Abstract
বর্তমান গভীর শেখার মডেলগুলি বেশিরভাগ নিউরাল নেটওয়ার্কগুলির উপর ভিত্তি করে তৈরি করা হয়, অর্থাত্ প্যারামিটারাইজড differentiable nonlinear module গুলির একাধিক স্তর যা ব্যাকপ্রোপ্যাগেশন দ্বারা প্রশিক্ষিত হতে পারে।এই কাগজে,আমরাdifferentiable module গুলির ভিত্তিতে গভীর মডেল তৈরির সম্ভাবনাটি ঘুরে দেখি। আমরা অনুমান করি যে গভীর স্নায়বিক সাফল্যের পিছনে deep neural network গুলি তিনটি বৈশিষ্ট্য অনেক ঋণী ,অর্থাত, layer-by-layer processing, in-model feature transformation and sufficient model complexity/স্তর-দ্বারা-স্তর প্রক্রিয়াজাতকরণ, ইন-মডেল বৈশিষ্ট্যটির রূপান্তর এবং সু-মডেল জটিলতা আমরা প্রস্তাব করি gcForest পদ্ধতির ,যা এই বৈশিষ্ট্যগুলি ধারণ করে deep forest/গভীর বন তৈরি করে।এটি একটি decision tree সংগ্রহের পদ্ধতির,গভীর নিউরাল নেটওয়ার্কগুলির চেয়ে কম হাইপার-প্যারামিটার সহ,এবং এর মডেল জটিলতাটি একটি ডেটা-নির্ভর উপায়ে স্বয়ংক্রিয়ভাবে নির্ধারণ করা যায়।পরীক্ষাগুলি দেখায় যে, এর কার্যকারিতা হাইপার-প্যারামিটার সেটিংস থেকে বেশ মজবুত,যেমন বেশিরভাগ ক্ষেত্রে,এমন কি different domains গুলি থেকে different data জুড়ে,এটি একই default setting/ডিফল্ট সেটিংস ব্যবহার করে দুর্দান্ত পারফরম্যান্স পেতে সক্ষম।এই অধ্যয়নটি differentiable modules গুলির উপর ভিত্তি করে গভীর শিক্ষার দ্বার উন্মুক্ত করে,এবং ব্যাকপ্রোপেশন ব্যবহার না করেই গভীর মডেল নির্মাণের সম্ভাবনা প্রদর্শন করে।
Key words: Deep Forest, Deep Learning, Machine Learning, Ensemble Methods,
Decision Trees
1 Introduction
Deep learning [17] বিভিন্ন ডোমেনে হটওয়েভে পরিণত হয়েছে।যখন,Deep learning কি? উত্তরগুলি খুব সম্ভবত হতে পারে যে "Deep learning হ'ল deep neural networks গুলি ব্যবহার করে এমন machine learning-র একটি subfield -" [৫২]। আসলে, great arXiv:1702.08835v3 [cs.LG] 14 May 2018 ভিজ্যুয়াল এবং visual and speech গুলির সাথে জড়িত কার্যগুলিতে deep neural networks (DNNs) সাফল্য [22,30] deep learning উত্থানের দিকে পরিচালিত করে,এবং প্রায় সমস্ত বর্তমান গভীর শেখার অ্যাপ্লিকেশনগুলি নিউরাল নেটওয়ার্ক মডেলগুলিতে বা আরও প্রযুক্তিগতভাবে তৈরি করা হয়েছে,প্যারামিটারাইজড differentiable ননলাইনার মডিউলগুলির একাধিক স্তর যা ব্যাকপ্রসারণ দ্বারা প্রশিক্ষিত হতে পারে।
যদিও deep neural network গুলি শক্তিশালী, তবে তাদের অনেকগুলি শৃঙ্খলা রয়েছে।প্রথমত, DNNs গুলি অনেক বেশি hyper-parameters সহ থাকে এবং learning performance টি যত্নবান প্যারামিটার টিউনিংয়ের উপর গুরুত্ব সহকারে নির্ভর করে।প্রকৃতপক্ষে,এমনকি যখন বেশ কয়েকজন লেখক সবাই convolutional neural networks গুলি [30,34,51] ব্যবহার করেন,convolutional layer structures র মতো অনেকগুলি different এর কারণে তারা প্রকৃতপক্ষে different learning model গুলী ব্যবহার করছে।এই সত্যটি কেবল DNNs দের প্রশিক্ষণকেই খুব জটিল করে তোলে না,প্রায় science/engineering এর চেয়ে কোনও শিল্পের মতো, তবে প্রায় difficult গুরুরাল সংমিশ্রণগুলির সাথে অনেকগুলি interfering factors গুলির কারণে DNN-এর অত্যন্ত তাত্পর্যপূর্ণ তাত্ত্বিক বিশ্লেষণও।
দ্বিতীয়ত,এটি সুপরিচিত যে DNNs প্রশিক্ষণের জন্য প্রচুর পরিমাণে প্রশিক্ষণের ডেটা প্রয়োজন হয় এবং এইভাবে,যেখানে কেবলমাত্র small-scale training data রয়েছে সেখানে DNNs খুব কমই প্রয়োগ করা যেতে পারে,কখনও কখনও এমনকি মাঝারি স্কেল প্রশিক্ষণ ডেটা ব্যর্থ। নোট করুন যে এমনকি বড় ডেটা যুগে, অনেকগুলি আসল কার্যেই এখনও লেবেলযুক্ত high cost of labeling কারণে লেবেলযুক্ত ডেটা পরিমাণের labeled data due ,এই কাজগুলিতে DNNs গুলির নিকৃষ্ট কর্মক্ষমতা বাড়ে।অধিকন্তু, এটি সুপরিচিত যে neural networks গুলি black-box models গুলি যার সিদ্ধান্ত প্রক্রিয়াগুলি বোঝা শক্ত, theoretical analysis এর জন্য শিক্ষার আচরণগুলি অত্যন্ত বিচক্ষণ। তদ্ব্যতীত, প্রশিক্ষণের আগে নিউরাল neural network architecture/নেটওয়ার্ক আর্কিটেকচারটি নির্ধারণ করতে হবে,এবং এইভাবে, model complexity advance নির্ধারিত হয়।আমরা conjecture/অনুমান করি যে deep models গুলি সাধারণত প্রয়োজনের তুলনায় সাধারণত অতিরিক্ত মাত্রায় জটিল,শর্টকাট সংযোগ [20,53] যোগ করে DNN-র পারফরম্যান্স উন্নতি সম্পর্কে সম্প্রতি অনেকগুলি প্রতিবেদন রয়েছে যে পর্যবেক্ষণ দ্বারা সত্যই সম্পাদিত হয়েছে,shortcut connection [20,53], pruning [19,39], binarization [8,45], etc., কারণ এই ক্রিয়াকলাপগুলি আসল নেটওয়ার্কগুলিকে সহজতর করে এবং আসলে মডেলের জটিলতা হ্রাস করে।মডেল জটিলতা যদি কোনও ডেটা নির্ভর উপায়ে স্বয়ংক্রিয়ভাবে নির্ধারণ করা যায় তবে এটি আরও ভাল।এটি আরও লক্ষণীয় যে DNN গুলি উন্নতভাবে উন্নত করা হলেও এখনও অনেকগুলি কাজ রয়েছে যার উপর ডিএনএন উন্নত নয়,কখনও কখনও এমনকি অপর্যাপ্ত;উদাহরণস্বরূপ, Random Forest [5] or XGBoost [6] এখনও অনেকগুলি কাগল প্রতিযোগিতার কার্যক্রমে বিজয়ী।
দ্বিতীয়ত,এটি সুপরিচিত যে DNNs প্রশিক্ষণের জন্য প্রচুর পরিমাণে প্রশিক্ষণের ডেটা প্রয়োজন হয় এবং এইভাবে,যেখানে কেবলমাত্র small-scale training data রয়েছে সেখানে DNNs খুব কমই প্রয়োগ করা যেতে পারে,কখনও কখনও এমনকি মাঝারি স্কেল প্রশিক্ষণ ডেটা ব্যর্থ। নোট করুন যে এমনকি বড় ডেটা যুগে, অনেকগুলি আসল কার্যেই এখনও লেবেলযুক্ত high cost of labeling কারণে লেবেলযুক্ত ডেটা পরিমাণের labeled data due ,এই কাজগুলিতে DNNs গুলির নিকৃষ্ট কর্মক্ষমতা বাড়ে।অধিকন্তু, এটি সুপরিচিত যে neural networks গুলি black-box models গুলি যার সিদ্ধান্ত প্রক্রিয়াগুলি বোঝা শক্ত, theoretical analysis এর জন্য শিক্ষার আচরণগুলি অত্যন্ত বিচক্ষণ। তদ্ব্যতীত, প্রশিক্ষণের আগে নিউরাল neural network architecture/নেটওয়ার্ক আর্কিটেকচারটি নির্ধারণ করতে হবে,এবং এইভাবে, model complexity advance নির্ধারিত হয়।আমরা conjecture/অনুমান করি যে deep models গুলি সাধারণত প্রয়োজনের তুলনায় সাধারণত অতিরিক্ত মাত্রায় জটিল,শর্টকাট সংযোগ [20,53] যোগ করে DNN-র পারফরম্যান্স উন্নতি সম্পর্কে সম্প্রতি অনেকগুলি প্রতিবেদন রয়েছে যে পর্যবেক্ষণ দ্বারা সত্যই সম্পাদিত হয়েছে,shortcut connection [20,53], pruning [19,39], binarization [8,45], etc., কারণ এই ক্রিয়াকলাপগুলি আসল নেটওয়ার্কগুলিকে সহজতর করে এবং আসলে মডেলের জটিলতা হ্রাস করে।মডেল জটিলতা যদি কোনও ডেটা নির্ভর উপায়ে স্বয়ংক্রিয়ভাবে নির্ধারণ করা যায় তবে এটি আরও ভাল।এটি আরও লক্ষণীয় যে DNN গুলি উন্নতভাবে উন্নত করা হলেও এখনও অনেকগুলি কাজ রয়েছে যার উপর ডিএনএন উন্নত নয়,কখনও কখনও এমনকি অপর্যাপ্ত;উদাহরণস্বরূপ, Random Forest [5] or XGBoost [6] এখনও অনেকগুলি কাগল প্রতিযোগিতার কার্যক্রমে বিজয়ী।
আমরা বিশ্বাস করি যে complicated learning কাজগুলি মোকাবেলা করার জন্য, শেখার মডেলগুলি সম্ভবত আরও deep হতে হবে।Current deep models গুলি সর্বদা neural networks গুলিতে তৈরি হয়।উপরে আলোচিত হিসাবে, non-NN স্টাইলের deep models গুলি অন্বেষণ করার ভাল কারণ রয়েছে,বা অন্য কথায়,deep learning অন্যান্য মডিউলগুলির সাথে উপলব্ধি করা যায় কিনা তা বিবেচনা করা, কারণ তাদের নিজস্ব সুবিধাগুলি রয়েছে এবং গভীরভাবে যেতে সক্ষম হলে দুর্দান্ত সম্ভাবনা প্রদর্শন করতে পারে। নির্দিষ্টভাবে,নিউরাল নেটওয়ার্কগুলি প্যারামিটারাইজড differentiable nonlinear modules গুলির একাধিক স্তর হিসাবে বিবেচনা করে, যদিও world are differentiable or best modelled as differentiable , এই গবেষণাপত্রে আমরা এই মৌলিক প্রশ্নটির সমাধান করার চেষ্টা করি:
"non-differentiable modules গুলির সাহায্যে গভীর শিক্ষার উপলব্ধি করা যায় কি?"
ফলাফল যেমন অনেক গুরুত্বপূর্ণ বিষয় বুঝতে সাহায্য করতে পারে
(1) deep models ?= DNNs গুলি (বা, deep model গুলি কেবলমাত্র differentiable modules গুলি দিয়ে তৈরি করা যেতে পারে);
(২) backpropagation ছাড়াই কি deep models গুলি প্রশিক্ষণ দেওয়া সম্ভব? (backpropagation requires differentiability);
(3) deep models গুলি যে কাজগুলিতে র্যাrandom forest or XGBoost are better-র মতো এখন অন্য মডেলগুলি আরও ভাল সেগুলি কার্যকর করতে সক্ষম হওয়া সম্ভব?
