বাস্তব বিশ্বে, স্ক্র্যাচ থেকে সি ওভলিউশনাল এন ইউরাল এন ইটওয়ার্ক (সিএনএন) প্রশিক্ষিত করা বিরল , কারণ আরও ভাল পারফরম্যান্স পেতে বিশাল ডেটাসেট সংগ্রহ করা শক্ত। পরিবর্তে, একটি খুব বড় ডেটাসেটে প্রাক-প্রশিক্ষিত নেটওয়ার্ক ব্যবহার করা এবং আপনার শ্রেণিবিন্যাস সমস্যার জন্য এটি টিউন করা সাধারণ বিষয়, এই প্রক্রিয়াটিকে ট্রান্সফার লার্নিং বলা হয় ।
ট্রান্সফার লার্নিং কি
এটি একটি মেশিন লার্নিং পদ্ধতি যেখানে একটি মডেলকে এমন একটি কাজের উপর প্রশিক্ষণ দেওয়া হয় যা অন্য কোনও কাজের জন্য প্রশিক্ষণ দেওয়া (বা সুর করা) হতে পারে, এটি আজকাল খুব জনপ্রিয়, বিশেষত কম্পিউটার দর্শন এবং প্রাকৃতিক ভাষা প্রক্রিয়াকরণ সমস্যার ক্ষেত্রে। গভীর শেখার মডেলগুলি প্রশিক্ষণের জন্য প্রয়োজনীয় প্রচুর সংস্থান সরবরাহ করে ট্রান্সফার শেখা খুব সহজ। এখানে স্থানান্তর শেখার সর্বাধিক গুরুত্বপূর্ণ সুবিধা রয়েছে:
- প্রশিক্ষণের সময় বাড়িয়ে তোলে।
- এর জন্য কম ডেটা দরকার।
- গভীর শিক্ষণ বিশেষজ্ঞদের দ্বারা তৈরি করা হয়েছে এমন অত্যাধুনিক মডেলগুলি ব্যবহার করুন।
এই কারণে, এটি পরিবর্তে ইমেজ শ্রেণীবিন্যাস সমস্যার জন্য শেখার ব্যবহার হস্তান্তর করাই ভালো আপনার মডেল এবং স্ক্র্যাচ থেকে প্রশিক্ষণ তৈরি , যেমন মডেলের ResNet , InceptionV3 , Xception এবং MobileNet একটি বৃহদায়তন ডেটা সেটটি নামক প্রশিক্ষণ দেওয়া হয় ImageNet 14 বেশি রয়েছে যা মিলিয়ন ইমেজ যা 1000 বিভিন্ন বস্তুকে শ্রেণিবদ্ধ করে।
ডেটাসেট লোড এবং প্রস্তুত করা হচ্ছে
আমরা ফুলের ফটো ডেটাসেট ব্যবহার করব, যা 5 ধরণের ফুল ( ডেইজি , ড্যান্ডেলিয়ন , গোলাপ , সূর্যমুখী এবং টিউলিপস ) নিয়ে গঠিত।
নিম্নলিখিত কমান্ড দ্বারা আপনার সমস্ত কিছু ইনস্টল করার পরে:
pip3 install tensorflow keras numpy matplotlib
একটি নতুন পাইথন ফাইল খুলুন এবং প্রয়োজনীয় মডিউলগুলি আমদানি করুন:
import tensorflow as tf
from keras.models import Model
from keras.applications import MobileNetV2, ResNet50, InceptionV3 # try to use them and see which is better
from keras.layers import Dense
from keras.callbacks import ModelCheckpoint, TensorBoard
from keras.utils import get_file
from keras.preprocessing.image import ImageDataGenerator
import os
import pathlib
import numpy as np
ডেটাসেটটি বেমানান চিত্রের আকারের সাথে আসে, ফলস্বরূপ, আমাদের সমস্ত চিত্রকে এমন আকারে আকার দিতে হবে যা মোবাইল নেট দ্বারা গ্রহণযোগ্য (আমরা যে মডেলটি ব্যবহার করব):
batch_size = 32
# 5 types of flowers
num_classes = 5
# training for 10 epochs
epochs = 10
# size of each image
IMAGE_SHAPE = (224, 224, 3)
