নিউরাল নেটওয়ার্কগুলির পরিচিতি আমাদের সকলের প্রয়োজন!
নিউরাল নেটওয়ার্কগুলির পরিচিতি আমাদের সকলের প্রয়োজন!
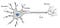
আমাদের মস্তিষ্কে একটি নিউরন
তথ্য প্রক্রিয়াকরণ এবং আমাদের চারপাশের বিশ্বকে মডেল করার জন্য আমাদের মস্তিষ্ক নিউরনের অত্যন্ত বৃহত আন্তঃসংযুক্ত নেটওয়ার্ক ব্যবহার করে। সোজা কথায়, একটি নিউরন ডেনড্রাইট ব্যবহার করে অন্যান্য নিউরন থেকে ইনপুট সংগ্রহ করে । নিউরনটি সমস্ত ইনপুটগুলির যোগফল দেয় এবং ফলস্বরূপ মান যদি একটি প্রান্তিকের চেয়ে বেশি হয় তবে এটি আগুন ধরিয়ে দেয়। এরপরে অগ্নিকাণ্ডের সংকেতটি অ্যাক্সনের মাধ্যমে অন্যান্য সংযুক্ত নিউরনে পাঠানো হয়।
এখন, আমরা কীভাবে কৃত্রিম নিউরনকে মডেল করব?
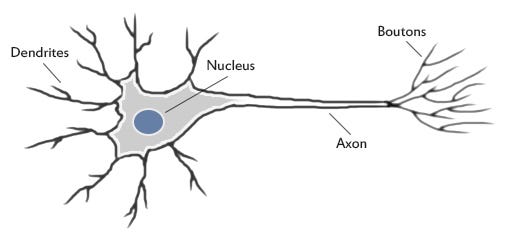
একটি কৃত্রিম নিউরনের মডেল
চিত্রটিতে এন অন্যান্য নিউরনের সাথে সংযুক্ত একটি নিউরনকে চিত্রিত করা হয়েছে এবং এভাবে এন ইনপুটগুলি পাওয়া যায় (x1, x2,… .. এক্সএন)। এই কনফিগারেশনটিকে পারসেপ্ট্রন বলা হয় ।
ইনপুটগুলি (এক্স 1, এক্স 2,…। এক্সএন) এবং ওজন (ডাব্লু 1, ডাব্লু 2,…। ডাব্লুএন) প্রকৃত সংখ্যা এবং এটি ইতিবাচক বা নেতিবাচক হতে পারে।
পার্সেপট্রনটিতে ওজন, সমষ্টি প্রসেসর এবং একটি অ্যাক্টিভেশন ফাংশন থাকে।
দ্রষ্টব্য : এটিতে একটি প্রান্তিক প্রসেসর (পক্ষপাত নামে পরিচিত) রয়েছে তবে আমরা পরে সে সম্পর্কে কথা বলব!
সমস্ত ইনপুট পৃথকভাবে ওজনযুক্ত, একসাথে যুক্ত এবং অ্যাক্টিভেশন ফাংশন এ পাস করা হয়। বিভিন্ন ধরণের অ্যাক্টিভেশন ফাংশন রয়েছে তবে সিম্পলগুলির মধ্যে একটি হ'ল স্টেপ ফাংশন। একটি ধাপের ফাংশনটি সাধারণত 1 টি আউটপুট দেয় যদি ইনপুটটি একটি নির্দিষ্ট প্রান্তিকের চেয়ে বেশি হয়, অন্যথায় এটির ফলাফল 0 হবে।
দ্রষ্টব্য : অন্যান্য অ্যাক্টিভেশন ফাংশনগুলিও রয়েছে যেমন সিগময়েড ইত্যাদি যা অনুশীলনে ব্যবহৃত হয়।
একটি উদাহরণ হবে,
ইনপুট 1 ( x1 ) = 0.6 ইনপুট 2 ( x2 ) = 1.0
ওজন 1 ( ডাব্লু 1 ) = 0.5 ওজন 2 ( ডাব্লু 2 ) = 0.8
প্রান্তিক = 1.0
ইনপুটগুলি ওজন এবং এগুলি একসাথে যোগ করা দেয়,
x1w1 + x2w2 = (0.6 x 0.5) + (1 x 0.8) = 1.1
এখানে মোট ইনপুটটি প্রান্তিকের চেয়ে বেশি এবং এভাবে নিউরন অগ্নিকাণ্ড।
অনুধাবনকারীদের প্রশিক্ষণ!