আসলে,machine learning community টি প্রচুর শেখার মডিউল তৈরি করেছে, যদিও তাদের মধ্যে অনেকগুলিই non-differentiable modules গুলির ভিত্তিতে deep models গুলি তৈরি করা সম্ভব কিনা তা বোঝার ফলে এই মডিউলগুলি deep learning ক্ষেত্রে কাজে লাগানো যায় কিনা তা এই বিষয়ে আলোকপাত করবে।
এই কাগজে,আমরা আমাদের প্রাথমিক অধ্যয়নকে প্রসারিত করি [65] যা deep forest নির্মানের জন্য একটি non-NN style deep model , gcForest1 (multi-Grained Cascade Forest) পদ্ধতির প্রস্তাব দেয়। এটি একটি অভিনব decision tree ensemble ,একটি cascade structure যা বন দ্বারা প্রতিনিধিত্ব শেখার সক্ষম করে।এর representational learning ability multi-grained scanning, দ্বারা আরও বাড়ানো যেতে পারে, potentially ভাবে gcForest কে contextual or structural aware করতে সক্ষম করা। ক্যাcascade levels গুলি স্ব automatically determined করা যেতে পারে যে, model complexity প্রশিক্ষণের আগে ম্যানুয়ালি ডিজাইনের পরিবর্তে কোনও ডেটা নির্ভর নির্ভর উপায়ে নির্ধারণ করা যেতে পারে;এটি gcForest এমনকি ক্ষুদ্র-স্কেল ডেটাতেও ভালভাবে কাজ করতে সক্ষম করে এবং ব্যবহারকারীগণকে উপলব্ধ গণ্য সংস্থান অনুসারে প্রশিক্ষণ ব্যয় নিয়ন্ত্রণ করতে সক্ষম করে। অধিকন্তু, gcForest/জিসিফোরেস্টে DNN-এর চেয়ে অনেক কমhyperparameters রয়েছে। আরও ভাল খবর হ'ল hyper-parameter settings গুলি এর পারফরম্যান্স বেশ মজবুত;আমাদের পরীক্ষাগুলি দেখায় যে বেশিরভাগ ক্ষেত্রে, এটি ডিফল্ট ডোমেনগুলি থেকে different data জুড়ে এমনকি default setting ব্যবহার করে excellent performance পেতে সক্ষম।
"geek forest/গীক বন" এর মতো শোনাচ্ছে।
The rest of this paper is organized as follows.
Section 2 explains our design motivations by analyzing why deep learning works.
Section 3 proposes our approach,
followed by experiments reported in Section 4.
Section 5 discusses on some related work.
Section 6 raises some issues for future exploration, followed by concluding remarks in Section 7.
2 Inspiration
2.1 Inspiration from DNNs
এটি widely recognized/ব্যাপকভাবে স্বীকৃত যে deep neural networks গুলির সাফল্যের জন্য উপস্থাপনা শেখার ক্ষমতা অত্যন্ত গুরুত্বপূর্ণ। DNN- তে representation learning/প্রতিনিধিত্বমূলক শিক্ষার জন্য কী গুরুত্বপূর্ণ? আমরা বিশ্বাস করি যে উত্তরটি স্তর-দ্বারা-স্তর প্রক্রিয়াজাতকরণ। চিত্র 1 একটি চিত্র সরবরাহ করে, স্তরটি নীচ থেকে উপরে উঠার সাথে সাথে উচ্চ স্তরের abstractএর features গুলি প্রকাশিত হয়।

Fig. 1. Illustration of the layer-by-layer processing in deep neural networks: Features of
higher levels of abstract emerge as the layer goes up from the bottom. Simulated from a
figure in [17].
Considering করে যে অন্যান্য সমস্যাগুলি যদি এক্সড হয়, তবে বড় মডেলের জটিলতা (or more accurately, model capacity) সাধারণত শক্তিশালী learning ability র দিকে পরিচালিত করে, DNNs গুলির সাফল্যকে বিশাল মডেলের জটিলতায় দায়ী করা যুক্তিসঙ্গত বলে মনে হয়। এটি তবে এই সত্যটি ব্যাখ্যা করতে পারে না যে অগভীর নেটওয়ার্কগুলি কেন গভীর নেটওয়ার্কগুলির মতো সফল হয় না, যেহেতু কেউ hidden units এর প্রায় infinite number যোগ করে shallow networks গুলির জটিলতা বাড়িয়ে তুলতে পারে। সুতরাং, আমরা বিশ্বাস করি যে মডেল জটিলতা নিজেই ডিএনএনগুলির সাফল্য ব্যাখ্যা করতে পারে না। পরিবর্তে, আমরা অনুমান করি যে স্তর-দ্বারা-স্তর প্রক্রিয়াকরণ ডিএনএনগুলির পিছনে অন্যতম গুরুত্বপূর্ণ কারণ, কারণ networks নেটওয়ার্কগুলিতে (যেমন, এsingle-hidden-layer networks), তাদের জটিলতা যত বড় হতে পারে তা বিবেচনা করুন, স্তর-দ্বারা-স্তর প্রক্রিয়াজাতকরণের বৈশিষ্ট্যগুলি ধরে রাখবেন না। যদিও আমাদের কাছে এখনও কোনও কঠোর ন্যায্যতা নেই,এই অনুমান ও gcForest.
ডিজাইনের জন্য একটি গুরুত্বপূর্ণ অনুপ্রেরণা
কেউ প্রশ্ন করতে পারে যে এখানে শেখার মডেল রয়েছে,উদাহরণস্বরূপ, decision trees and Boosting machines ,যা layer-by-layer processing পরিচালনা করে,কেন তারা DNN -এর মতো সফল নয়?আমরা বিশ্বাস করি যে সবচেয়ে গুরুত্বপূর্ণ পার্থক্যকারী কারণটি হ'ল,DNN-এর বিপরীতে যেখানে চিত্র 1-এ বর্ণিত হিসাবে নতুন বৈশিষ্ট্য তৈরি করা হয়েছে, শিখার প্রক্রিয়া চলাকালীন নতুন বৈশিষ্ট্য তৈরি না করে decision trees এবং Boosting machines গুলি সর্বদা আসল বৈশিষ্ট্য উপস্থাপনায় কাজ করে বা অন্য কথায়, কোনও মডেল বৈশিষ্ট্য রূপান্তর হয় না।তদুপরি, DNN গুলির বিপরীতে যা নির্বিচারে উচ্চ মডেলের জটিলতায় ভোগ করা যায়,সিদ্ধান্ত গাছ এবং বুস্টিং মেশিনগুলির মধ্যে কেবলমাত্র সীমিত মডেলের জটিলতা থাকতে পারে।যদিও মডেল জটিলতা নিজেই DNN গুলির সাফল্য ব্যাখ্যা করে না,এটি এখনও গুরুত্বপূর্ণ কারণ বড় প্রশিক্ষণের ডেটা শোষণের জন্য বৃহত মডেলের সক্ষমতা প্রয়োজন।সামগ্রিকভাবে, আমরা অনুমান করি যে ডিএনএনগুলির রহস্যের পিছনে তিনটি গুরুত্বপূর্ণ বৈশিষ্ট্য রয়েছে,অর্থাত, layer-by-layer processing,
in-model feature transformation,
and sufficient model complexity। আমরা এই বৈশিষ্ট্যগুলিকে আমাদের nonNN style deep model-র কাছে রেখে দেওয়ার চেষ্টা করব।
2.2 Inspiration from Ensemble Learning
Ensemble learning [63]/এনসেম্বেল লার্নিং হ'ল একটি মেশিন লার্নিং দৃষ্টান্ত যেখানে multiple learners (e.g., classifiers) প্রশিক্ষণের জন্য এবং কোনও কাজের জন্য সম্মিলিত। এটি সুপরিচিত যে একটি উপহার সাধারণত single learners.-র চেয়ে আরও generalization performance অর্জন করতে পারে।
একটি ভাল ছাঁটাই তৈরি করতে, পৃথক শিক্ষার্থীদের accurate and diverse হওয়া উচিত।কেবলমাত্র accurate learner-র সংমিশ্রণ হ'ল কিছু তুলনামূলকভাবে দুর্বল -র সাথে কিছু নির্ভুল learners গুলি একত্রিত করার জন্য inferior/নিকৃষ্ট হয়,কারণ পরিপূরক বিশুদ্ধ নির্ভুলতার চেয়ে গুরুত্বপূর্ণ। আসলে, একটি সুন্দর সমীকরণ theoretically ভাবে error-ambiguity decomposition থেকে উদ্ভূত হয়েছে [32]:
E = ¯ E − ¯ A , ...................................................।(১)
যেখানে, E একটি ensemble-র error টি denotes/চিহ্নিত করে,¯ E সমবেত ক্ষেত্রে individual classifiers-র error এর average error টি চিহ্নিত করে এবং ¯A denotes একটি average ambiguity/গড় অস্পষ্টতা বোঝায় যা পরবর্তীতে individual classifiers-র মধ্যে diversity/বৈচিত্র নামে পরিচিত। Eq (1) প্রকাশ করে যে, পৃথক শ্রেণিবদ্ধদের আরও নিখুঁত ও তত বেশি বৈচিত্র্যময় সমবেত করা ভাল। এটি ensemble নির্মাণের জন্য একটি সাধারণ দিকনির্দেশনা; তবে এটি অপ্টিমাইজেশনের জন্য একটি উদ্দেশ্যমূলক কাজ হিসাবে গ্রহণ করা যায়নি, কারণ অস্পষ্টতা শব্দটি গাণিতিকভাবে ডেরিকডে অবতীর্ণ এবং সরাসরি পরিচালনা করা যায় না [32]। পরবর্তীতে, ensemble community প্রচুর পরিমাণে diversity measures-র নকশা করেছে তবে বৈচিত্র্যের জন্য সঠিক পরিবেশ হিসাবে [9,33] কোনওটিকেই গ্রহণ করা হয়নি। প্রকৃতপক্ষে, "what is diversityবৈচিত্র্য কী?" ensemble learning ক্ষেত্রে holy grail problem হিসাবে রয়ে গেছে এবং কিছু সাম্প্রতিক effort [54,67] এ পাওয়া যাবে।
In practice, diversity বৃদ্ধির প্রাথমিক কৌশলটি প্রশিক্ষণ প্রক্রিয়া চলাকালীন কিছু heuristics/হিউরিস্টিকের ভিত্তিতে randomness based ভাবে ইনজেকশন করা। Roughly speaking/মোটামুটিভাবে বলতে গেলে, চারটি প্রধান শ্রেণির প্রক্রিয়া রয়েছে [63]। প্রথমটি হ'ল ডেটা স্যাম্পল ম্যানিপুলেশন, যা পৃথক শিখর প্রশিক্ষকদের প্রশিক্ষণ দিতে ডিআরেন্ট ডেটা নমুনা তৈরি করে কাজ করে। উদাহরণস্বরূপ, bootstrap sampling [12]] exploited by Bagging [2]] দ্বারা শোষণ করা হয়েছে, অন্যদিকে ক্রমবর্ধমান গুরুত্বের নমুনা AdaBoost/অ্যাডাবুস্ট দ্বারা গৃহীত হয়েছে [14]। দ্বিতীয়টি হ'ল input feature manipulation, যা individual learner প্রশিক্ষকদের প্রশিক্ষণের জন্য ডায়ারেন্ট বৈশিষ্ট্য উপ-স্থান তৈরি করে কাজ করে। উদাহরণস্বরূপ, র্যান্ডম সাবস্পেস পদ্ধতির [24] এলোমেলোভাবে প্রতিটি পৃথক শিক্ষার্থীর জন্য বৈশিষ্ট্যগুলির একটি উপসেট বেছে নিয়েছে। তৃতীয়টি হ'ল প্যারামিটার ম্যানিপুলেশন শিখছে, যা বিভিন্ন পৃথক শিক্ষার্থী তৈরি করতে বেস লার্নিং অ্যালগরিদমের ডিয়ারেন্ট প্যারামিটার সেটিংস ব্যবহার করে কাজ করে। উদাহরণস্বরূপ, ডিআরেন্ট প্রাথমিক ওজন স্বতন্ত্র নিউরাল নেটওয়ার্কগুলির জন্য ব্যবহার করা যেতে পারে [২৮], অন্যদিকে different বিভাজন নির্বাচন পৃথক সিদ্ধান্তের গাছগুলিতে প্রয়োগ করা যেতে পারে [ 37] চতুর্থটি আউটপুট প্রতিনিধিত্বমূলক ম্যানিপুলেশন, যা বিভিন্ন স্বতন্ত্র শিক্ষানবিশকে জেনারেট করার জন্য different আউটপুট উপস্থাপনা ব্যবহার করে কাজ করে। উদাহরণস্বরূপ, ECOC পদ্ধতির [10] নিয়োগ করে
