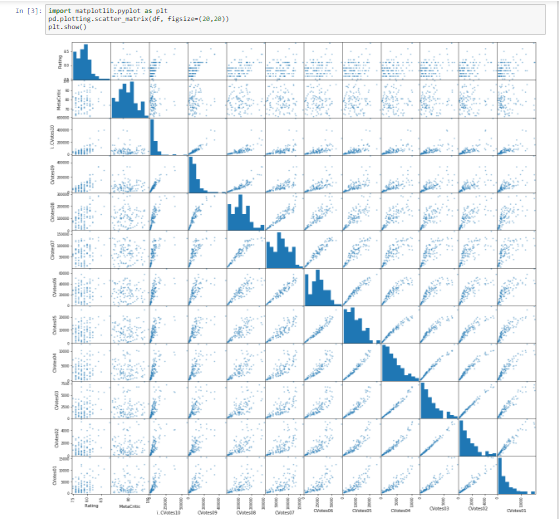
৪.বেসলাইন মডেলিংঃ
একটি তথ্য বিজ্ঞানী হিসাবে, আপনাকে অনেক মডেল নির্মাণ করতে হবে। বিভিন্ন ধরনের কাজগুলি সম্পন্ন করার জন্য আপনি বিভিন্ন অ্যালগরিদম ব্যবহার করবেন। নির্দিষ্ট মডেল যথাযথ হলে সিদ্ধান্ত নিতে আপনার অন্তর্দৃষ্টি এবং অভিজ্ঞতা ব্যবহার করতে হবে। বাণিজ্য দ্বারা একটি অর্থনীতিবিদ হিসাবে, আমি আমার রিগ্রেশন সমস্যার জন্য রৈখিক রিগ্রেশন সঙ্গে শুরু করতে পছন্দ করি এবং ক্লাসিফিকেশন সমস্যার জন্য লজিস্টিক রিগ্রেশন জন্য সঙ্গে শুরু করতে পছন্দ করি। (আমি বেসলাইন ক্লাসিফিকেশন মডেলের KNN এবং আনসুপারভাইজড লার্নিং আমার প্রথম ক্লাস্টারিং অ্যালগরিদম হিসাবে K-Means ব্যবহার করতে প্রবণ হয়।) এই মডেলগুলি আপনাকে একটি বেসলাইন দেবে যা আপনি উন্নত করতে পারেন।
Kaggle প্রতিযোগিতার মধ্যে, অনেক বিজয়ীরা উন্নত নিউরাল নেটওয়ার্ক, XGBoost বা রান্ডম ফরেস্ট ব্যবহার করেছে ডাটা সায়েন্স এর সমস্যা সমাধানে।
Scikit-Learn হল পাইথনের জন্য একটি মেশিন লার্নিং প্যাকেজ যা বিভিন্ন ধরনের কাজের জন্য ব্যবহার করা যেতে পারে। আমরা মডেলিং (শ্রেণীকরণ, রিগ্রেশন এবং ক্লাস্টারিং) জন্য Scikit-Learn ব্যবহার করতে পারি। এটি ডিমেনশনালিটি রিডাকশন (প্রিন্সিপাল কম্পোনেন্ট বিশ্লেষণ), মডেল নির্বাচন (গ্রিড অনুসন্ধান, মূল্যায়ন মেট্রিক্স) এবংপ্রিপ্রসেসিং ডেটার জন্য ব্যবহার করা যেতে পারে। যখন আপনি বিজ্ঞান-শিখার মধ্যে কাজ করছেন তখন বিভিন্ন আলগোরিদিমগুলির মধ্যে মডেলিংগুলির মূলগুলি একই রকম।
মডেল প্রাক প্রক্রিয়াকরণের সময় আমরা আমাদের নির্ভরশীল ভেরিয়েবলগুলি থেকে আমাদের বৈশিষ্ট্যগুলিকে আলাদা করতে যাচ্ছি, বোর্ড জুড়ে ডেটা স্কেল করে এবং আমাদের মডেলকে অতিক্রম করার জন্য ট্রেন-টেস্ট-স্প্লিট ব্যবহার করুন। Overfitting হয় যখন আমাদের মডেল খুব ঘনিষ্ঠভাবে আমাদের প্রশিক্ষণ তথ্য ট্র্যাক এবং এটি নতুন তথ্য খাওয়ানো হয়, এটি ভাল সঞ্চালন