আসুন ডেটাসেটটি লোড করুন:
def load_data():
"""This function downloads, extracts, loads, normalizes and one-hot encodes Flower Photos dataset"""
# download the dataset and extract it
data_dir = get_file(origin='https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz',
fname='flower_photos', untar=True)
data_dir = pathlib.Path(data_dir)
# count how many images are there
image_count = len(list(data_dir.glob('*/*.jpg')))
print("Number of images:", image_count)
# get all classes for this dataset (types of flowers) excluding LICENSE file
CLASS_NAMES = np.array([item.name for item in data_dir.glob('*') if item.name != "LICENSE.txt"])
# roses = list(data_dir.glob('roses/*'))
# 20% validation set 80% training set
image_generator = ImageDataGenerator(rescale=1/255, validation_split=0.2)
# make the training dataset generator
train_data_gen = image_generator.flow_from_directory(directory=str(data_dir), batch_size=batch_size,
classes=list(CLASS_NAMES), target_size=(IMAGE_SHAPE[0], IMAGE_SHAPE[1]),
shuffle=True, subset="training")
# make the validation dataset generator
test_data_gen = image_generator.flow_from_directory(directory=str(data_dir), batch_size=batch_size,
classes=list(CLASS_NAMES), target_size=(IMAGE_SHAPE[0], IMAGE_SHAPE[1]),
shuffle=True, subset="validation")
return train_data_gen, test_data_gen, CLASS_NAMES
উপরের ফাংশনটি ডেটাসেটটি ডাউনলোড করে এবং এক্সট্রাক্ট করে এবং তারপরে একটি পাইথন জেনারেটরে ডেটাসেটটি মোড়ানোর জন্য ইমেজডেটা জেনারেটর কেরাস ইউটিলিটি ক্লাস ব্যবহার করে (সুতরাং চিত্রগুলি কেবল একটি শটে নয়, ব্যাচ দ্বারা মেমরিতে লোড হয়)।
এর পরে, আমরা চিত্রগুলি একটি নির্দিষ্ট আকারে স্কেল এবং আকার পরিবর্তন করি এবং তারপরে প্রশিক্ষণের জন্য ডেটাসেটটিকে 80% এবং বৈধতার জন্য 20% দিয়ে বিভক্ত করি।
মডেল নির্মাণ
আমরা মোবাইল নেটভিভি মডেলটি ব্যবহার করতে যাচ্ছি , এটি খুব ভারী মডেল নয় তবে প্রশিক্ষণ এবং পরীক্ষার প্রক্রিয়াতে ভাল কাজ করে।
যেমনটি আগেই উল্লেখ করা হয়েছে, এই মডেলটি বিভিন্ন 1000 টি অবজেক্টকে শ্রেণিবদ্ধ করার জন্য প্রশিক্ষণপ্রাপ্ত, আমাদের এই মডেলটির টিউন করার একটি উপায় প্রয়োজন যাতে এটি কেবল আমাদের ফুলের শ্রেণিবিন্যাসের জন্য উপযুক্ত হতে পারে। ফলস্বরূপ, আমরা সেই শেষটি সম্পূর্ণ সংযুক্ত স্তরটি সরিয়ে ফেলব এবং সফটম্যাক্স অ্যাক্টিভেশন ফাংশন সহ 5 টি ইউনিট সমন্বিত আমাদের নিজস্ব চূড়ান্ত স্তর যুক্ত করব:
def create_model(input_shape):