অনুশীলনে, বৈচিত্র্য বৃদ্ধির প্রাথমিক কৌশলটি প্রশিক্ষণ প্রক্রিয়া চলাকালীন কিছু হিউরিস্টিকের ভিত্তিতে এলোমেলোভাবে ইনজেকশন করা। মোটামুটিভাবে বলতে গেলে, চারটি প্রধান শ্রেণির প্রক্রিয়া রয়েছে [63৩]। প্রথমটি হ'ল ডেটা স্যাম্পল ম্যানিপুলেশন, যা পৃথক শিখর প্রশিক্ষকদের প্রশিক্ষণ দিতে ডিআরেন্ট ডেটা নমুনা তৈরি করে কাজ করে। উদাহরণস্বরূপ, বুটস্ট্র্যাপের নমুনা [12] ব্যাগিং [2] দ্বারা শোষণ করা হয়েছে, অন্যদিকে ক্রমবর্ধমান গুরুত্বের নমুনা অ্যাডাবুস্ট দ্বারা গৃহীত হয়েছে [14]। দ্বিতীয়টি হ'ল ইনপুট বৈশিষ্ট্য ম্যানিপুলেশন, যা পৃথক শিখর প্রশিক্ষকদের প্রশিক্ষণের জন্য ডায়ারেন্ট বৈশিষ্ট্য উপ-স্থান তৈরি করে কাজ করে। উদাহরণস্বরূপ, র্যান্ডম সাবস্পেস পদ্ধতির [24] এলোমেলোভাবে প্রতিটি পৃথক শিক্ষার্থীর জন্য বৈশিষ্ট্যগুলির একটি উপসেট বেছে নিয়েছে। তৃতীয়টি হ'ল প্যারামিটার ম্যানিপুলেশন শিখছে, যা বিভিন্ন পৃথক শিক্ষার্থী তৈরি করতে বেস লার্নিং অ্যালগরিদমের ডিয়ারেন্ট প্যারামিটার সেটিংস ব্যবহার করে কাজ করে। উদাহরণস্বরূপ, ডিআরেন্ট প্রাথমিক ওজন স্বতন্ত্র নিউরাল নেটওয়ার্কগুলির জন্য ব্যবহার করা যেতে পারে [২৮], অন্যদিকে ডি-এ্যারেন্ট বিভাজন নির্বাচন পৃথক সিদ্ধান্তের গাছগুলিতে প্রয়োগ করা যেতে পারে [৩ 37]চতুর্থটি আউটপুট প্রতিনিধিত্বমূলক ম্যানিপুলেশন, যা বিভিন্ন স্বতন্ত্র শিক্ষানবিশকে জেনারেট করার জন্য ডায়ারেন্ট আউটপুট উপস্থাপনা ব্যবহার করে কাজ করে। উদাহরণস্বরূপ, ECOC পদ্ধতির [10] আউটপুট কোডগুলি ত্রুটি-সংশোধনকারী নিয়োগ করে, যেখানে Flipping Output method [4] randomly ভাবে কিছু প্রশিক্ষণের উদাহরণগুলির লেবেলগুলিকে পরিবর্তন করে। Different mechanisms পদ্ধতিগুলি একসাথে ব্যবহার করা যেতে পারে, যেমন, [5,68] Note that, however, যে তবে এই পদ্ধতিগুলি সবসময় কার্যকর হয় না। উদাহরণস্বরূপ, ECOC পদ্ধতির [10] আউটপুট কোডগুলি ত্রুটি-সংশোধনকারী নিয়োগ করে, যেখানে Flipping Output method [4] randomly ভাবে কিছু প্রশিক্ষণের উদাহরণগুলির লেবেলগুলিকে পরিবর্তন করে। Different mechanisms পদ্ধতিগুলি একসাথে ব্যবহার করা যেতে পারে, যেমন, [5,68] Note that, however, যে তবে এই পদ্ধতিগুলি সবসময় কার্যকর হয় না। উদাহরণস্বরূপ, data sample manipulation স্থিতিশীল শিখার সাথে ভাল কাজ করে না যার দক্ষতা প্রশিক্ষণ ডেটার সামান্য মোডিফিকেশন অনুসারে পরিবর্তিত হয়। ensemble শেখার সম্পর্কে আরও তথ্য [63] এ পাওয়া যাবে।
Next section টি gcForest introduce করবে, যা প্রায়শই সমস্ত শ্রেণীর বিভিন্নতা mechanisms/বৃদ্ধির জন্য utilizes/ব্যবস্থাকে কাজে লাগিয়ে এমন একটি decision tree ensemble পদ্ধতিরূপ হিসাবে দেখা যেতে পারে।
3 The gcForest Approach
এই বিভাগে আমরা প্রথমে cascade forest structure এবং তারপরে multi-grained scanning প্রবর্তন করব, এর পরে সামগ্রিক আর্কিটেকচার এবং হাইপারপ্যারামিটারে মন্তব্য করব।
3.1 Cascade Forest Structure
গভীর নিউরাল নেটওয়ার্কগুলিতে Representation learning বেশিরভাগ raw features গুলির layer-by-layer processing উপর নির্ভর করে। এই স্বীকৃতি দ্বারা অনুপ্রাণিত হয়ে, gcForest একটি cascade কাঠামো নিযুক্ত করে, যেমন চিত্র 2 তে চিত্রিত হয়েছে, যেখানে ক্যাসকেডের প্রতিটি স্তর তার পূর্ববর্তী স্তর দ্বারা প্রক্রিয়াজাত বৈশিষ্ট্য সম্পর্কিত তথ্য গ্রহণ করে এবং এর প্রসেসিং ফলাফলটিকে পরবর্তী স্তরে আউটপুট করে।
প্রতিটি স্তর decision tree forests-র একটি উপহার,অর্থাত্ ensemble of ensembles ।বৈচিত্র্যকে উত্সাহিত করার জন্য আমরা এখানে বিভিন্ন ধরণের বন অন্তর্ভুক্ত করেছি, কারণ ensemble construction-র জন্য বৈচিত্র্য অত্যন্ত গুরুত্বপূর্ণ [63]।For simplicity, ধরুন যে আমরা two completely-random tree forests/দুটি সম্পূর্ণ এলোমেলো গাছের বন এবং two random forests/দুটি এলোমেলো বন ব্যবহার করি [5]।প্রতিটি সম্পূর্ণরূপে গাছের বনটিতে 500 টি সম্পূর্ণ-এলোমেলো গাছ থাকে [37],এলোমেলোভাবে গাছের প্রতিটি নোডে বিভাজনের জন্য একটি বৈশিষ্ট্য নির্বাচন করে উত্পন্ন,এবং শুকনো পাতা অবধি গাছ বাড়ছে, অর্থাত্ প্রতিটি পাত নোডে কেবল একই শ্রেণীর উদাহরণ রয়েছে।
√d প্রার্থী হিসাবে এলোমেলোভাবে featuresd নির্বাচন করে (d is the number of input features) এবং বিভাজনের জন্য সেরা জিনির মান সহ একটি নির্বাচন করে। প্রতিটি বনে গাছের সংখ্যা একটি হাইপার-প্যারামিটার, যা বিভাগ 3.3 এ আলোচনা করা হবে।

চিত্র 2. ক্যাসকেড বন কাঠামোর চিত্র। ধরুন ক্যাসকেডের প্রতিটি স্তরদুটি এলোমেলো বন (কালো) এবং দুটি সম্পূর্ণ-এলোমেলো গাছের বন (নীল) নিয়ে গঠিত।ধরুন ভবিষ্যদ্বাণী করার জন্য এখানে তিনটি শ্রেণি রয়েছে; সুতরাং, প্রতিটি বন একটি ত্রিমাত্রিক আউটপুট হবে sional class vector/ সিওনাল শ্রেণীর ভেক্টর, যা মূল ইনপুটটির re-representation/পুনঃ-উপস্থাপনের জন্য সংযুক্ত হয়।
উদাহরণস্বরূপ, প্রতিটি বন শ্রেণীর distribution-র একটি estimate তৈরি করবে, যেখানে leaf node সংশ্লিষ্ট উদাহরণটি পড়ে সেখানে প্রশিক্ষণের উদাহরণগুলির different classes-র percentage/শতাংশ গণনা করে, এবং একই বনের সমস্ত গাছ জুড়ে গড়ে চিত্র নেওয়া হবে চিত্র 3 3 , যেখানে লাল রঙগুলি সেই পথগুলিকে হাইলাইট করে যেখানে উদাহরণটি leaf nodes গুলিতে চলে।
The estimated class distribution forms a class vector, which is then concatenated with the original feature vector to be input to the next level of cascade. For example,

Fig. 3. Illustration of class vector generation. Different marks in leaf nodes imply different
classes.
suppose there are three classes, then each of the four forests will produce a threedimensional class vector; thus, the next level of cascade will receive 12 (= 3×4) augmented features.
overfitting র ঝুঁকি কমাতে, প্রতিটি বন দ্বারা উত্পাদিত শ্রেণি ভেক্টর k-fold cross validation র দ্বারা উত্পন্ন হয়। বিশদভাবে, প্রতিটি উদাহরণ k − 1 বারের জন্য প্রশিক্ষণ ডেটা হিসাবে ব্যবহৃত হবে, ফলস্বরূপ k − 1 শ্রেণীর ভেক্টর, যার পরে গড় স্তরের ক্যাসকেডের পরবর্তী স্তরের উন্নত বৈশিষ্ট্য হিসাবে শ্রেণীর ভেক্টর উত্পাদন করতে হবে। একটি নতুন স্তর প্রসারণের পরে, পুরো ক্যাসকেডের পারফরম্যান্সটি বৈধতা সেট অনুসারে অনুমান করা যেতে পারে, এবং যদি কোনও চিহ্ন-ক্যান্ট পারফরম্যান্স লাভ না হয় তবে প্রশিক্ষণ পদ্ধতিটি সমাপ্ত হবে; সুতরাং, ক্যাসকেড স্তরের সংখ্যা স্বয়ংক্রিয়ভাবে নির্ধারিত হয়। নোট করুন যে ক্রস বৈধকরণের ত্রুটির পরিবর্তে প্রশিক্ষণের ত্রুটি ক্যাসকেড বৃদ্ধি নিয়ন্ত্রণ করতে ব্যবহার করা যেতে পারে যখন প্রশিক্ষণের ব্যয়টি সম্পর্কিত হয় বা সীমাবদ্ধ গণনার উত্স উপলব্ধ থাকে। বেশিরভাগ গভীর নিউরাল নেটওয়ার্কগুলির বিপরীতে যার মডেল জটিলতা হয়, পর্যাপ্ত পর্যায়ে যখন প্রশিক্ষণ বন্ধ করে gcForest adaptively decides ভাবে তার মডেল জটিলতা সিদ্ধান্ত নেয়। এটি এটিকে প্রশিক্ষণের ডেটাগুলির different scales গুলির ক্ষেত্রে প্রযোজ্য করতে সক্ষম করে, বৃহত্তর স্কেলগুলির মধ্যে সীমাবদ্ধ নয়।
3.2 Multi-Grained Scanning
গভীর স্নায়ুবহুল নেটওয়ার্কগুলি বৈশিষ্ট্য সম্পর্কগুলি পরিচালনা করতে শক্তিশালী, যেমন, কনভোলশনাল নিউরাল নেটওয়ার্কগুলি চিত্রের ডেটাগুলিতে effective যেখানে raw pixelsর মধ্যে স্থানিক সম্পর্ক critica [30,34]; পুনরাবৃত্ত নিউরাল নেটওয়ার্কগুলি সিক্যুয়েন্স ডেটাতে effective যেখানে sequence data সম্পর্কের সমালোচনা [7,18]। এই স্বীকৃতি দ্বারা অনুপ্রাণিত হয়ে আমরা multi-grained scanning র একটি পদ্ধতি দিয়ে ক্যাসকেড বনকে বাড়িয়ে তুলি

Fig. 4. Illustration of feature re-representation using sliding window scanning. Suppose there are three classes, raw features are 400-dim, and sliding window is 100-dim.
