কেরাস ব্যবহার করে কীভাবে পাইথনে একটি চিত্র শ্রেণিবদ্ধ করা যায়
চিত্রের শ্রেণিবিন্যাস কম্পিউটার দর্শনে এমন একটি প্রক্রিয়া বোঝায় যা তার চিত্রের ভিজ্যুয়াল সামগ্রী অনুযায়ী কোনও শ্রেণিবদ্ধ করতে পারে। উদাহরণস্বরূপ, কোনও চিত্রের বিড়াল বা কুকুর রয়েছে কিনা তা জানাতে একটি চিত্র শ্রেণিবদ্ধকরণ অ্যালগরিদম ডিজাইন করা যেতে পারে। কোনও বস্তু সনাক্ত করা মানুষের পক্ষে তুচ্ছ, তবুও শক্তিশালী চিত্রের শ্রেণিবিন্যাস কম্পিউটার ভিশন অ্যাপ্লিকেশনগুলিতে এখনও একটি চ্যালেঞ্জ।
এই টিউটোরিয়ালে, আপনি শিখবেন কীভাবে
CIFAR-10ডেটাসেটে চিত্রগুলি কীভাবে বিমান, কুকুর, বিড়াল এবং অন্যান্য 7 টি বস্তু সমন্বিতভাবে শ্রেণিবদ্ধ করা যায়।
আমরা চিত্রগুলি এবং লেবেলগুলি প্রিপ্রোসেস করব, তারপরে সমস্ত প্রশিক্ষণের নমুনায় একটি কনভোলশনাল নিউরাল নেটওয়ার্ক প্রশিক্ষণ দেব । চিত্রগুলি স্বাভাবিক করার প্রয়োজন হবে এবং লেবেলগুলিকে এক-হট এনকোড করা দরকার ।
প্রথমে আসুন এই প্রকল্পের প্রয়োজনীয়তাগুলি ইনস্টল করুন:
pip3 install keras numpy matplotlib tensorflow
উদাহরণস্বরূপ, একটি খালি অজগর ফাইলটি খুলুন এবং এটিকে ট্রেন.পি কল করুন এবং অনুসরণ করুন। কেরাস আমদানি:
from keras.datasets import cifar10 # importing the dataset from keras
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras.callbacks import ModelCheckpoint, TensorBoard
from keras.utils import to_categorical
import osহাইপার পরামিতি
আমি বিভিন্ন পরামিতি নিয়ে পরীক্ষা-নিরীক্ষা করেছি এবং এটি সর্বোত্তম হিসাবে খুঁজে পেয়েছি:
# hyper-parameters
batch_size = 64
# 10 categories of images (CIFAR-10)
num_classes = 10
# number of training epochs
epochs = 30
num_class কেবল শ্রেণিবদ্ধের জন্য শ্রেণীর সংখ্যা বোঝায়, এক্ষেত্রে সিআইএফএআর -10 শুধুমাত্র 10 বিভাগের চিত্র রয়েছে।
সিআইএফএআর -10 ডেটাসেট বোঝা এবং লোড হচ্ছে
- ডেটাসেটে 10 টি শ্রেণির চিত্র রয়েছে যা এর লেবেলগুলি 0 থেকে 9 অবধি:
- 0 : বিমান।
- 1 : অটোমোবাইল।
- 2 : পাখি।
- 3 : বিড়াল।
- 4 : হরিণ।
- 5 : কুকুর।
- 6 : ব্যাঙ
- 7 : ঘোড়া।
- 8 : জাহাজ
- 9 : ট্রাক।
- প্রশিক্ষণের ডেটার জন্য 50000 নমুনা এবং ডেটা পরীক্ষার জন্য 10000 নমুনা।
- প্রতিটি নমুনা 32x32x3 পিক্সেলের একটি চিত্র (প্রস্থ এবং 32 এবং 3 গভীরতার উচ্চতা যা আরজিবি মান।
আসুন এটি লোড করুন:
def load_data():
"""This function loads CIFAR-10 dataset, normalized, and labels one-hot encoded"""
# loading the CIFAR-10 dataset, splitted between train and test sets
(X_train, y_train), (X_test, y_test) = cifar10.load_data()
print("Training samples:", X_train.shape[0])
print("Testing samples:", X_test.shape[0])
print(f"Images shape: {X_train.shape[1:]}")