একটি শিশুকে বাস চিনতে শেখানোর চেষ্টা করবেন? আপনি তার উদাহরণগুলি দেখান, তাকে বলেন, "এটি একটি বাস। এটি কোনও বাস নয়, "যতক্ষণ না শিশু বাসের ধারণাটি না শেখে। তদুপরি, যদি শিশুটি নতুন বস্তুগুলি দেখে যা সে আগে দেখেনি, তবে আমরা আশা করতে পারি যে তিনি নতুন বস্তুটি বাস কিনা তা সঠিকভাবে সনাক্ত করা উচিত।
পার্সপিট্রনের পিছনে এই ধারণাটি ঠিক।
একইভাবে, একটি প্রশিক্ষণ সেট থেকে ইনপুট ভেক্টরগুলি একের পর এক পার্সেপট্রনকে উপস্থাপন করা হয় এবং নীচের সমীকরণ অনুসারে ওজনগুলি সংশোধন করা হয়,
সমস্ত ইনপুট আমি,
W (i) = W (i) + a * (TA) * P (i), যেখানে a হল শিক্ষার হার
দ্রষ্টব্য: আসলে সমীকরণটি ডাব্লু (আই) = ডাব্লু (আই) + এ * জি '(সমস্ত ইনপুটগুলির যোগফল) * (টিএ) * পি (আই), যেখানে জি' অ্যাক্টিভেশন ফাংশনের ডেরাইভেটিভ। যেহেতু পদক্ষেপ ফাংশনটির ডেরাইভেটিভ নিয়ে কাজ করা সমস্যাযুক্ত, তাই আমরা এখানে সমীকরণটি বাদ দিই।
এখানে, ডাব্লু হ'ল ওয়েট ভেক্টর। পি ইনপুট ভেক্টর। টি হ'ল সঠিক আউটপুট যা পার্সেপট্রনকে জানা উচিত ছিল এবং এ হ'ল পার্সেপট্রন দ্বারা প্রদত্ত আউটপুট।
সমস্ত ইনপুট প্রশিক্ষণ ভেক্টরগুলির একটি সম্পূর্ণ পাস যখন কোনও ত্রুটি ছাড়াই সম্পন্ন হয়, তখন পার্সেপ্রেট্রন শিখেছে!
এই মুহুর্তে, একটি ইনপুট ভেক্টর পি (ইতিমধ্যে প্রশিক্ষণ সংস্থায়) পেরসেপ্ট্রনকে দেওয়া হয়েছে, এটি সঠিক মান আউটপুট করবে। যদি পি প্রশিক্ষণ সেটে না থাকে তবে নেটওয়ার্কটি পি এর কাছাকাছি অন্যান্য প্রশিক্ষণ ভেক্টরগুলির অনুরূপ একটি আউটপুট নিয়ে প্রতিক্রিয়া জানাবে will
পার্সেপট্রন আসলে কী করছে?