চিত্র 4 চিত্রিত হিসাবে,sliding window গুলি raw features গুলি স্ক্যান করতে ব্যবহৃত হয়। ধরুন এখানে 400 টি raw features রয়েছে এবং 100 টি features-র উইন্ডো আকার ব্যবহার করা হয়েছে।sequence data র জন্য, একটি বৈশিষ্ট্যের জন্যwindow টি স্লাইড করে একটি 100-dimensional feature vector তৈরি করা হবে; মোট 301 feature vectors are produced হয়।যদি raw features গুলি spacial relationships-র সাথে থাকে, যেমন 400 ইমেজ পিক্সেলের 20 × 20 প্যানেল, তবে 10 × 10 উইন্ডো 121 feature vectors তৈরি করবে (যেমন, 121 10 × 10 প্যানেল)।ইতিবাচক / নেতিবাচক প্রশিক্ষণের উদাহরণ থেকে প্রাপ্ত সমস্ত বৈশিষ্ট্য ভেক্টরকে positive/negative training উদাহরণ হিসাবে বিবেচনা করা হয়,যা Section 3.1 এর মতো ক্লাস ভেক্টর তৈরি করতে ব্যবহৃত হবে: একই আকারের উইন্ডোজ থেকে প্রাপ্ত উদাহরণগুলি সম্পূর্ণরূপে এলোমেলো গাছের বন এবং একটি এলোমেলো বন প্রশিক্ষণের জন্য ব্যবহৃত হবে এবং তারপরে generate class vectors/শ্রেণি ভেক্টরগুলি রূপান্তরিত হিসাবে উত্পন্ন এবং সংমিশ্রিত করা হবে বৈশিষ্ট্যগুলিও উপস্থিত রয়েছে।চিত্র 4 চিত্রিত হিসাবে, মনে করুন যে এখানে 3 টি শ্রেণি রয়েছে এবং একটি 100-মাত্রিক উইন্ডো ব্যবহৃত হয়েছে; তারপরে, প্রতিটি বন দ্বারা 301 ত্রিমাত্রিক শ্রেণীর ভেক্টর উত্পাদিত হয়, যার ফলে 1,006-dimensional transformed feature vector টি মূল 400 dimensional raw feature vector-র সাথে মিলিত হয়।
"non-differentiable modules গুলির সাহায্যে গভীর শিক্ষার উপলব্ধি করা যায় কি?"
ফলাফল যেমন অনেক গুরুত্বপূর্ণ বিষয় বুঝতে সাহায্য করতে পারে
(1) deep models ?= DNNs গুলি (বা, deep model গুলি কেবলমাত্র differentiable modules গুলি দিয়ে তৈরি করা যেতে পারে);
(২) backpropagation ছাড়াই কি deep models গুলি প্রশিক্ষণ দেওয়া সম্ভব? (backpropagation requires differentiability);
(3) deep models গুলি যে কাজগুলিতে র্যাrandom forest or XGBoost are better-র মতো এখন অন্য মডেলগুলি আরও ভাল সেগুলি কার্যকর করতে সক্ষম হওয়া সম্ভব?
আসলে,machine learning community টি প্রচুর শেখার মডিউল তৈরি করেছে, যদিও তাদের মধ্যে অনেকগুলিই non-differentiable modules গুলির ভিত্তিতে deep models গুলি তৈরি করা সম্ভব কিনা তা বোঝার ফলে এই মডিউলগুলি deep learning ক্ষেত্রে কাজে লাগানো যায় কিনা তা এই বিষয়ে আলোকপাত করবে।
এই কাগজে,আমরা আমাদের প্রাথমিক অধ্যয়নকে প্রসারিত করি [65] যা deep forest নির্মানের জন্য একটি non-NN style deep model , gcForest1 (multi-Grained Cascade Forest) পদ্ধতির প্রস্তাব দেয়। এটি একটি অভিনব decision tree ensemble ,একটি cascade structure যা বন দ্বারা প্রতিনিধিত্ব শেখার সক্ষম করে।এর representational learning ability multi-grained scanning, দ্বারা আরও বাড়ানো যেতে পারে, potentially ভাবে gcForest কে contextual or structural aware করতে সক্ষম করা। ক্যাcascade levels গুলি স্ব automatically determined করা যেতে পারে যে, model complexity প্রশিক্ষণের আগে ম্যানুয়ালি ডিজাইনের পরিবর্তে কোনও ডেটা নির্ভর নির্ভর উপায়ে নির্ধারণ করা যেতে পারে;এটি gcForest এমনকি ক্ষুদ্র-স্কেল ডেটাতেও ভালভাবে কাজ করতে সক্ষম করে এবং ব্যবহারকারীগণকে উপলব্ধ গণ্য সংস্থান অনুসারে প্রশিক্ষণ ব্যয় নিয়ন্ত্রণ করতে সক্ষম করে। অধিকন্তু, gcForest/জিসিফোরেস্টে DNN-এর চেয়ে অনেক কমhyperparameters রয়েছে। আরও ভাল খবর হ'ল hyper-parameter settings গুলি এর পারফরম্যান্স বেশ মজবুত;আমাদের পরীক্ষাগুলি দেখায় যে বেশিরভাগ ক্ষেত্রে, এটি ডিফল্ট ডোমেনগুলি থেকে different data জুড়ে এমনকি default setting ব্যবহার করে excellent performance পেতে সক্ষম।
"geek forest/গীক বন" এর মতো শোনাচ্ছে।
The rest of this paper is organized as follows.
Section 2 explains our design motivations by analyzing why deep learning works.
Section 3 proposes our approach,
followed by experiments reported in Section 4.
Section 5 discusses on some related work.
Section 6 raises some issues for future exploration, followed by concluding remarks in Section 7.
2.1 Inspiration from DNNs
Fig. 1. Illustration of the layer-by-layer processing in deep neural networks: Features of
higher levels of abstract emerge as the layer goes up from the bottom. Simulated from a
figure in [17].
Considering করে যে অন্যান্য সমস্যাগুলি যদি এক্সড হয়, তবে বড় মডেলের জটিলতা (or more accurately, model capacity) সাধারণত শক্তিশালী learning ability র দিকে পরিচালিত করে, DNNs গুলির সাফল্যকে বিশাল মডেলের জটিলতায় দায়ী করা যুক্তিসঙ্গত বলে মনে হয়। এটি তবে এই সত্যটি ব্যাখ্যা করতে পারে না যে অগভীর নেটওয়ার্কগুলি কেন গভীর নেটওয়ার্কগুলির মতো সফল হয় না, যেহেতু কেউ hidden units এর প্রায় infinite number যোগ করে shallow networks গুলির জটিলতা বাড়িয়ে তুলতে পারে। সুতরাং, আমরা বিশ্বাস করি যে মডেল জটিলতা নিজেই ডিএনএনগুলির সাফল্য ব্যাখ্যা করতে পারে না। পরিবর্তে, আমরা অনুমান করি যে স্তর-দ্বারা-স্তর প্রক্রিয়াকরণ ডিএনএনগুলির পিছনে অন্যতম গুরুত্বপূর্ণ কারণ, কারণ networks নেটওয়ার্কগুলিতে (যেমন, এsingle-hidden-layer networks), তাদের জটিলতা যত বড় হতে পারে তা বিবেচনা করুন, স্তর-দ্বারা-স্তর প্রক্রিয়াজাতকরণের বৈশিষ্ট্যগুলি ধরে রাখবেন না। যদিও আমাদের কাছে এখনও কোনও কঠোর ন্যায্যতা নেই,এই অনুমান ও gcForest.
ডিজাইনের জন্য একটি গুরুত্বপূর্ণ অনুপ্রেরণা
কেউ প্রশ্ন করতে পারে যে এখানে শেখার মডেল রয়েছে,উদাহরণস্বরূপ, decision trees and Boosting machines ,যা layer-by-layer processing পরিচালনা করে,কেন তারা DNN -এর মতো সফল নয়?আমরা বিশ্বাস করি যে সবচেয়ে গুরুত্বপূর্ণ পার্থক্যকারী কারণটি হ'ল,DNN-এর বিপরীতে যেখানে চিত্র 1-এ বর্ণিত হিসাবে নতুন বৈশিষ্ট্য তৈরি করা হয়েছে, শিখার প্রক্রিয়া চলাকালীন নতুন বৈশিষ্ট্য তৈরি না করে decision trees এবং Boosting machines গুলি সর্বদা আসল বৈশিষ্ট্য উপস্থাপনায় কাজ করে বা অন্য কথায়, কোনও মডেল বৈশিষ্ট্য রূপান্তর হয় না।তদুপরি, DNN গুলির বিপরীতে যা নির্বিচারে উচ্চ মডেলের জটিলতায় ভোগ করা যায়,সিদ্ধান্ত গাছ এবং বুস্টিং মেশিনগুলির মধ্যে কেবলমাত্র সীমিত মডেলের জটিলতা থাকতে পারে।যদিও মডেল জটিলতা নিজেই DNN গুলির সাফল্য ব্যাখ্যা করে না,এটি এখনও গুরুত্বপূর্ণ কারণ বড় প্রশিক্ষণের ডেটা শোষণের জন্য বৃহত মডেলের সক্ষমতা প্রয়োজন।সামগ্রিকভাবে, আমরা অনুমান করি যে ডিএনএনগুলির রহস্যের পিছনে তিনটি গুরুত্বপূর্ণ বৈশিষ্ট্য রয়েছে,অর্থাত, layer-by-layer processing,
in-model feature transformation,
and sufficient model complexity। আমরা এই বৈশিষ্ট্যগুলিকে আমাদের nonNN style deep model-র কাছে রেখে দেওয়ার চেষ্টা করব।
2.2 Inspiration from Ensemble Learning
Ensemble learning [63]/এনসেম্বেল লার্নিং হ'ল একটি মেশিন লার্নিং দৃষ্টান্ত যেখানে multiple learners (e.g., classifiers) প্রশিক্ষণের জন্য এবং কোনও কাজের জন্য সম্মিলিত। এটি সুপরিচিত যে একটি উপহার সাধারণত single learners.-র চেয়ে আরও generalization performance অর্জন করতে পারে।
একটি ভাল ছাঁটাই তৈরি করতে, পৃথক শিক্ষার্থীদের accurate and diverse হওয়া উচিত।কেবলমাত্র accurate learner-র সংমিশ্রণ হ'ল কিছু তুলনামূলকভাবে দুর্বল -র সাথে কিছু নির্ভুল learners গুলি একত্রিত করার জন্য inferior/নিকৃষ্ট হয়,কারণ পরিপূরক বিশুদ্ধ নির্ভুলতার চেয়ে গুরুত্বপূর্ণ। আসলে, একটি সুন্দর সমীকরণ theoretically ভাবে error-ambiguity decomposition থেকে উদ্ভূত হয়েছে [32]:
E = ¯ E − ¯ A , ...................................................।(১)