না। এর মানে হল এই মডেলটি নতুন সমস্যাগুলিকে ভালভাবে আয়ত্ত করা পারবে না। একটি প্রশিক্ষণ-পরীক্ষা-বিভক্ত তৈরি করা ওভারফাইটিং মোকাবেলা করতে সহায়তা করে। উপরন্তু, আমরা overfitting প্রতিরোধে ক্রস ভ্যালিডেশন ব্যবহার করতে পারি । আপনার নিজের উপর ক্রস ভ্যালিডেশন সম্পর্কে আরো সন্ধান নিশ্চিত করুন।



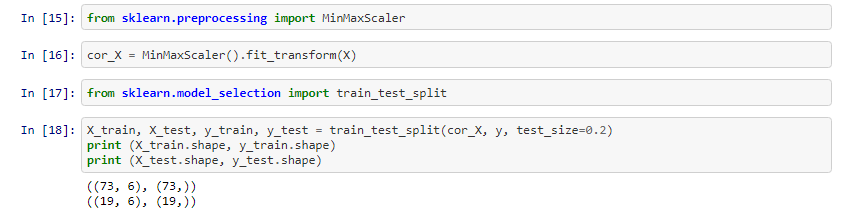
এখন আমরা আমাদের মডেল ব্যবহার করার জন্য প্রস্তুত। আমরা প্রশিক্ষণ তথ্য আমাদের মডেল মাপসই যাচ্ছে। তারপর আমরা আমাদের X_test তথ্য জন্য y মান ভবিষ্যদ্বাণী থাকার দ্বারা আমাদের মডেল পরীক্ষা করতে যাচ্ছি। তারপর আমরা পূর্বাভাস Y মানগুলি প্রকৃত y মান থেকে কতদূর ছিল তা দেখে ভালভাবে আমাদের মডেল সঞ্চালিত মূল্যায়ন করতে পারবো ।

আমাদের মডেল বেশ ভাল সঞ্চালিত। এটি 0.96 এর একটি R-squared পৌঁছতে সক্ষম ছিল। এই মূল্যায়ন মেট্রিক, R- স্কোয়ার্ড, একটি গুডনেস-অফ-ফিট মেট্রিক। এটি আমাদের y ভেরিয়েবলের পরিবর্তনের শতাংশ আমাদের মডেল দ্বারা ব্যাখ্যা করা হয়। এই রিগ্রেশন সমস্যার জন্য, আমরা রুট গড় স্কোয়ার্ড ত্রুটি এবং সামঞ্জস্যপূর্ণ R-squared দিয়ে আমাদের মডেল মূল্যায়ন করতে পারি ।
মডেল মূল্যায়ন অনেক হয়। ক্লাসিফিকেশন সমস্যাগুলির জন্য, সাধারণ মূল্যায়ন মেট্রিক্স হয় সঠিকতা এবং ROC-AUC স্কোর।আপনার মডেল মূল্যায়ন অত্যন্ত গুরুত্বপূর্ণ ।
সামগ্রিকভাবে, আমি এই ফলাফলগুলির সাথে সাবধানতা ব্যবহার করব। আমরা নির্বাচিত বৈশিষ্ট্য সম্ভবত সমান্তরাল হয়। মূলত, কলিনেয়ারিটি যখন আপনার বৈশিষ্ট্যগুলির খুব অনুরূপ বা আমাদের নির্ভরশীল পরিবর্তনশীল সম্পর্কে একই তথ্য প্রদান করা হয়। সমান্তরালতার নিখুঁত উদাহরণ (নিখুঁত সমান্তরালতা) হল একটি বৈশিষ্ট্য যা আমাদের সেলসিয়াসের তাপমাত্রা দেয় এবং আরেকটি ফরেইনহাইট রিপোর্ট করে। এই ভেরিয়েবলগুলির অপ্রয়োজনীয় হবে। বৈশিষ্ট্যগুলির ভেটস এবং ভোটসন (ভোট নন-ইউএস) খুব সম্পর্কিত হতে পারে। একটি উচ্চ R- স্কোয়ার্ড মান আমাদের কেন একটি কারণ হতে পারে। সৌভাগ্যক্রমে, আমরা পার্ট ৫ এ একটি অ-প্যারাম্যাটিক অ্যালগরিদম ব্যবহার করব।