# converting image labels to binary class matrices
y_train = to_categorical(y_train, num_classes)
y_test = to_categorical(y_test, num_classes)
# convert to floats instead of int, so we can divide by 255
X_train = X_train.astype("float32")
X_test = X_test.astype("float32")
X_train /= 255
X_test /= 255
return (X_train, y_train), (X_test, y_test)
এই ফাংশনটি ডেটাसेटকে লোড করে যা অন্তর্নির্মিত কেরাস, কিছু পরিসংখ্যান মুদ্রণ করে এবং তারপরে:
- To_categorical ফাংশনটি ব্যবহার করে একটি-হট এনকোড লেবেল : এই প্রক্রিয়াটি সত্যই গুরুত্বপূর্ণ কারণ এটি লেবেলগুলিকে 10 সংখ্যার ভেক্টর হিসাবে সক্ষম করে তাই এটি নিউরাল নেটওয়ার্কের জন্য উপযুক্ত for উদাহরণস্বরূপ, 7 টির মান সহ একটি ঘোড়া এটিকে এনকোড করা হবে: [0, 0, 0, 0, 0, 0, 0, 1, 0, 0] ।
- চিত্রগুলিকে সাধারণীকরণ করা: যেহেতু নিউরাল নেটওয়ার্কগুলি প্রশিক্ষণের জন্য 0 থেকে 255 পিক্সেলের সংখ্যাগুলি খুব বড়, তাই আমরা এই পিক্সেলগুলিকে 0 থেকে 1 এর মধ্যে রাখতে স্বাভাবিক করব।
মডেল নির্মাণ
নিম্নলিখিত মডেল ব্যবহার করা হবে:
def create_model(input_shape):
# building the model
model = Sequential()
model.add(Conv2D(filters=32, kernel_size=(3, 3), padding="same", input_shape=input_shape))
model.add(Activation("relu"))
model.add(Conv2D(filters=32, kernel_size=(3, 3), padding="same"))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(filters=64, kernel_size=(3, 3), padding="same"))
model.add(Activation("relu"))
model.add(Conv2D(filters=64, kernel_size=(3, 3), padding="same"))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(filters=128, kernel_size=(3, 3), padding="same"))
model.add(Activation("relu"))
model.add(Conv2D(filters=128, kernel_size=(3, 3), padding="same"))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
# flattening the convolutions
model.add(Flatten())
# fully-connected layer
model.add(Dense(1024))
model.add(Activation("relu"))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation="softmax"))
# print the summary of the model architecture
model.summary()
# training the model using rmsprop optimizer
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
return model
এটি সর্বাধিক পুলিং এবং আরএলইউ অ্যাক্টিভেশন ফাংশন সহ 2 কনভনেটসের 3 স্তর এবং তারপরে 1024 ইউনিটের সাথে সম্পূর্ণ যুক্ত। এটি তুলনামূলকভাবে একটি ছোট মডেল যা রজনেট 50 বা এক্সসেপশনকে তুলনা করে যা অতুলনীয় । আপনি যদি গভীর শিক্ষণ বিশেষজ্ঞদের দ্বারা তৈরি এমন মডেলগুলি ব্যবহার করতে অনুভব করেন তবে আপনাকে স্থানান্তর শিখন ব্যবহার করতে হবে, এই টিউটোরিয়ালটি পরীক্ষা করে দেখুন ।