যেখানে, E একটি ensemble-র error টি denotes/চিহ্নিত করে,¯ E সমবেত ক্ষেত্রে individual classifiers-র error এর average error টি চিহ্নিত করে এবং ¯A denotes একটি average ambiguity/গড় অস্পষ্টতা বোঝায় যা পরবর্তীতে individual classifiers-র মধ্যে diversity/বৈচিত্র নামে পরিচিত। Eq (1) প্রকাশ করে যে, পৃথক শ্রেণিবদ্ধদের আরও নিখুঁত ও তত বেশি বৈচিত্র্যময় সমবেত করা ভাল। এটি ensemble নির্মাণের জন্য একটি সাধারণ দিকনির্দেশনা; তবে এটি অপ্টিমাইজেশনের জন্য একটি উদ্দেশ্যমূলক কাজ হিসাবে গ্রহণ করা যায়নি, কারণ অস্পষ্টতা শব্দটি গাণিতিকভাবে ডেরিকডে অবতীর্ণ এবং সরাসরি পরিচালনা করা যায় না [32]। পরবর্তীতে, ensemble community প্রচুর পরিমাণে diversity measures-র নকশা করেছে তবে বৈচিত্র্যের জন্য সঠিক পরিবেশ হিসাবে [9,33] কোনওটিকেই গ্রহণ করা হয়নি। প্রকৃতপক্ষে, "what is diversityবৈচিত্র্য কী?" ensemble learning ক্ষেত্রে holy grail problem হিসাবে রয়ে গেছে এবং কিছু সাম্প্রতিক effort [54,67] এ পাওয়া যাবে।
In practice, diversity বৃদ্ধির প্রাথমিক কৌশলটি প্রশিক্ষণ প্রক্রিয়া চলাকালীন কিছু heuristics/হিউরিস্টিকের ভিত্তিতে randomness based ভাবে ইনজেকশন করা। Roughly speaking/মোটামুটিভাবে বলতে গেলে, চারটি প্রধান শ্রেণির প্রক্রিয়া রয়েছে [63]। প্রথমটি হ'ল ডেটা স্যাম্পল ম্যানিপুলেশন, যা পৃথক শিখর প্রশিক্ষকদের প্রশিক্ষণ দিতে ডিআরেন্ট ডেটা নমুনা তৈরি করে কাজ করে। উদাহরণস্বরূপ, bootstrap sampling [12]] exploited by Bagging [2]] দ্বারা শোষণ করা হয়েছে, অন্যদিকে ক্রমবর্ধমান গুরুত্বের নমুনা AdaBoost/অ্যাডাবুস্ট দ্বারা গৃহীত হয়েছে [14]। দ্বিতীয়টি হ'ল input feature manipulation, যা individual learner প্রশিক্ষকদের প্রশিক্ষণের জন্য ডায়ারেন্ট বৈশিষ্ট্য উপ-স্থান তৈরি করে কাজ করে। উদাহরণস্বরূপ, র্যান্ডম সাবস্পেস পদ্ধতির [24] এলোমেলোভাবে প্রতিটি পৃথক শিক্ষার্থীর জন্য বৈশিষ্ট্যগুলির একটি উপসেট বেছে নিয়েছে। তৃতীয়টি হ'ল প্যারামিটার ম্যানিপুলেশন শিখছে, যা বিভিন্ন পৃথক শিক্ষার্থী তৈরি করতে বেস লার্নিং অ্যালগরিদমের ডিয়ারেন্ট প্যারামিটার সেটিংস ব্যবহার করে কাজ করে। উদাহরণস্বরূপ, ডিআরেন্ট প্রাথমিক ওজন স্বতন্ত্র নিউরাল নেটওয়ার্কগুলির জন্য ব্যবহার করা যেতে পারে [২৮], অন্যদিকে different বিভাজন নির্বাচন পৃথক সিদ্ধান্তের গাছগুলিতে প্রয়োগ করা যেতে পারে [ 37] চতুর্থটি আউটপুট প্রতিনিধিত্বমূলক ম্যানিপুলেশন, যা বিভিন্ন স্বতন্ত্র শিক্ষানবিশকে জেনারেট করার জন্য different আউটপুট উপস্থাপনা ব্যবহার করে কাজ করে। উদাহরণস্বরূপ, ECOC পদ্ধতির [10] নিয়োগ করে
অনুশীলনে, বৈচিত্র্য বৃদ্ধির প্রাথমিক কৌশলটি প্রশিক্ষণ প্রক্রিয়া চলাকালীন কিছু হিউরিস্টিকের ভিত্তিতে এলোমেলোভাবে ইনজেকশন করা। মোটামুটিভাবে বলতে গেলে, চারটি প্রধান শ্রেণির প্রক্রিয়া রয়েছে [63৩]। প্রথমটি হ'ল ডেটা স্যাম্পল ম্যানিপুলেশন, যা পৃথক শিখর প্রশিক্ষকদের প্রশিক্ষণ দিতে ডিআরেন্ট ডেটা নমুনা তৈরি করে কাজ করে। উদাহরণস্বরূপ, বুটস্ট্র্যাপের নমুনা [12] ব্যাগিং [2] দ্বারা শোষণ করা হয়েছে, অন্যদিকে ক্রমবর্ধমান গুরুত্বের নমুনা অ্যাডাবুস্ট দ্বারা গৃহীত হয়েছে [14]। দ্বিতীয়টি হ'ল ইনপুট বৈশিষ্ট্য ম্যানিপুলেশন, যা পৃথক শিখর প্রশিক্ষকদের প্রশিক্ষণের জন্য ডায়ারেন্ট বৈশিষ্ট্য উপ-স্থান তৈরি করে কাজ করে। উদাহরণস্বরূপ, র্যান্ডম সাবস্পেস পদ্ধতির [24] এলোমেলোভাবে প্রতিটি পৃথক শিক্ষার্থীর জন্য বৈশিষ্ট্যগুলির একটি উপসেট বেছে নিয়েছে। তৃতীয়টি হ'ল প্যারামিটার ম্যানিপুলেশন শিখছে, যা বিভিন্ন পৃথক শিক্ষার্থী তৈরি করতে বেস লার্নিং অ্যালগরিদমের ডিয়ারেন্ট প্যারামিটার সেটিংস ব্যবহার করে কাজ করে। উদাহরণস্বরূপ, ডিআরেন্ট প্রাথমিক ওজন স্বতন্ত্র নিউরাল নেটওয়ার্কগুলির জন্য ব্যবহার করা যেতে পারে [২৮], অন্যদিকে ডি-এ্যারেন্ট বিভাজন নির্বাচন পৃথক সিদ্ধান্তের গাছগুলিতে প্রয়োগ করা যেতে পারে [৩ 37]চতুর্থটি আউটপুট প্রতিনিধিত্বমূলক ম্যানিপুলেশন, যা বিভিন্ন স্বতন্ত্র শিক্ষানবিশকে জেনারেট করার জন্য ডায়ারেন্ট আউটপুট উপস্থাপনা ব্যবহার করে কাজ করে। উদাহরণস্বরূপ, ECOC পদ্ধতির [10] আউটপুট কোডগুলি ত্রুটি-সংশোধনকারী নিয়োগ করে, যেখানে Flipping Output method [4] randomly ভাবে কিছু প্রশিক্ষণের উদাহরণগুলির লেবেলগুলিকে পরিবর্তন করে। Different mechanisms পদ্ধতিগুলি একসাথে ব্যবহার করা যেতে পারে, যেমন, [5,68] Note that, however, যে তবে এই পদ্ধতিগুলি সবসময় কার্যকর হয় না। উদাহরণস্বরূপ, ECOC পদ্ধতির [10] আউটপুট কোডগুলি ত্রুটি-সংশোধনকারী নিয়োগ করে, যেখানে Flipping Output method [4] randomly ভাবে কিছু প্রশিক্ষণের উদাহরণগুলির লেবেলগুলিকে পরিবর্তন করে। Different mechanisms পদ্ধতিগুলি একসাথে ব্যবহার করা যেতে পারে, যেমন, [5,68] Note that, however, যে তবে এই পদ্ধতিগুলি সবসময় কার্যকর হয় না। উদাহরণস্বরূপ, data sample manipulation স্থিতিশীল শিখার সাথে ভাল কাজ করে না যার দক্ষতা প্রশিক্ষণ ডেটার সামান্য মোডিফিকেশন অনুসারে পরিবর্তিত হয়। ensemble শেখার সম্পর্কে আরও তথ্য [63] এ পাওয়া যাবে।
Next section টি gcForest introduce করবে, যা প্রায়শই সমস্ত শ্রেণীর বিভিন্নতা mechanisms/বৃদ্ধির জন্য utilizes/ব্যবস্থাকে কাজে লাগিয়ে এমন একটি decision tree ensemble পদ্ধতিরূপ হিসাবে দেখা যেতে পারে।
3 The gcForest Approach
এই বিভাগে আমরা প্রথমে cascade forest structure এবং তারপরে multi-grained scanning প্রবর্তন করব, এর পরে সামগ্রিক আর্কিটেকচার এবং হাইপারপ্যারামিটারে মন্তব্য করব।
3.1 Cascade Forest Structure
গভীর নিউরাল নেটওয়ার্কগুলিতে Representation learning বেশিরভাগ raw features গুলির layer-by-layer processing উপর নির্ভর করে। এই স্বীকৃতি দ্বারা অনুপ্রাণিত হয়ে, gcForest একটি cascade কাঠামো নিযুক্ত করে, যেমন চিত্র 2 তে চিত্রিত হয়েছে, যেখানে ক্যাসকেডের প্রতিটি স্তর তার পূর্ববর্তী স্তর দ্বারা প্রক্রিয়াজাত বৈশিষ্ট্য সম্পর্কিত তথ্য গ্রহণ করে এবং এর প্রসেসিং ফলাফলটিকে পরবর্তী স্তরে আউটপুট করে।
প্রতিটি স্তর decision tree forests-র একটি উপহার,অর্থাত্ ensemble of ensembles ।বৈচিত্র্যকে উত্সাহিত করার জন্য আমরা এখানে বিভিন্ন ধরণের বন অন্তর্ভুক্ত করেছি, কারণ ensemble construction-র জন্য বৈচিত্র্য অত্যন্ত গুরুত্বপূর্ণ [63]।For simplicity, ধরুন যে আমরা two completely-random tree forests/দুটি সম্পূর্ণ এলোমেলো গাছের বন এবং two random forests/দুটি এলোমেলো বন ব্যবহার করি [5]।প্রতিটি সম্পূর্ণরূপে গাছের বনটিতে 500 টি সম্পূর্ণ-এলোমেলো গাছ থাকে [37],এলোমেলোভাবে গাছের প্রতিটি নোডে বিভাজনের জন্য একটি বৈশিষ্ট্য নির্বাচন করে উত্পন্ন,এবং শুকনো পাতা অবধি গাছ বাড়ছে, অর্থাত্ প্রতিটি পাত নোডে কেবল একই শ্রেণীর উদাহরণ রয়েছে।
√d প্রার্থী হিসাবে এলোমেলোভাবে featuresd নির্বাচন করে (d is the number of input features) এবং বিভাজনের জন্য সেরা জিনির মান সহ একটি নির্বাচন করে। প্রতিটি বনে গাছের সংখ্যা একটি হাইপার-প্যারামিটার, যা বিভাগ 3.3 এ আলোচনা করা হবে।
চিত্র 2. ক্যাসকেড বন কাঠামোর চিত্র। ধরুন ক্যাসকেডের প্রতিটি স্তরদুটি এলোমেলো বন (কালো) এবং দুটি সম্পূর্ণ-এলোমেলো গাছের বন (নীল) নিয়ে গঠিত।ধরুন ভবিষ্যদ্বাণী করার জন্য এখানে তিনটি শ্রেণি রয়েছে; সুতরাং, প্রতিটি বন একটি ত্রিমাত্রিক আউটপুট হবে sional class vector/ সিওনাল শ্রেণীর ভেক্টর, যা মূল ইনপুটটির re-representation/পুনঃ-উপস্থাপনের জন্য সংযুক্ত হয়।
উদাহরণস্বরূপ, প্রতিটি বন শ্রেণীর distribution-র একটি estimate তৈরি করবে, যেখানে leaf node সংশ্লিষ্ট উদাহরণটি পড়ে সেখানে প্রশিক্ষণের উদাহরণগুলির different classes-র percentage/শতাংশ গণনা করে, এবং একই বনের সমস্ত গাছ জুড়ে গড়ে চিত্র নেওয়া হবে চিত্র 3 3 , যেখানে লাল রঙগুলি সেই পথগুলিকে হাইলাইট করে যেখানে উদাহরণটি leaf nodes গুলিতে চলে।
The estimated class distribution forms a class vector, which is then concatenated with the original feature vector to be input to the next level of cascade. For example,
Fig. 3. Illustration of class vector generation. Different marks in leaf nodes imply different
classes.
suppose there are three classes, then each of the four forests will produce a threedimensional class vector; thus, the next level of cascade will receive 12 (= 3×4) augmented features.