# load MobileNetV2
model = MobileNetV2(input_shape=input_shape)
# remove the last fully connected layer
model.layers.pop()
# freeze all the weights of the model except the last 4 layers
for layer in model.layers[:-4]:
layer.trainable = False
# construct our own fully connected layer for classification
output = Dense(num_classes, activation="softmax")
# connect that dense layer to the model
output = output(model.layers[-1].output)
model = Model(inputs=model.inputs, outputs=output)
# print the summary of the model architecture
model.summary()
# training the model using rmsprop optimizer
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
return model
উপরের ফাংশনটি প্রথমে মডেল ওজন ডাউনলোড করবে (যদি না পাওয়া যায়) এবং তারপরে শেষ স্তরটি সরিয়ে ফেলবে।
তারপরে, আমরা শেষ স্তরগুলি হিমায়িত করি, কারণ এটি প্রাক প্রশিক্ষিত, আমরা এই ওজনগুলিকে সংশোধন করতে চাই না। যাইহোক, শেষ কনভ্যুশনাল স্তরটিকে পুনরায় প্রশিক্ষণ করা একটি ভাল অনুশীলন কারণ এই ডেটাসেটটি মূল ইমেজনেট ডেটাসেটের সাথে বেশ অনুরূপ, তাই আমরা ওজনগুলি (এতটা) নষ্ট করব না।
অবশেষে, আমরা আমাদের নিজস্ব ঘন স্তরটি তৈরি করি যা পাঁচটি নিউরন সমন্বিত থাকে এবং এটি মোবাইল নেটভি 2 মডেলের শেষ স্তরের সাথে সংযুক্ত করি। নিম্নলিখিত চিত্রটি আর্কিটেকচারটি দেখায়:
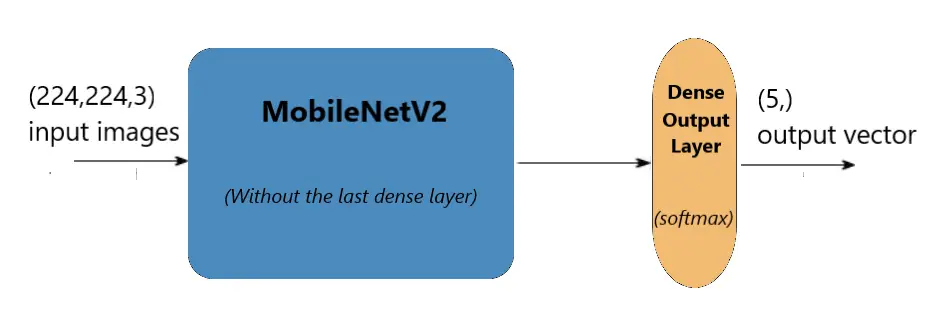
মডেল প্রশিক্ষণ
প্রশিক্ষণ শুরু করতে উপরের দুটি ফাংশন ব্যবহার করা যাক:
if __name__ == "__main__":
# load the data generators
train_generator, validation_generator, class_names = load_data()
# constructs the model
model = create_model(input_shape=IMAGE_SHAPE)
# model name
model_name = "MobileNetV2_finetune_last5"
# some nice callbacks
tensorboard = TensorBoard(log_dir=f"logs/{model_name}")
checkpoint = ModelCheckpoint(f"results/{model_name}" + "-loss-{val_loss:.2f}-acc-{val_acc:.2f}.h5",
save_best_only=True,
verbose=1)
# make sure results folder exist
if not os.path.isdir("results"):
os.mkdir("results")
# count number of steps per epoch
training_steps_per_epoch = np.ceil(train_generator.samples / batch_size)
validation_steps_per_epoch = np.ceil(validation_generator.samples / batch_size)
# train using the generators
model.fit_generator(train_generator, steps_per_epoch=training_steps_per_epoch,
validation_data=validation_generator, validation_steps=validation_steps_per_epoch,