মডেল প্রশিক্ষণ
এখন, মডেলটি প্রশিক্ষণ দিন:
if __name__ == "__main__":
# load the data
(X_train, y_train), (X_test, y_test) = load_data()
# constructs the model
model = create_model(input_shape=X_train.shape[1:])
# some nice callbacks
tensorboard = TensorBoard(log_dir="logs/cifar10-model-v1")
checkpoint = ModelCheckpoint("results/cifar10-loss-{val_loss:.2f}-acc-{val_acc:.2f}.h5",
save_best_only=True,
verbose=1)
# make sure results folder exist
if not os.path.isdir("results"):
os.mkdir("results")
# train
model.fit(X_train, y_train,
batch_size=batch_size,
epochs=epochs,
validation_data=(X_test, y_test),
callbacks=[tensorboard, checkpoint],
shuffle=True)
ডেটা লোড করে এবং মডেলটি তৈরি করার পরে, প্রশিক্ষণে আমাদের সহায়তা করার জন্য আমি কয়েকটি কলব্যাক ব্যবহার করেছি, মডেলচেকপয়েন্টটি প্রতিবার একটি সর্বোত্তম পয়েন্ট পৌঁছানোর পরে মডেলটি সংরক্ষণ করবে এবং টেনসরবোর্ড প্রতিটি পর্বের যথাযথতা এবং ক্ষতির সন্ধান করবে এবং আমাদের সুন্দর প্রদান করবে nice কল্পনা।
এটি চালান, আপনার সিপিইউ / জিপিইউর উপর নির্ভর করে এটি শেষ হতে কয়েক মিনিট সময় লাগবে।
আপনি এর অনুরূপ ফলাফল পাবেন:
Epoch 1/30
50000/50000 [==============================] - 26s 520us/step - loss: 1.6408 - acc: 0.3937 - val_loss: 1.2063 - val_acc: 0.5559
Epoch 00001: val_loss improved from inf to 1.20628, saving model to results/cifar10-loss-1.21-acc-0.56.h5
Epoch 2/30
50000/50000 [==============================] - 26s 525us/step - loss: 1.1885 - acc: 0.5716 - val_loss: 0.9982 - val_acc: 0.6473
চূড়ান্ত যুগের সমস্ত উপায়:
Epoch 29/30
50000/50000 [==============================] - 27s 534us/step - loss: 0.4225 - acc: 0.8539 - val_loss: 0.5863 - val_acc: 0.8093
Epoch 00029: val_loss did not improve from 0.56407
Epoch 30/30
50000/50000 [==============================] - 27s 549us/step - loss: 0.4205 - acc: 0.8517 - val_loss: 0.5782 - val_acc: 0.8154
Epoch 00030: val_loss did not improve from 0.56407
এখন টেনসরবোর্ড খোলার জন্য, আপনাকে কেবলমাত্র টার্মিনালটিতে এই কমান্ডটি লিখতে হবে বা বর্তমান ডিরেক্টরিতে কমান্ড প্রম্পট লিখতে হবে:
tensorboard --logdir="logs"
একটি ব্রাউজার ট্যাব খুলুন এবং লোকালহোস্ট টাইপ করুন : 6006 , আপনাকে টেনসরবোর্ডে পুনঃনির্দেশ করা হবে, এখানে আমার ফলাফল:
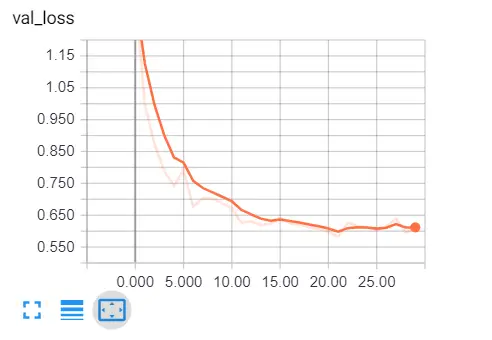
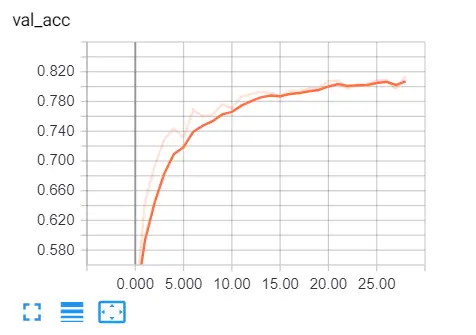
স্পষ্টতই আমরা সঠিক পথে রয়েছি, বৈধতা হ্রাস হ্রাস পাচ্ছে, এবং নির্ভুলতা সমস্ত উপায়ে প্রায় 81% বৃদ্ধি পাচ্ছে । দারুণ!