নোট করুন যে এখানে আমরা ক্লাস ভেক্টরগুলির সহজ রূপটি গ্রহণ করি, অর্থাত্ leaf nodes গুলিতে শ্রেণি বিতরণ যেখানে সংশ্লিষ্ট দৃষ্টান্তটি পড়ে। এটা স্পষ্ট যে এই জাতীয় সংখ্যক augmented features গুলি খুব সীমিত সংযোজনিত তথ্য সরবরাহ করতে পারে এবং যখন মূল বৈশিষ্ট্যটির ভেক্টরগুলি উচ্চ-মাত্রিক হয় তখন এটি ডুবে যাওয়ার খুব সম্ভাবনা থাকে। আমরা পরীক্ষা-নিরীক্ষায় দেখাব যে এ জাতীয় সরল বৈশিষ্ট্য বর্ধন ইতিমধ্যে সুফল হয়েছে। এটি আরও প্রত্যাশিত যে আরও সংযোজন বৈশিষ্ট্যগুলি জড়িত থাকলে আরও প্রসেস পাওয়া যাবে। প্রকৃতপক্ষে, এটি স্পষ্ট যে আরও বৈশিষ্ট্যগুলি সংযুক্ত করা হতে পারে যেমন পিতামাত নোডগুলির শ্রেণিবন্টন যা পূর্ব বন্টন প্রকাশ করে, ভাইবোন নোডগুলি পরিপূরক বন্টন প্রকাশ করে ইত্যাদি etc. আমরা ভবিষ্যতের অন্বেষণের জন্য এই সম্ভাবনাগুলি ত্যাগ করি।
overfitting র ঝুঁকি কমাতে, প্রতিটি বন দ্বারা উত্পাদিত শ্রেণি ভেক্টর k-fold cross validation র দ্বারা উত্পন্ন হয়। বিশদভাবে, প্রতিটি উদাহরণ k − 1 বারের জন্য প্রশিক্ষণ ডেটা হিসাবে ব্যবহৃত হবে, ফলস্বরূপ k − 1 শ্রেণীর ভেক্টর, যার পরে গড় স্তরের ক্যাসকেডের পরবর্তী স্তরের উন্নত বৈশিষ্ট্য হিসাবে শ্রেণীর ভেক্টর উত্পাদন করতে হবে। একটি নতুন স্তর প্রসারণের পরে, পুরো ক্যাসকেডের পারফরম্যান্সটি বৈধতা সেট অনুসারে অনুমান করা যেতে পারে, এবং যদি কোনও চিহ্ন-ক্যান্ট পারফরম্যান্স লাভ না হয় তবে প্রশিক্ষণ পদ্ধতিটি সমাপ্ত হবে; সুতরাং, ক্যাসকেড স্তরের সংখ্যা স্বয়ংক্রিয়ভাবে নির্ধারিত হয়। নোট করুন যে ক্রস বৈধকরণের ত্রুটির পরিবর্তে প্রশিক্ষণের ত্রুটি ক্যাসকেড বৃদ্ধি নিয়ন্ত্রণ করতে ব্যবহার করা যেতে পারে যখন প্রশিক্ষণের ব্যয়টি সম্পর্কিত হয় বা সীমাবদ্ধ গণনার উত্স উপলব্ধ থাকে। বেশিরভাগ গভীর নিউরাল নেটওয়ার্কগুলির বিপরীতে যার মডেল জটিলতা হয়, পর্যাপ্ত পর্যায়ে যখন প্রশিক্ষণ বন্ধ করে gcForest adaptively decides ভাবে তার মডেল জটিলতা সিদ্ধান্ত নেয়। এটি এটিকে প্রশিক্ষণের ডেটাগুলির different scales গুলির ক্ষেত্রে প্রযোজ্য করতে সক্ষম করে, বৃহত্তর স্কেলগুলির মধ্যে সীমাবদ্ধ নয়।
3.2 Multi-Grained Scanning
গভীর স্নায়ুবহুল নেটওয়ার্কগুলি বৈশিষ্ট্য সম্পর্কগুলি পরিচালনা করতে শক্তিশালী, যেমন, কনভোলশনাল নিউরাল নেটওয়ার্কগুলি চিত্রের ডেটাগুলিতে effective যেখানে raw pixelsর মধ্যে স্থানিক সম্পর্ক critica [30,34]; পুনরাবৃত্ত নিউরাল নেটওয়ার্কগুলি সিক্যুয়েন্স ডেটাতে effective যেখানে sequence data সম্পর্কের সমালোচনা [7,18]। এই স্বীকৃতি দ্বারা অনুপ্রাণিত হয়ে আমরা multi-grained scanning র একটি পদ্ধতি দিয়ে ক্যাসকেড বনকে বাড়িয়ে তুলি
Fig. 4. Illustration of feature re-representation using sliding window scanning. Suppose there are three classes, raw features are 400-dim, and sliding window is 100-dim.
উইন্ডোজগুলি থেকে সরানো দৃষ্টান্তগুলির জন্য, আমরা কেবল তাদের মূল প্রশিক্ষণের উদাহরণের লেবেল সহ অর্পণ করি। এখানে কিছু লেবেল অ্যাসাইনমেন্ট সহজাতভাবে ভুল। উদাহরণস্বরূপ, ধরুন মূল প্রশিক্ষণের উদাহরণটি "car" সম্পর্কে ইতিবাচক চিত্র; এটি পরিষ্কারভাবে দেখা যায় যে অনেকগুলি উত্তোলিত দৃষ্টান্তগুলিতে একটি গাড়ী থাকে না এবং তাই এগুলি ভুলভাবে ইতিবাচক হিসাবে চিহ্নিত করা হয়। এটি আসলে Flipping Output method র সাথে সম্পর্কিত [4], ensemble diversity enhancement/জমায়েত বৈচিত্র্য বৃদ্ধির জন্য আউটপুট প্রতিনিধিত্বমূলক হেরফেরের একটি প্রতিনিধি।
নোট করুন যে যখন transformed feature vector গুলির থাকার ব্যবস্থা খুব দীর্ঘ হয়, তখন feature sampling সম্পন্ন করা যায়, উদাহরণস্বরূপ, উইন্ডো স্ক্যানিং স্লাইডিং দ্বারা উত্পন্ন উদাহরণগুলিকে sub sampling করে, যেহেতু completely-random trees গুলির বৈশিষ্ট্য বিভাজন নির্বাচনের উপর নির্ভর করে না যদিও random forests গুলি যথেষ্ট সংবেদনশীল নয় ভুল বৈশিষ্ট্য split/বিভাজন নির্বাচন। এই জাতীয়eature sampling প্রক্রিয়াটি র্যাRandom Subspace method [24], এর সাথে সম্পর্কিত, যা বিভিন্ন উপকরণের বৃদ্ধির জন্য ইনপুট বৈশিষ্ট্যের manipulation/দক্ষতাসহকারে ব্যবহারের প্রতিনিধি।

Figure 4 shows only one size of sliding window. By using multiple sizes of sliding windows, differently grained feature vectors will be generated, as shown in Figure 5.
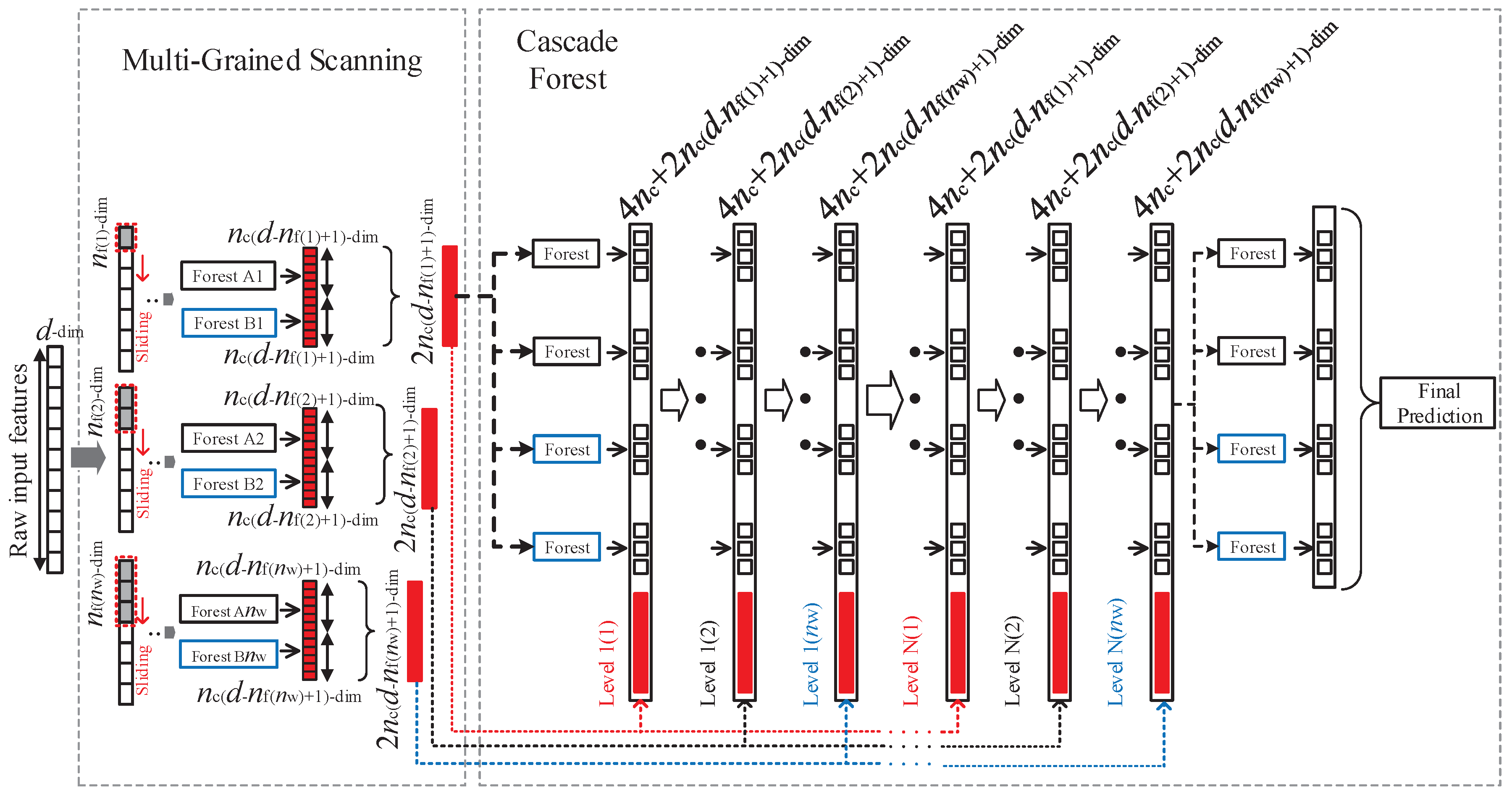
Fig.5.The overall procedure of gcForest.Suppose there are three classes to predict,raw features are 400-dim,and three sizes of sliding windows areused.