আমরা সামান্যতা যুদ্ধ করতে পারি এমন কয়েকটি উপায় আছে এবং তাদের অধিকাংশ মৌলিক ভোট ভেরিয়েবলের একটি ড্রপ হতে হবে। প্রক্সি ভেরিয়েবল মত অন্যান্য পদ্ধতি আছে, আমরা এই সমান্তরাল সমস্যার সমাধান করতে ব্যবহার করতে পারে। কিন্তু আমরা এখানে পেতে পারি না ।


৫. সেকেন্ডারি মডেলিংঃ
আপনি শত শত মডেল তৈরি করতে পারেন । একক রিগ্রেশন মডেলের মধ্যে যেতে আপনি এই দৃশ্যকল্প ব্যবহার করতে পারেন, আমি একটি Kaggle প্রিয়, রান্ডম ফরেস্ট ব্যবহার করতে যাচ্ছি। রান্ডম ফরেস্ট মডেলটি একটি অভেদ্য মডেল যা শ্রেণীবদ্ধ বা পুনর্বিন্যাস করার জন্য অনেক ডিসিশন ট্রি ব্যবহার করে। রান্ডম ফরেস্ট অ্যালগরিদম এছাড়াও অ- পরামিতি হচ্ছে এর সুবিধা আছে যেহেতু এটি একটি মডেল টিউটোরিয়াল নয় (যা মজার হতে পারে), আমি এই অ্যালগরিদমের বিস্তারিত এর মধ্যে যেতে চাইতেছি না । আসুন দেখি কিভাবে Scikit-Learn এটি ব্যবহার করতে হয়:

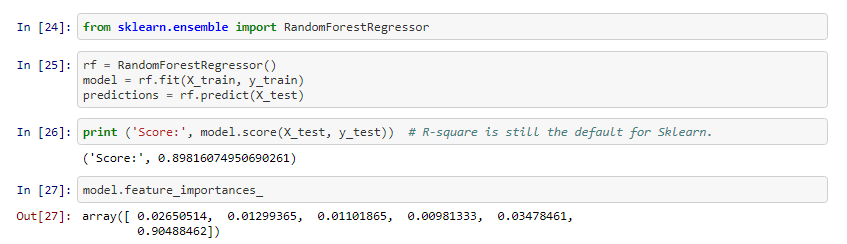
ওহো! আমাদের রান্ডম ফরেস্ট মডেল আমাদের রৈখিক রিগ্রেশন মডেলের চেয়ে খারাপ। এটি একটি বিস্ময়কর ফলাফল। যে আমাদের সরল, সহজে বোঝার মডেল ক্ষমতা রৈখিক রিগ্রেশন মত দেখায়। যদি আমরা বৈশিষ্ট্য ও গুরুত্বের দিকে তাকাই , আমরা দেখতে পারবো এই রান্ডম ফরেস্ট মডেল আমাদের রৈখিক রিগ্রেশন মডেলের সাথে সম্মত হয় যে মার্কিন এর বাইরের ভোটগুলি IMDB রেটিং এর প্রেডিক্টিং এর মধ্যে অনেক কিছু। আমাদের ডেটসেটটি খুবই ছোট তাই এই বিজোড় ফলাফলটি ছোট ডেটাসেটের একটি পণ্য হতে পারে।
বিকল্পভাবে, আমরা উল্লেখ করেছি যে আমাদের রৈখিক রিগ্রেশনকে উচ্চ সমান্তরালতা হতে পারে। এই পরিস্থিতিতে,আমরা এই সমান্তরাল সমস্যার কারণে রৈখিক রিগ্রেশন এর উপর রান্ডম ফরেস্ট এর মডেলের ফলাফল বিশ্বাস করবো ।
৬.কমুনিকেটিং রেজাল্টসঃ