মডেল পরীক্ষা করা হচ্ছে
প্রশিক্ষণ শেষ হয়ে গেলে, আপনি নীচের চিত্রের মতো ফলাফলের ফোল্ডারে সংরক্ষিত বিভিন্ন মডেলের ওজন দেখতে পাবেন:
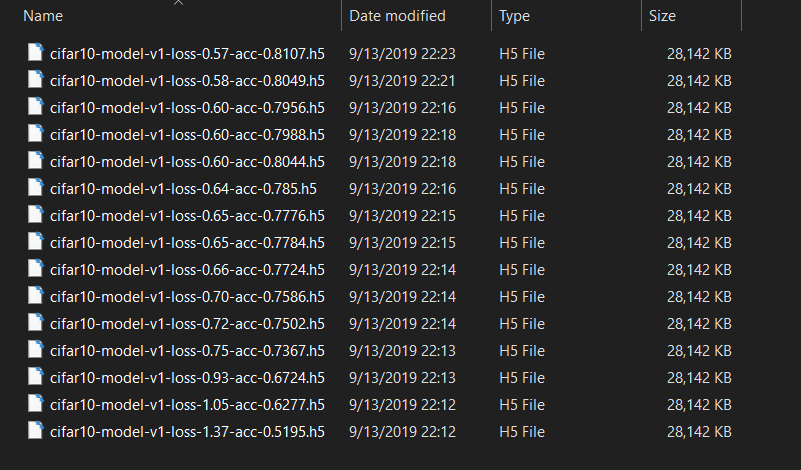 স্পষ্টতই, আমরা অনুকূলটি বেছে নেব , যা সিফার 10-মডেল-ভি 1-লস-0.57-এ্যাক-0.8107.h5 (কমপক্ষে আমার ক্ষেত্রে, সর্বাধিক নির্ভুলতা বা সর্বনিম্ন ক্ষতি চয়ন করুন)।
স্পষ্টতই, আমরা অনুকূলটি বেছে নেব , যা সিফার 10-মডেল-ভি 1-লস-0.57-এ্যাক-0.8107.h5 (কমপক্ষে আমার ক্ষেত্রে, সর্বাধিক নির্ভুলতা বা সর্বনিম্ন ক্ষতি চয়ন করুন)।
টেস্ট.পি নামে একটি নতুন অজগর ফাইল খুলুন এবং অনুসরণ করুন।
প্রয়োজনীয় ইউটিলিটিগুলি আমদানি করা:
from train import load_data
from keras.models import load_model
import matplotlib.pyplot as plt
import numpy as np
আসুন একটি পাইথন অভিধান তৈরি করুন যা ডেটাসেটের সাথে সম্পর্কিত লেবেলে প্রতিটি পূর্ণসংখ্যার মানকে মানচিত্র করে:
# CIFAR-10 classes
categories = {
0: "airplane",
1: "automobile",
2: "bird",
3: "cat",
4: "deer",
5: "dog",
6: "frog",
7: "horse",
8: "ship",
9: "truck"
}
পরীক্ষার ডেটা এবং মডেলটি লোড হচ্ছে:
# load the testing set
(_, _), (X_test, y_test) = load_data()
# load the model with optimal weights
model = load_model("results/cifar10-loss-0.58-acc-0.81.h5")
মূল্যায়ন:
# evaluation
loss, accuracy = model.evaluate(X_test, y_test)
print("Test accuracy:", accuracy*100, "%")
আসুন একটি এলোমেলো ইমেজ নেওয়া এবং একটি ভবিষ্যদ্বাণী করা যাক:
# get prediction for this image
sample_image = X_test[7500]
prediction = np.argmax(model.predict(sample_image.reshape(-1, *sample_image.shape))[0])
print(categories[prediction])
মনে আছে কখন আমরা লেবেলগুলিকে হট-এনকোড করেছি? এখানে, আমাদের এটি 10 দৈর্ঘ্যের ভেক্টর থেকে একটি সংখ্যায় বিপরীত করা দরকার, এটি এনপি.আরগম্যাক্স শুরুতে করছে। এর পরে, আমরা মানব পাঠযোগ্য লেবেল পেতে এটি আমাদের অভিধানে ম্যাপ করি, এখানে আমার আউটপুট:
10000/10000 [==============================] - 3s 331us/step
Test accuracy: 81.17999999999999 %
frog
মডেলটি বলছে এটি একটি ব্যাঙ, আসুন এটি পরীক্ষা করুন:
# show the image
plt.axis('off')
plt.imshow(sample_image)
plt.show()
ফলাফল: খুব ছোট ব্যাঙ! মডেল ঠিক ছিল!
উপসংহার
ঠিক আছে, আমরা এই টিউটোরিয়ালটি দিয়ে শেষ করেছি, 81% এই ছোট সিএনএন এর পক্ষে খারাপ নয় , আমি আপনাকে উচ্চতর পারফরম্যান্স পেতে মডেলটি টিকিয়ে দিতে বা রেজনেট 50 , এক্সপেশন বা অন্যান্য অত্যাধুনিক মডেলগুলি পরীক্ষা করতে উত্সাহিত করি !