epochs=epochs, verbose=1, callbacks=[tensorboard, checkpoint])
এখানে অভিনব কিছু নয়, ডেটা লোড করা, মডেলটি তৈরি করা এবং তারপরে সেরা মডেলগুলি ট্র্যাকিং এবং সেভ করার জন্য কিছু কলব্যাক ব্যবহার করা।
আপনি স্ক্রিপ্টটি সম্পাদন করার সাথে সাথে প্রশিক্ষণ প্রক্রিয়া শুরু হবে, আপনি লক্ষ্য করবেন যে সমস্ত ওজন প্রশিক্ষিত হচ্ছে না:
Total params: 2,264,389
Trainable params: 418,565
Non-trainable params: 1,845,824
আপনার হার্ডওয়ারের উপর নির্ভর করে কয়েক মিনিট সময় লাগবে।
আমি কিছুটা পরীক্ষার জন্য টেনসরবোর্ড ব্যবহার করেছি, উদাহরণস্বরূপ, আমি শেষ শ্রেণিবদ্ধ স্তরটি বাদ দিয়ে সমস্ত ওজন হিমিয়ে দেওয়ার চেষ্টা করেছি, অপ্টিমাইজার শেখার হার হ্রাস পেয়েছি, কিছু চিত্র উল্টানো, জুমিং এবং সাধারণ বৃদ্ধির ব্যবহার করেছি, এখানে একটি স্ক্রিনশট রয়েছে:
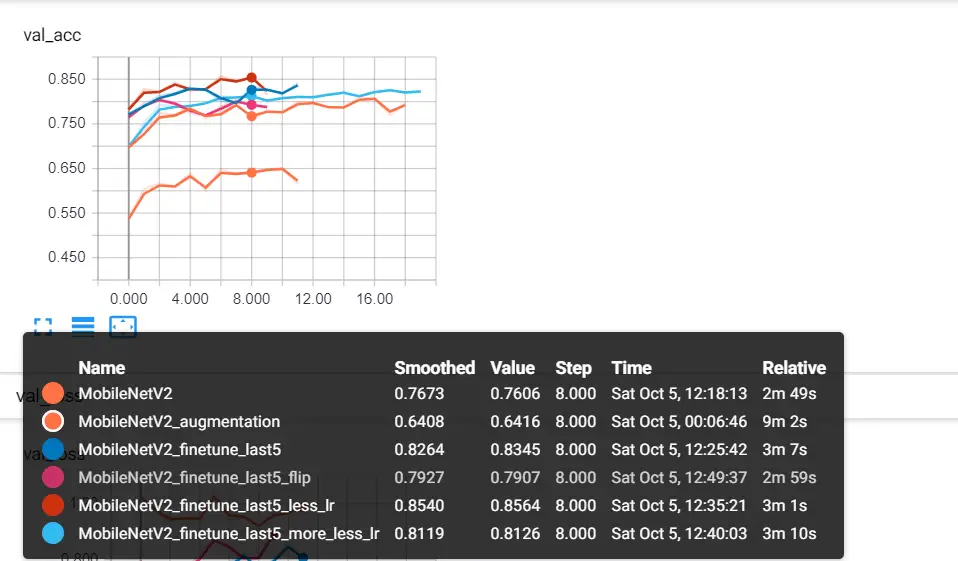
মোবাইলনেটভি 2 এমন মডেল ছিল যা আমি তার সমস্ত ওজন হিমিয়ে ফেলেছিলাম (অবশ্যই শেষ 5 ইউনিটের ঘন স্তর ব্যতীত)।
মোবাইল নেটভি 2_অগমেন্টেশন কিছু চিত্রের বর্ধন ব্যবহার করে।
MobileNetV2_finetune_last5 আমরা যে মডেলটি ব্যবহার করছি তা সঠিকভাবে জানেন, যা মোবাইলনেটভি 2 মডেলের শেষ 4 স্তর হিম করে না ।
মোবাইলনেটভি 2_ফিনেটিউন_লাস্ট 5_হীন_ এলআর প্রায় 86% নির্ভুলতার জন্য প্রভাবশালী ছিল, কারণ আপনি একবার প্রশিক্ষিত ওজন হিমায়িত না করার পরে, আপনার শেখার হার হ্রাস করতে হবে যাতে আপনি ধীরে ধীরে আপনার ডাটাसेटকে ওজনগুলি সামঞ্জস্য করতে পারেন। এটি 0.0005 শেখার হার সহ একটি অ্যাডাম অপ্টিমাইজার ছিল ।
দ্রষ্টব্য : শিক্ষার হারটি সংশোধন করতে, আপনি কেরাস.পটিমাইজার প্যাকেজ থেকে অ্যাডাম অপ্টিমাইজারটি আমদানি করতে পারেন এবং তারপরে অপ্টিমাইজার = অ্যাডাম (এলআর = 0.0005) পরামিতি দিয়ে মডেলটি সংকলন করতে পারেন ।
মডেল পরীক্ষা করা হচ্ছে
# load the data generators
train_generator, validation_generator, class_names = load_data()
# constructs the model
model = create_model(input_shape=IMAGE_SHAPE)
# load the optimal weights
model.load_weights("results/MobileNetV2_finetune_last5_less_lr-loss-0.45-acc-0.86.h5")
validation_steps_per_epoch = np.ceil(validation_generator.samples / batch_size)
# print the validation loss & accuracy
evaluation = model.evaluate_generator(validation_generator, steps=validation_steps_per_epoch, verbose=1)
print("Val loss:", evaluation[0])
print("Val Accuracy:", evaluation[1])
অনুকূল ওজন ব্যবহার করার বিষয়টি নিশ্চিত করুন, এটির যা হ্রাস এবং উচ্চতর নির্ভুলতা রয়েছে।
আউটপুট:
23/23 [==============================] - 6s 264ms/step