3.3 Overall Procedure and Hyper-Parameters
চিত্র 5 gcForest overall পদ্ধতির সংক্ষিপ্তসার জানায়। মনে করুন যে আসল ইনপুটটি 400 টি কাঁচা বৈশিষ্ট্যযুক্ত এবং তিনটি উইন্ডো আকারগুলি multi-grained scanning র জন্য ব্যবহৃত হয়। মি প্রশিক্ষণের উদাহরণগুলির জন্য, 100 টি বৈশিষ্ট্যযুক্ত একটি উইন্ডো 301 × m 100-মাত্রিক প্রশিক্ষণের উদাহরণগুলির একটি ডেটা সেট তৈরি করবে। এই ডেটাগুলি সম্পূর্ণরূপে এলোমেলো গাছের বন এবং একটি এলোমেলো বন, যার প্রত্যেকটিতে 500 টি গাছ রয়েছে তা প্রশিক্ষণের জন্য ব্যবহৃত হবে। যদি পূর্বাভাসিত তিনটি শ্রেণি থাকে তবে বিভাগ 3.1-এ বর্ণিত হিসাবে 1,806-dimensional feature vector প্রাপ্ত হবে। transformed training set টি তখন cascade forest-র 1 ম শ্রেণির প্রশিক্ষণ দেওয়ার জন্য ব্যবহৃত হবে।
চিত্র 5 gcForest overall পদ্ধতির সংক্ষিপ্তসার জানায়। মনে করুন যে আসল ইনপুটটি 400 টি কাঁচা বৈশিষ্ট্যযুক্ত এবং তিনটি উইন্ডো আকারগুলি multi-grained scanning র জন্য ব্যবহৃত হয়। মি প্রশিক্ষণের উদাহরণগুলির জন্য, 100 টি বৈশিষ্ট্যযুক্ত একটি উইন্ডো 301 × m 100-মাত্রিক প্রশিক্ষণের উদাহরণগুলির একটি ডেটা সেট তৈরি করবে। এই ডেটাগুলি সম্পূর্ণরূপে এলোমেলো গাছের বন এবং একটি এলোমেলো বন, যার প্রত্যেকটিতে 500 টি গাছ রয়েছে তা প্রশিক্ষণের জন্য ব্যবহৃত হবে। যদি পূর্বাভাসিত তিনটি শ্রেণি থাকে তবে বিভাগ 3.1-এ বর্ণিত হিসাবে 1,806-dimensional feature vector প্রাপ্ত হবে। transformed training set টি তখন cascade forest-র 1 ম শ্রেণির প্রশিক্ষণ দেওয়ার জন্য ব্যবহৃত হবে।
একইভাবে, 200 এবং 300 টি feature যুক্ত উইন্ডোগুলি স্লাইডিং প্রতিটি মূল প্রশিক্ষণের উদাহরণের জন্য যথাক্রমে 1,206 মাত্রিক এবং 606-dimensional feature vector উত্পন্ন করবে। পূর্ববর্তী গ্রেড দ্বারা উত্পাদিত শ্রেণীর ভেক্টরের সাথে সংযুক্ত transformed feature vectors গুলি পরে যথাক্রমে ক্যাসকেড বনগুলির 2nd-grade and 3rd-grade প্রশিক্ষণের জন্য ব্যবহৃত হবে validation performance একত্রিত হওয়া অবধি এই পদ্ধতি পুনরাবৃত্তি করা হবে। অন্য কথায়, final মডেলটি আসলে cascade of cascades/ক্যাসকেডগুলির একটি ক্যাসকেড, যেখানে প্রতিটি ক্যাসকেড স্ক্যানিংয়ের একটি কণার সাথে সম্পর্কিত প্রতিটি স্তরের multiple levels নিয়ে গঠিত হয়, উদাহরণস্বরূপ, প্রথম ক্যাসকেড Level 1A to Level 1C গঠিত যা চিত্র 5 এ দেখানো হয়েছে। difficult task গুলির জন্য, যদি computational resource গুলি অনুমতি দেয় তবে ব্যবহারকারীরা আরও কণা ব্যবহার করতে পারেন।
একটি পরীক্ষার উদাহরণ দেওয়া হয়েছে, এটি এর অনুরূপ রূপান্তরিত বৈশিষ্ট্য উপস্থাপনা পেতে মাল্টি-গ্রেইন্ড স্ক্যানিং প্রক্রিয়াটি অতিক্রম করবে এবং তারপরে শেষ স্তর পর্যন্ত ক্যাসকেডের মধ্য দিয়ে যাবে। সর্বশেষ স্তরে চার ত্রি-মাত্রিক শ্রেণি ভেক্টরকে একত্রিত করে এবং সর্বাধিক সম্মিলিত মান সহ শ্রেণি গ্রহণের মাধ্যমে final ভবিষ্যদ্বাণীটি পাওয়া যাবে।
Table 1 summarizes the hyper-parameters of deep neural networks and gcForest, where the default values used in our experiments are given.
Table 1 Summary of hyper-parameters and default settings. Boldfont highlights hyper-parameters with relatively larger influence; “?” indicates default value unknown, or generally requiring different settings for different tasks.

4 Experiments
4.1 Configuration
Some experimental datasets are given with training/validation sets. To avoid confusion,
here we call the subsets generated from training set as growing/estimating sets.
গভীর নিউরাল নেটওয়ার্ক configurations গাইডের জন্য, আমরা অ্যাক্টিভেশন ফাংশনের জন্য ReLU/রিলু ব্যবহার করি, loss function-র জন্য crossentropy/ক্রসসেন্ট্রপি, অপ্টিমাইজেশনের জন্য adadelta/অ্যাডাল্টাটা, ট্রেনিং ডেটার স্কেল অনুযায়ী লুকানো স্তরগুলির জন্য ড্রপআউট রেট 0.25 বা 0.5 নেটওয়ার্ক structure hyperparameter গুলি অবশ্য পুরো কাজগুলিতে fixed করা যায় না, অন্যথায় কর্মক্ষমতাটি বিব্রতকরভাবে অসন্তুষ্ট হবে। উদাহরণস্বরূপ, ADULT ডেটাসেটে একটি নেটওয়ার্ক 80% নির্ভুলতা অর্জন করেছে একই আর্কিটেকচারের সাহায্যে YEAST এ কেবল 30% নির্ভুলতা অর্জন করেছে,(কেবলমাত্র ইনপুট / আউটপুট নোডের ডেটা অনুসারে পরিবর্তন হয়েছে)। অতএব, গভীর স্নায়বিক নেটওয়ার্কগুলির জন্য, আমরা বৈধতা সেটগুলিতে বিভিন্ন আর্কিটেকচার পরীক্ষা করি এবং সেরা পারফরম্যান্সের সাথে একটি বাছাই করি, তারপরে প্রশিক্ষণ সেটটিতে পুরো নেটওয়ার্কটিকে পুনরায় প্রশিক্ষণ দিন এবং পরীক্ষার নির্ভুলতার প্রতিবেদন করুন।
4.2 Results
We run experiments on a broad range of tasks.
Image Categorization
MNIST dataset [34] প্রশিক্ষণে (and validating/এবং যাচাইকরণের জন্য) 28 বাই 28 আকারের 60,000 চিত্র এবং পরীক্ষার জন্য 10,000 টি চিত্র ধারণ করে। আমরা এটিকে LeNet-5 (a modern version of LeNet with dropout and ReLUs/ড্রপআউট এবং রিলিজগুলির সাথে লেনেটের একটি আধুনিক সংস্করণ), rbf kernel র সাথে SVM, এবং 2000 টি গাছ সহ একটি স্ট্যান্ডার্ড র্যান্ডম ফরেস্টের পুনরায় বাস্তবায়নের সাথে তুলনা করি। আমরা [23] তে উল্লিখিত Deep Belief Nets-র ফলাফলের ফলাফলও অন্তর্ভুক্ত করি। পরীক্ষার ফলাফলগুলি টেবিল 2 এ সংক্ষিপ্তসারিত হয়েছে, এটি দেখায় যে gcForest, কেবল সারণি 1 এ ডিফল্ট সেটিংস ব্যবহার করে অত্যন্ত প্রতিযোগিতামূলক কর্মক্ষমতা অর্জন করে।
Table 2 Comparison of test accuracy on MNIST

Face Recognition
ORL dataset [47] এ 40 জন ব্যক্তির কাছ থেকে নেওয়া 400 ধূসর-স্কেল ফেসিয়াল ইমেজ রয়েছে। আমরা এটিকে 2 × 3 কার্নেলের 3 x 2 টি বৈশিষ্ট্যযুক্ত মানচিত্রযুক্ত 2 টি conv-layers-র সমন্বিত CNNএর সাথে তুলনা করি এবং প্রতিটি conv-layersরে 2 × 2 সর্বাধিক-পুলিং স্তর থাকে। 128 টি hidden units -র একটি ঘন স্তর সম্পূর্ণরূপে convolutional layers গুলির সাথে সংযুক্ত এবং hidden nally 40 টি গোপন ইউনিট সহ একটি সম্পূর্ণরূপে সংযুক্ত soft-max layer শেষে যুক্ত করা হয়। ReLU/রিলু, crossentropy loss, 0.25 এর dropout rate এবং adadelta/অ্যাডাল্টা প্রশিক্ষণের জন্য ব্যবহৃত হয়। ব্যাচের আকারটি 10 এ সেট করা হয়েছে এবং 50 টি epochs/যুগ ব্যবহৃত হচ্ছে। আমরা অন্যান্য CNN configurations ও চেষ্টা করেছি
যদিও, এই এক best performance দেয়। আমরা প্রশিক্ষণের জন্য randomly choose 5/7/9 images চয়ন করি এবং remaining images গুলিতে পরীক্ষার কার্যকারিতা টি report করি। নোট করুন যে একটি random guess/এলোমেলো অনুমান 2.5% নির্ভুলতা অর্জন করবে, যেহেতু 40 টি সম্ভাব্য ফলাফল রয়েছে। এখানে kNN method তে সমস্ত ক্ষেত্রে k = 3 ব্যবহার করা হয়। পরীক্ষার ফলাফলগুলি টেবিল 3-এ সংক্ষিপ্ত করা হয়েছে , 3. 3 সারণি 1-তে বর্ণিত একই configuration গুলি ব্যবহার করেও gcForest/জিসিফোরেস্ট তিনটি ক্ষেত্রেই ভালভাবে চালিত হয়।
Table 3
Comparison of test accuracy on ORL

Music Classification
GTZAN dataset/জিটিজান ডাটাসেট [৫] তে 10 টি genres/জেনার সংগীত ক্লিপ রয়েছে যার প্রতিটি 30 সেকেন্ড দৈর্ঘ্যের, 100 টি tracks/ট্র্যাক দ্বারা represented/প্রতিনিধিত্ব করে। আমরা ডেটাসেটকে প্রশিক্ষণের জন্য 700 টি ক্লিপ এবং পরীক্ষার জন্য 300 ক্লিপে বিভক্ত করি। তদতিরিক্ত, আমরা প্রতি 30 সেকেন্ডের সংগীত ক্লিপ উপস্থাপন করতে MFCC feature/এমএফসিসি বৈশিষ্ট্যটি ব্যবহার করি, যা মূল শব্দ তরঙ্গকে 1,280 × 13 feature/বৈশিষ্ট্য ম্যাট্রিক্সে রূপান্তর করে। প্রতিটি ফ্রেম তার নিজস্ব প্রকৃতি অনুযায়ী atomic/পারমাণবিক হয়; সুতরাং, CNN একটি 13 × 8 শাঁস/কার্নেলটি conv-layer হিসাবে 32 টি feature maps/বৈশিষ্ট্যযুক্ত মানচিত্র সহ ব্যবহার করে, যার পরে একটি pooling layer থাকে। যথাক্রমে 1,024 and 512 units সহ দুটি fully connected layers সংযোজন করা হয়েছে, এবং finally একটি soft-max layer যুক্ত করা হয়। আমরা এটির MLP কে দুটি hidden layers যথাক্রমে 1,024 এবং 512 ইউনিট সহ respectively/তুলনা করি। দুটি নেটওয়ার্কই অ্যাক্টিভেশন ফাংশন এবং লস ফাংশন হিসাবে শ্রেণীবদ্ধ cross-entropy হিসাবে ReLU/রিলু ব্যবহার করে। Random Forest, Logistic Regression and SVM এর জন্য প্রতিটি ইনপুট একটি 1,280 × 13 feature vector হিসাবে সংযুক্ত করা হয়। পরীক্ষার ফলাফলগুলি সংক্ষিপ্ত করে সারণি 4 এ দেওয়া হয়েছে।
There are studies where CNNs perform more excellently for face recognition, by using huge amount of face images to train the model. Here, we simply use the training data.