পার্সেপেট্রন সমস্ত ইনপুট যুক্ত করছে এবং তাদের 2 টি বিভাগে পৃথক করছে, যার ফলে এটি আগুন জ্বলে ওঠে এবং যা তা নয়। এটি, এটি লাইন অঙ্কন করছে:
w1x1 + w2x2 = t, যেখানে টি প্রান্তিক হয়
এবং ইনপুট পয়েন্ট কোথায় আছে তা খুঁজছেন। লাইনের একপাশে পয়েন্টগুলি 1 বিভাগে পড়ে অন্যদিকে পয়েন্টগুলি অন্য বিভাগে পড়ে। এবং ওজন এবং প্রান্তিকের যে কোনও কিছু হতে পারে, এটি 2 মাত্রিক ইনপুট স্পেস জুড়ে কেবল কোনও লাইন ।
পারসেপ্টরনস এর সীমাবদ্ধতা
প্রতিটি ইনপুটগুলি এই জাতীয় লাইনের দ্বারা ভাগ করা যায় না। এগুলিকে বলা যেতে পারে রৈখিক বিভাজক । যদি ভেক্টরগুলি লৈখিকভাবে পৃথকযোগ্য না হয়, শেখা কখনই এমন পর্যায়ে পৌঁছাতে পারে না যেখানে সমস্ত ভেক্টরগুলিকে সঠিকভাবে শ্রেণিবদ্ধ করা হয়। লিনিয়ার অ-বিচ্ছেদী ভেক্টরগুলির সাথে সমস্যাগুলি সমাধান করতে পার্সেপ্রেটনের অক্ষমতার সবচেয়ে বিখ্যাত উদাহরণ হ'ল বুলিয়ান এক্সওআর সমস্যা।
পরবর্তী অংশ এই প্রবন্ধে সিরিজের এই ব্যবহার করতে কিভাবে প্রদর্শন করা হবে নিঃশব্দ- স্তর স্নায়ুর নেটওয়ার্ক , ফিরে প্রসারণ প্রশিক্ষণ পদ্ধতি ব্যবহার করে।
আপনি যদি এই নিবন্ধটি পড়তে আনন্দিত হন, আপনার ভালবাসা দেখানোর জন্য সামান্য সবুজ হার্টের বোতামটি চাপুন!
সিরিজের পরবর্তী নিবন্ধের জন্য আপডেট থাকার জন্য, দয়া করে অনুসরণ করুন :)
এবং আপনি যদি আপনার বন্ধুরাও এটি পড়তে চান তবে ক্লিক করুন শেয়ার করুন!
একটি পুনরুদ্ধার হিসাবে, আমি দ্রুত একক স্তরযুক্ত নিউরাল নেটওয়ার্ক যা করে তা যাব। একবার প্রশিক্ষণের নমুনাটি নেটওয়ার্কে ফিড করা হলে, একক স্তরযুক্ত নিউরাল নেটওয়ার্কের প্রতিটি আউটপুট নোড ( পার্সেপট্রনও বলা হয় ) সমস্ত ইনপুটগুলির একটি ওজনযুক্ত পরিমাণ নেয় এবং এটিকে একটি অ্যাক্টিভেশন ফাংশন (সম্ভবত সিগময়েড বা পদক্ষেপ) মাধ্যমে পাস করে এবং তার সাথে আসে আউটপুট। ওজনগুলি নীচের সমীকরণটি ব্যবহার করে সংশোধন করা হয়,
সমস্ত ইনপুট আমি,
ডাব্লু (আই) = ডব্লু (আই) + এ * জি '(সমস্ত ইনপুটগুলির যোগফল) * (টিএ) * পি (আই), যেখানে a হল শিক্ষার হার এবং জি' অ্যাক্টিভেশন ফাংশনের ডেরাইভেটিভ।
দ্রষ্টব্য: অ্যাক্টিভেশন ফাংশনটি একটি পদক্ষেপ ফাংশন হলে আমরা ডেরাইভেটিভ ফাংশনটি ফেলে দেই।
এই নেটওয়ার্কটি সমস্ত প্রশিক্ষণের সেটটি বেশ কয়েকবার খাওয়ানোর দ্বারা পুনরাবৃত্তি করা হয় যতক্ষণ না নেটওয়ার্ক সমস্ত নমুনার জন্য সঠিক আউটপুটে সাড়া দেয়। প্রশিক্ষণ কেবল লাইনগতভাবে পৃথকযোগ্য ইনপুটগুলির জন্যই সম্ভব। এটি থেকে বহু স্তরের নিউরাল নেটওয়ার্কগুলি ছবিতে আসে।
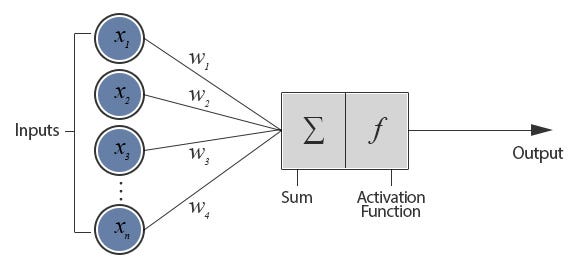
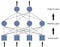
মাল্টি-লেয়ার্ড নিউরাল নেটওয়ার্কগুলি কী কী?