যদি আপনি এই মডেলগুলি কীভাবে ব্যবহার করবেন সে সম্পর্কে নিশ্চিত না হন তবে আমার এই সম্পর্কে একটি টিউটোরিয়াল রয়েছে: পাইথনের কেরাস ব্যবহার করে চিত্র শ্রেণিবিন্যাসের জন্য স্থানান্তর শেখার কীভাবে ব্যবহার করবেন।
আপনি ভাবতে পারেন যে এই চিত্রগুলি এত সহজ, 32x32 গ্রিডটি আসল পৃথিবীটি কীভাবে তা নয়, চিত্রগুলি এর মতো সহজ নয় , এগুলিতে প্রায়শই অনেকগুলি অবজেক্ট, জটিল নিদর্শন ইত্যাদি থাকে। ফলস্বরূপ, প্রায়শই কোনও শ্রেণিবদ্ধকরণ কৌশলগুলিতে যাওয়ার আগে চিত্র বিভাজন পদ্ধতি যেমন কনট্যুর সনাক্তকরণ বা কে-মাইন ক্লাস্টারিং বিভাজনগুলি ব্যবহার করা একটি সাধারণ অভ্যাস ।
Code for How to Make an Image Classifier in Python using Keras
You can also view the full code on github.
train.py
from keras.datasets import cifar10 # importing the dataset from keras
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras.callbacks import ModelCheckpoint, TensorBoard
from keras.utils import to_categorical
import os
# hyper-parameters
batch_size = 64
# 10 categories of images (CIFAR-10)
num_classes = 10
# number of training epochs
epochs = 30
def create_model(input_shape):
# building the model
model = Sequential()
model.add(Conv2D(filters=32, kernel_size=(3, 3), padding="same", input_shape=input_shape))
model.add(Activation("relu"))
model.add(Conv2D(filters=32, kernel_size=(3, 3), padding="same"))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(filters=64, kernel_size=(3, 3), padding="same"))
model.add(Activation("relu"))
model.add(Conv2D(filters=64, kernel_size=(3, 3), padding="same"))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(filters=128, kernel_size=(3, 3), padding="same"))
model.add(Activation("relu"))
model.add(Conv2D(filters=128, kernel_size=(3, 3), padding="same"))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
# flattening the convolutions
model.add(Flatten())
# fully-connected layers
model.add(Dense(1024))
model.add(Activation("relu"))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation="softmax"))
# print the summary of the model architecture
model.summary()
# training the model using rmsprop optimizer
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
return model
def load_data():
"""
This function loads CIFAR-10 dataset, normalized, and labels one-hot encoded
"""
# loading the CIFAR-10 dataset, splitted between train and test sets
(X_train, y_train), (X_test, y_test) = cifar10.load_data()
print("Training samples:", X_train.shape[0])
print("Testing samples:", X_test.shape[0])
print(f"Images shape: {X_train.shape[1:]}")
# converting image labels to binary class matrices
y_train = to_categorical(y_train, num_classes)
y_test = to_categorical(y_test, num_classes)
# convert to floats instead of int, so we can divide by 255
X_train = X_train.astype("float32")
X_test = X_test.astype("float32")
X_train /= 255
X_test /= 255
return (X_train, y_train), (X_test, y_test)
if __name__ == "__main__":
# load the data
(X_train, y_train), (X_test, y_test) = load_data()
# constructs the model
model = create_model(input_shape=X_train.shape[1:])
# some nice callbacks
tensorboard = TensorBoard(log_dir="logs/cifar10-model-v1")
checkpoint = ModelCheckpoint("results/cifar10-loss-{val_loss:.2f}-acc-{val_acc:.2f}.h5",
save_best_only=True,
verbose=1)
# make sure results folder exist
if not os.path.isdir("results"):
os.mkdir("results")
# train
model.fit(X_train, y_train,
batch_size=batch_size,
epochs=epochs,
validation_data=(X_test, y_test),
callbacks=[tensorboard, checkpoint],
shuffle=True)
test.py
from train import load_data
from keras.models import load_model
import matplotlib.pyplot as plt
import numpy as np
# CIFAR-10 classes
categories = {
0: "airplane",
1: "automobile",
2: "bird",
3: "cat",
4: "deer",
5: "dog",
6: "frog",
7: "horse",
8: "ship",
9: "truck"
}
# load the testing set
(_, _), (X_test, y_test) = load_data()
# load the model with optimal weights
model = load_model("results/cifar10-loss-0.58-acc-0.81.h5")
# evaluation
loss, accuracy = model.evaluate(X_test, y_test)
print("Test accuracy:", accuracy*100, "%")
# get prediction for this image
sample_image = X_test[7500]
prediction = np.argmax(model.predict(sample_image.reshape(-1, *sample_image.shape))[0])
print(categories[prediction])
# show the first image
plt.axis('off')
plt.imshow(sample_image)
plt.savefig("frog.png")
plt.show()
0 comments:
Post a Comment