Table 4 Comparison of test accuracy on GTZAN

Hand Movement Recognition
sEMG ডেটাসেট [৪৯] এর মধ্যে ছয়টি হাতের চলাচলগুলির একটি, যেমন, spherical, tip, palmar, lateral, cylindrical and hook
/গোলাকার, টিপ, পালমার, পার্শ্বীয়, নলাকার এবং হুকের অন্তর্ভুক্ত 1,800 টি রেকর্ড রয়েছে। এটি একটি timeseries dataset, যেখানে EMG sensors গুলি প্রতি সেকেন্ডে 500 টি বৈশিষ্ট্য ক্যাপচার করে এবং প্রতিটি রেকর্ড 3,000 বৈশিষ্ট্যের সাথে যুক্ত। ইনপুট-1,024-512-আউটপুট কাঠামো সহ একটি MLP ছাড়াও, আমরা 128 hidden units and sequence length-র 6 (500-dim input vector per second/প্রতি সেকেন্ডে 500 মিমি ইনপুট ভেক্টর) সহ একটি recurrent neural network, LSTM [16] মূল্যায়নও করি। পরীক্ষার ফলাফলগুলি সংক্ষিপ্ত আকারে টেবিল 5 এ দেওয়া হয়েছে।
Table 5 Comparison of test accuracy on sEMG data

Sentiment/অনুভূতি Classification
IMDB dataset [40] training-র জন্য 25,000 চলচ্চিত্র reviews এবং 25,000 testing-র জন্য রয়েছে। reviews/পর্যালোচনাগুলি tf-idf features দ্বারা represented করা হয়। এটি image data নয় এবং সুতরাং CNNs সরাসরি প্রযোজ্য নয়। সুতরাং, আমরা এটি স্ট্রাকচার ইনপুট-1,024-1,024-512-256-আউটপুট সহ একটি MLP সঙ্গে তুলনা করি। আমরা [26] এ রিপোর্ট করা ফলাফলও অন্তর্ভুক্ত করি, যা শব্দ embeding/এম্বেডিংয়ের সাথে সুবিধাজনক CNN ব্যবহার করে। tf-idf features/টিএফ-আইডিএফ বৈশিষ্ট্যগুলি spacial or sequential relationships/স্থানিক বা অনুক্রমিক সম্পর্কগুলি প্রকাশ করে না তা বিবেচনা করে আমরা gcForest জন্য multi-grained scanning এড়িয়ে চলেছি । পরীক্ষার নির্ভুলতার সংক্ষিপ্তসার ছক ছকে দেওয়া হয়েছে।
IMDB dataset [40] training-র জন্য 25,000 চলচ্চিত্র reviews এবং 25,000 testing-র জন্য রয়েছে। reviews/পর্যালোচনাগুলি tf-idf features দ্বারা represented করা হয়। এটি image data নয় এবং সুতরাং CNNs সরাসরি প্রযোজ্য নয়। সুতরাং, আমরা এটি স্ট্রাকচার ইনপুট-1,024-1,024-512-256-আউটপুট সহ একটি MLP সঙ্গে তুলনা করি। আমরা [26] এ রিপোর্ট করা ফলাফলও অন্তর্ভুক্ত করি, যা শব্দ embeding/এম্বেডিংয়ের সাথে সুবিধাজনক CNN ব্যবহার করে। tf-idf features/টিএফ-আইডিএফ বৈশিষ্ট্যগুলি spacial or sequential relationships/স্থানিক বা অনুক্রমিক সম্পর্কগুলি প্রকাশ করে না তা বিবেচনা করে আমরা gcForest জন্য multi-grained scanning এড়িয়ে চলেছি । পরীক্ষার নির্ভুলতার সংক্ষিপ্তসার ছক ছকে দেওয়া হয়েছে।
Table 6 Comparison of test accuracy on IMDB




4.3 Low-Dimensional Data
অপেক্ষাকৃত স্বল্প সংখ্যক বৈশিষ্ট্য সহ আমরা UCI-datasets [৩] এ gcForest কেও মূল্যায়ন করি:16 টি বৈশিষ্ট্য এবং 16,000 / 4,000 প্রশিক্ষণ / পরীক্ষার উদাহরণ সহ 14 টি বৈশিষ্ট্যযুক্ত ADULT এবং 32,561 / 16,281 প্রশিক্ষণ / পরীক্ষার উদাহরণ এবং কেবল 8 টি বৈশিষ্ট্য এবং 1,038 / 446 প্রশিক্ষণ / পরীক্ষার উদাহরণ সহ YEAST।সিএনএন-এর মতো অভিনব আর্কিটেকচার যেমন ডেটাতে কাজ করতে পারেনি কারণ স্থানিক সম্পর্ক ব্যতীত খুব কম বৈশিষ্ট্য রয়েছে।সুতরাং, আমরা এটি MLP গুলির সাথে তুলনা করি।Unfortunately, যদিও MLP গুলিতে CNN-এর তুলনায় less configuration বিকল্প রয়েছে,তারা এখনও সেট আপ খুব tricky/কৃপণ।
উদাহরণস্বরূপ, ইনপুট-16-8-8-আউটপুট কাঠামো এবং ReLU/রিলু অ্যাক্টিভেশন সহ MLP 76.37% নির্ভুলতা অর্জন করে তবে LETTER মাত্র 33%।আমরা উপসংহারে পৌঁছেছি যে একটি MLP structure বাছাই করার কোনও উপায় নেই যা সমস্ত ডেটাসেটগুলিতে শালীন কার্য সম্পাদন করে।অতএব,আমরা সেরা পারফরম্যান্স সহ different MLP কাঠামোগুলি report করি: LETTER র জন্য কাঠামোটি ইনপুট -70-50-আউটপুট, ADULT/অ্যাডাল্টের জন্য ইনপুট-30-20-আউটপুট,এবং YEAST এর জন্য ইনপুট -50-30-আউটপুট। বিপরীতে, gcForest সারণী 1 এ দেখানো একই configuration ব্যবহার করে,এই small-scale ডেটার বৈশিষ্ট্যগুলি স্পেসিয়াল রাখে না তা বিবেচনা করে multi-grained scanning টি পরিত্যাগ করা হবে বা অনুক্রমিক সম্পর্ক। পরীক্ষার ফলাফলগুলি সংক্ষিপ্ত করে সারণি 7 এ দেওয়া হয়েছে।
Table 7 Comparison of test accuracy on low-dim data
4.4 High-Dimensional Data
CIFAR-10 dataset [৩১] প্রশিক্ষণের জন্য 10 টি ক্লাসের 50,000 চিত্র এবং পরীক্ষার জন্য 10,000 চিত্র ধারণ করে। এখানে, প্রতিটি চিত্র একটি 32 বাই 32 রঙের চিত্র 8 টি গ্রেলিভেল সহ; সুতরাং, প্রতিটি উদাহরণ 8192-dim। পরীক্ষার ফলাফলগুলি টেবিল 8-এ দেখানো হয়েছে, এতে সাহিত্যে বেশ কয়েকটি deep neural networks-র ফলাফলও অন্তর্ভুক্ত রয়েছে।
Table 8 Comparison of test accuracy on CIFAR-10
যেমন আমরা Section 3 তে আলোচনা করেছি, বর্তমানে আমরা প্রতিটি বন থেকে কেবলমাত্র 10-dim augmented feature vector ব্যবহার করি এবং এ জাতীয় সংখ্যক augmented feature গুলি সহজেই মূল দীর্ঘ বৈশিষ্ট্য ভেক্টরে নিমজ্জিত হবে। তবুও, যদিও ডিফল্ট সেটিং সহ gcForest, অর্থাত্, gcForest (ডিফল্ট), অত্যাধুনিক DNN- এর চেয়ে নিম্নতর এটি ডি-এন-এন পদ্ধতির মধ্যে ইতিমধ্যে সেরা। তদুপরি, task-specific tuningর মাধ্যমে gcForest এর কার্যকারিতা আরও উন্নত করা যেতে পারে, যেমন, আরও grains/শস্য অন্তর্ভুক্ত করে (i.e., using more sliding window sizes in multi-grained scanning/যেমন, মাল্টি-গ্রেইন্ড স্ক্যানিংয়ে আরও স্লাইডিং উইন্ডো আকারগুলি ব্যবহার করে) যেমন gcForest(5grains) শস্য ব্যবহার করে। এটি দেখতেও আকর্ষণীয় যে পারফরম্যান্সটি gcForest(gbdt)) দিয়ে significant improvement পায় যা কেবল GBDT [6]. Section 4.8 এর সাথে final স্তরের প্রতিস্থাপন করে। বিভাগ ৪.৮ দেখায় যে আরও বৃহত্তর মডেলগুলিকে প্রশিক্ষণ দিতে পারলে আরও ভাল পারফরম্যান্স পাওয়া যায়।
4.5 Running time
আমাদের পরীক্ষাগুলিPC with 2 Intel E5 2695 v4 CPUs (18 cores) সহ একটি পিসি ব্যবহার করে এবং gcForest চলমান efficiency ভাল। উদাহরণস্বরূপ, IMDB dataset (25,000 examples with 5,000 features), এটি ক্যাসকেড স্তরের প্রতি 267.1 সেকেন্ড সময় নেয় এবং স্বয়ংক্রিয়ভাবে 9 ক্যাসকেড স্তর সহ শেষ হয়, 2,404 সেকেন্ড বা 40 মিনিটের পরিমাণ। বিপরীতে, একই ডেটাসেটের তুলনায় MLP কে কনভার্জেশনের জন্য 50 epochs এবং প্রতি epochs-র 93 সেকেন্ডের প্রয়োজন, প্রশিক্ষণের জন্য 4,650 সেকেন্ড বা 77.5 মিনিটের পরিমাণ; GPU (Nvidia Titan X pascal) ব্যবহার করে, প্রতি পর্বের 14 সেকেন্ড with batch size of 32), 700 সেকেন্ড বা 11.6 মিনিটের পরিমাণ। Multi-grained scanning gcForest র ব্যয় বাড়িয়ে তুলবে; তবে different grains of scanning সহজাতভাবে সমান্তরাল। এছাড়াও, দুটি completely-random tree forests এবং random forests are parallel ensemble methods [63]। সুতরাং, gcForest র efficiency অপ্টিমাইজড সমান্তরাল বাস্তবায়নের মাধ্যমে আরও উন্নতি করা যায়। নোট করুন যে training cost নিয়ন্ত্রণযোগ্য কারণ ব্যবহারকারীগণ গণ্যমূল্য ব্যয় উপলক্ষে বিবেচনা করে শস্য, বন, গাছের সংখ্যা নির্ধারণ করতে পারেন। এটি আরও লক্ষণীয় যে উপরের তুলনাটি gcForest র সাথে কিছুটা অন্যায়, কারণ অনেকগুলি different আর্কিটেকচারের রিপোর্ট করা পারফরম্যান্স অর্জনের জন্য নিউরাল নেটওয়ার্কগুলির জন্য চেষ্টা করা হয়েছে তবে এই সময়ের ব্যয়টি অন্তর্ভুক্ত নয়।
4.6 Influence of Multi-Grained Scanning
cascade forest structure এবং multi-grained scanning-র পৃথক অবদান অধ্যয়ন করতে, সারণী 9 cascade forest on MNIST, GTZAN and sEMG datasets ফরেস্টের সাথে gcForest র তুলনা করে। এটা স্পষ্ট যে spacial or sequential feature relationships আছে যখন, multi-grained scanning প্রক্রিয়া দৃশ্যত কর্মক্ষমতা উন্নত করতে সহায়তা করে।
Table 9 Results of gcForest w/wo multi-grained scanning
4.7 Influence of Cascade Structure
GcForest এর final model structure টি ক্যাসকেডগুলির একটি ক্যাসকেড, যেখানে প্রতিটি ক্যাসকেডে scanning-র একটি grainর সাথে সম্পর্কিত প্রতিটি স্তরের একাধিক স্তর রয়েছে যা চিত্র 5 এ দেখানো হয়েছে। একাধিক grain থেকে বৈশিষ্ট্যগুলি শোষণের অন্যান্য সম্ভাব্য উপায় রয়েছে, উদাহরণস্বরূপ, সমস্ত বৈশিষ্ট্য একসাথে একত্র করে, চিত্র 6 এ দেখানো হয়েছে
সারণী 10 gcForestconc সঙ্গে gcForest তুলনা করে, যা দেখায় যে multiple grains থেকে বৈশিষ্ট্যগুলি একত্রিত করা gcForest বর্তমান নকশার মতো ভাল নয়।তবুও, আরও ভাল ফলাফল আরও ভাল ফলাফল হতে পারে; আমরা এটি future exploration.র জন্য রেখে দিই।

4.8 Influence of Larger Models
চিত্র 7-এ আমাদের ফলাফলগুলি প্রস্তাব দেয় যে বৃহত্তর মডেলগুলি আরও ভাল পারফরম্যান্সে হতে পারে,যদিও আমরা আরও বেশি grain চেষ্টা করি নি, computational resource এর সীমাবদ্ধতার কারণে forests and trees । নোট করুন যে বৃহত মডেলগুলির প্রশিক্ষণ সক্ষম করার জন্য গণ্য সুবিধাগুলি গুরুত্বপূর্ণ; যেমন,DNNগুলির জন্য GPU। On one hand , কিছু নতুন computational devices ,যেমন Intel KNL of the MIC (Many Integrated Core) আর্কিটেকচার, gcForest র জন্য DNN-এর GPU-র মতো potential acceleration হতে পারে। অন্য দিকে,gcForest এর কিছু উপাদান যেমন, multi-grained scanning, GPU গুলি ব্যবহার করে accelerated হতে পারে। তদুপরি, distributed কম্পিউটিং বাস্তবায়নের সাথে উন্নতির জন্য প্রচুর জায়গা রয়েছে।
0 comments:
Post a Comment