আমার মনে হয় আপনার ডাটা সাইন্সের প্রকল্পে যেতে পারে এমন দুটি নির্দেশিকা আছে: ডাটা সাইন্সের পণ্য এবং ডাটা সাইন্সের রিপোর্ট।
প্রথমত, আপনি একটি ডাটা সাইন্সের পণ্য তৈরি করতে পারেন। উত্পাদনের মধ্যে আপনার মডেল পেতে, আবার, নিজেই একটি বিষয় শুরু করার জন্য, আপনাকে আপনার জুপিটার নোটবুক থেকে স্ক্রিপ্ট থেকে কোড সরাতে হবে। বেশীরভাগ সংস্থাগুলির মধ্যে, ডেটা বিজ্ঞানী এই কোডটি লিখতে সফটওয়্যার ইঞ্জিনিয়ারিং দলের পাশাপাশি কাজ করবে। মডেল প্রথমে পিকেল করা প্রয়োজন এবং এটি Scikit-Learn’s Joblib এর সাথে সম্পন্ন করা যেতে পারে। তারপর আপনার মডেল জন্য একটি অ্যাপ্লিকেশন তৈরি করতে ফ্ল্যাশক এবং হেরোকো ব্যবহার করতে পারেন। ডাটা সাইন্সের পণ্য উন্নয়ন একটি খুব দরকারী দক্ষতা এবং আমি নিজেকে এই প্রসেস মধ্যে গভীর ডাইভিং করছি। আমি আপনাকে একই কাজ করতে উত্সাহিত করছি!
ডেটা বিজ্ঞান সম্প্রদায়ের জন্য আপনার প্রোডাক্টের মতামত সর্বদা বড় শিক্ষার অভিজ্ঞতা। আপনি যদি কিছু চমৎকার উপস্থাপনা দেখতে চান তবে YouTube এ PyData এর ভিডিওগুলি দেখুন। উপরন্তু, একটি ব্লগ পোস্ট লিখুন এবং আপনার কোডটি GitHub এ রাখুন যাতে তথ্য বিজ্ঞান সম্প্রদায় আপনার সাফল্য থেকে শিখতে পারে।
৭. কনক্লুশনঃ
আমি আশা করি এই ওয়ার্কফ্লো এবং মিনি প্রজেক্ট উচ্চাভিলাষী ডেটা বিজ্ঞানী এবং যারা তথ্য বিজ্ঞানীদের সাথে কাজ করে তাদের জন্য সহায়ক। আপনার কোন প্রশ্ন বা মন্তব্য আছে যদি আমাকে জানাবেন!
৮.রিসোর্সেসঃ
ডাটা সাইন্সের কর্মপ্রবাহ এই নামের উপর ক্লিক করলে আইপাইথন ফাইলটি পেয়ে যাবেন।
Elements of Statistical Learning and Introduction to Statistical Learning are great texts that can offer more details about many of the topics I glossed over
ধন্যবাদ সবাইকে । আপনি এই সম্পর্কে কি মনে করেন আমাকে জানাতে, যদি আপনি লেখা উপভোগ করেন তাহলে শেয়ার ব্যবহার করুন ।
Happy learning.
0 comments:
Post a Comment