Val loss: 0.5659930361524
Val Accuracy: 0.8166894659134987
ওকি, এল এট কিছুটা ভিজ্যুয়ালাইজ করে, আমরা এর পূর্বাভাসযুক্ত এবং সঠিক লেবেল সহ চিত্রগুলির একটি সম্পূর্ণ ব্যাচ প্লট করতে চলেছি:
# get a random batch of images
image_batch, label_batch = next(iter(validation_generator))
# turn the original labels into human-readable text
label_batch = [class_names[np.argmax(label_batch[i])] for i in range(batch_size)]
# predict the images on the model
predicted_class_names = model.predict(image_batch)
predicted_ids = [np.argmax(predicted_class_names[i]) for i in range(batch_size)]
# turn the predicted vectors to human readable labels
predicted_class_names = np.array([class_names[id] for id in predicted_ids])
# some nice plotting
plt.figure(figsize=(10,9))
for n in range(30):
plt.subplot(6,5,n+1)
plt.subplots_adjust(hspace = 0.3)
plt.imshow(image_batch[n])
if predicted_class_names[n] == label_batch[n]:
color = "blue"
title = predicted_class_names[n].title()
else:
color = "red"
title = f"{predicted_class_names[n].title()}, correct:{label_batch[n]}"
plt.title(title, color=color)
plt.axis('off')
_ = plt.suptitle("Model predictions (blue: correct, red: incorrect)")
plt.show()
একবার চালানোর পরে আপনি এরকম কিছু পাবেন:

অসাধারণ! আপনি দেখতে পাচ্ছেন, ৩০ টি চিত্রের মধ্যে ২৫ টি সঠিকভাবে পূর্বাভাস দেওয়া হয়েছিল, এটি বেশ ভাল ফলাফল, কারণ কিছু ফুলের চিত্রগুলি কিছুটা অস্পষ্ট।
ঠিক আছে, এটা। এই টিউটোরিয়ালে, আপনি আবিষ্কার করেছিলেন কীভাবে আপনি পাইথনের টেনসরফ্লো এবং কেরাস ব্যবহার করে অত্যাধুনিক মডেলগুলি দ্রুত বিকাশ করতে এবং ব্যবহার করতে ট্রান্সফার লার্নিং ব্যবহার করতে পারেন।
যদিও প্রকৃত বিশ্বে এটি ইমেজ শ্রেণিবদ্ধ মডেলগুলি স্ক্র্যাচ থেকে প্রশিক্ষণের পরামর্শ দেওয়া হয়নি (বিভিন্ন ধরণের চিত্র যেমন মানুষের স্কিন ইত্যাদি বাদে), আমার একটি টিউটোরিয়াল রয়েছে যা এটি পরীক্ষা করে দেখুন: কীভাবে একটি চিত্র শ্রেণিবদ্ধ করবেন? পাইথনে কেরাস ব্যবহার করে।
আমি আপনাকে উল্লিখিত অন্যান্য মডেলগুলি ব্যবহার করতে উত্সাহিত করছি, সেগুলিও সুর করার চেষ্টা করুন, শুভকামনা!
এখানে আরও কিছু রিডিং রয়েছে:
- সিএস 231 এন দ্বারা স্থানান্তর লার্নিং ।
- কুকুর এবং বিড়ালের ফটো কীভাবে শ্রেণিবদ্ধ করা যায় ।
- পাইথনে কেরাস ব্যবহার করে কীভাবে স্প্যাম শ্রেণিবদ্ধ করা যায় ।
Code for How to Use Transfer Learning for Image Classification using Keras in Python
You can also view the full code on github.