একটি বহু স্তরের নিউরাল নেটওয়ার্ক
ইনপুট স্তর থেকে প্রতিটি ইনপুট লুকানো স্তরের প্রতিটি নোড পর্যন্ত খাওয়ানো হয়, এবং সেখান থেকে আউটপুট স্তরের প্রতিটি নোডে। আমাদের লক্ষ করা উচিত যে প্রতি স্তরটিতে নোডের সংখ্যা থাকতে পারে এবং শেষ পর্যন্ত আউটপুট স্তরে পৌঁছানোর আগে সাধারণত একাধিক লুকানো স্তর থাকে।
তবে এই নেটওয়ার্কটি প্রশিক্ষণের জন্য আমাদের একটি শেখার অ্যালগরিদম প্রয়োজন যা টিউন করতে সক্ষম হওয়া উচিত এটাই না আউটপুট স্তর এবং লুকানো স্তর মধ্যে ওজন কিন্তু লুকানো স্তর এবং ইনপুট স্তর মধ্যে ওজন।
প্রবেশের পিছনে প্রচার!
সবার আগে আমাদের বুঝতে হবে যে আমাদের কী অভাব রয়েছে। লুকানো স্তর এবং ইনপুট স্তরের মধ্যে ওজন টিউন করতে, আমাদের লুকানো স্তরে ত্রুটিটি জানতে হবে, তবে আমরা কেবল আউটপুট স্তরে ত্রুটিটি জানি ( প্রশিক্ষণের নমুনা থেকে আমরা সঠিক আউটপুট জানি এবং আউটপুটটিও জানি নেটওয়ার্ক দ্বারা পূর্বাভাস।)
সুতরাং, যে পদ্ধতিটির পরামর্শ দেওয়া হয়েছিল তা হ'ল আউটপুট স্তরে ত্রুটিগুলি গ্রহণ করা এবং আনুপাতিকভাবে এগুলি পিছনের দিকে লুকানো স্তরে প্রচার করুন।
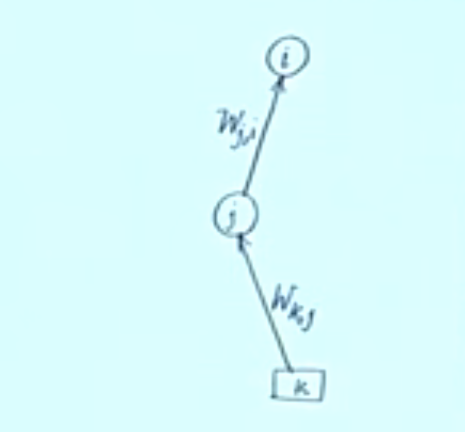
নীচে আমরা একটি 2 স্তরযুক্ত নেটওয়ার্কের জন্য সমীকরণ লিখব তবে একই ধারণাটি কোনও সংখ্যক স্তরযুক্ত নেটওয়ার্কে প্রযোজ্য।
2 স্তরযুক্ত নেটওয়ার্কের একটি অংশ
উপরের চিত্রটিতে প্রদর্শিত নাম অনুসারে আমরা অনুসরণ করব।


0 comments:
Post a Comment