train.py
import tensorflow as tf
from keras.models import Model
from keras.applications import MobileNetV2, ResNet50, InceptionV3 # try to use them and see which is better
from keras.layers import Dense
from keras.callbacks import ModelCheckpoint, TensorBoard
from keras.utils import get_file
from keras.preprocessing.image import ImageDataGenerator
import os
import pathlib
import numpy as np
batch_size = 32
num_classes = 5
epochs = 10
IMAGE_SHAPE = (224, 224, 3)
def load_data():
"""This function downloads, extracts, loads, normalizes and one-hot encodes Flower Photos dataset"""
# download the dataset and extract it
data_dir = get_file(origin='https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz',
fname='flower_photos', untar=True)
data_dir = pathlib.Path(data_dir)
# count how many images are there
image_count = len(list(data_dir.glob('*/*.jpg')))
print("Number of images:", image_count)
# get all classes for this dataset (types of flowers) excluding LICENSE file
CLASS_NAMES = np.array([item.name for item in data_dir.glob('*') if item.name != "LICENSE.txt"])
# roses = list(data_dir.glob('roses/*'))
# 20% validation set 80% training set
image_generator = ImageDataGenerator(rescale=1/255, validation_split=0.2)
# make the training dataset generator
train_data_gen = image_generator.flow_from_directory(directory=str(data_dir), batch_size=batch_size,
classes=list(CLASS_NAMES), target_size=(IMAGE_SHAPE[0], IMAGE_SHAPE[1]),
shuffle=True, subset="training")
# make the validation dataset generator
test_data_gen = image_generator.flow_from_directory(directory=str(data_dir), batch_size=batch_size,
classes=list(CLASS_NAMES), target_size=(IMAGE_SHAPE[0], IMAGE_SHAPE[1]),
shuffle=True, subset="validation")
return train_data_gen, test_data_gen, CLASS_NAMES
def create_model(input_shape):
# load MobileNetV2
model = MobileNetV2(input_shape=input_shape)
# remove the last fully connected layer
model.layers.pop()
# freeze all the weights of the model except the last 4 layers
for layer in model.layers[:-4]:
layer.trainable = False
# construct our own fully connected layer for classification
output = Dense(num_classes, activation="softmax")
# connect that dense layer to the model
output = output(model.layers[-1].output)
model = Model(inputs=model.inputs, outputs=output)
# print the summary of the model architecture
model.summary()
# training the model using rmsprop optimizer
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
return model
if __name__ == "__main__":
# load the data generators
train_generator, validation_generator, class_names = load_data()
# constructs the model
model = create_model(input_shape=IMAGE_SHAPE)
# model name
model_name = "MobileNetV2_finetune_last5"
# some nice callbacks
tensorboard = TensorBoard(log_dir=f"logs/{model_name}")
checkpoint = ModelCheckpoint(f"results/{model_name}" + "-loss-{val_loss:.2f}-acc-{val_acc:.2f}.h5",
save_best_only=True,
verbose=1)
# make sure results folder exist
if not os.path.isdir("results"):
os.mkdir("results")
# count number of steps per epoch
training_steps_per_epoch = np.ceil(train_generator.samples / batch_size)
validation_steps_per_epoch = np.ceil(validation_generator.samples / batch_size)
# train using the generators
model.fit_generator(train_generator, steps_per_epoch=training_steps_per_epoch,
validation_data=validation_generator, validation_steps=validation_steps_per_epoch,
epochs=epochs, verbose=1, callbacks=[tensorboard, checkpoint])
test.py
from train import load_data, create_model, IMAGE_SHAPE, batch_size, np
import matplotlib.pyplot as plt
# load the data generators
train_generator, validation_generator, class_names = load_data()
# constructs the model
model = create_model(input_shape=IMAGE_SHAPE)
# load the optimal weights
model.load_weights("results/MobileNetV2_finetune_last5_less_lr-loss-0.45-acc-0.86.h5")
validation_steps_per_epoch = np.ceil(validation_generator.samples / batch_size)
# print the validation loss & accuracy
evaluation = model.evaluate_generator(validation_generator, steps=validation_steps_per_epoch, verbose=1)
print("Val loss:", evaluation[0])
print("Val Accuracy:", evaluation[1])
# get a random batch of images
image_batch, label_batch = next(iter(validation_generator))
# turn the original labels into human-readable text
label_batch = [class_names[np.argmax(label_batch[i])] for i in range(batch_size)]
# predict the images on the model
predicted_class_names = model.predict(image_batch)
predicted_ids = [np.argmax(predicted_class_names[i]) for i in range(batch_size)]
# turn the predicted vectors to human readable labels
predicted_class_names = np.array([class_names[id] for id in predicted_ids])
# some nice plotting
plt.figure(figsize=(10,9))
for n in range(30):
plt.subplot(6,5,n+1)
plt.subplots_adjust(hspace = 0.3)
plt.imshow(image_batch[n])
if predicted_class_names[n] == label_batch[n]:
color = "blue"
title = predicted_class_names[n].title()
else:
color = "red"
title = f"{predicted_class_names[n].title()}, correct:{label_batch[n]}"
plt.title(title, color=color)
plt.axis('off')
_ = plt.suptitle("Model predictions (blue: correct, red: incorrect)")
plt.show()
0 comments:
Post a Comment