ইমেল স্প্যাম বা জাঙ্ক ইমেলটি অবাঞ্ছিত, অনিবার্য এবং পুনরাবৃত্ত বার্তা ইমেলের পাঠানো। 1990 এর দশকের গোড়ার দিকে ইমেল স্প্যাম বৃদ্ধি পেয়েছে এবং 2014 এর মধ্যে অনুমান করা হয়েছিল যে এটি প্রেরিত 90% ইমেল বার্তা রয়েছে।
যেহেতু আমাদের সকলেরই আমাদের ইনবক্সগুলি পূরণ করার স্প্যাম ইমেলের সমস্যা রয়েছে তাই এই টিউটোরিয়ালে আমরা কেরাসে এমন একটি মডেল তৈরি করব যা স্প্যাম এবং বৈধ ইমেলের মধ্যে পার্থক্য করতে পারে।
সূচি তালিকা:
- নির্ভরতা ইনস্টল করা এবং আমদানি করা
- ডেটাসেট লোড হচ্ছে
- ডেটাসেট প্রস্তুত করা হচ্ছে
- মডেল বিল্ডিং
- মডেল প্রশিক্ষণ
- মডেল মূল্যায়ন
1. নির্ভরতা ইনস্টল করা এবং আমদানি করা
আমাদের প্রথমে কিছু নির্ভরতা ইনস্টল করতে হবে:
pip3 install keras sklearn tqdm numpy keras_metrics tensorflow==1.14.0
এখন একটি ইন্টারেক্টিভ শেল বা একটি বৃহত্তর নোটবুক খুলুন এবং আমদানি করুন:
import tqdm
import numpy as np
import keras_metrics # for recall and precision metrics
from keras.preprocessing.sequence import pad_sequences
from keras.preprocessing.text import Tokenizer
from keras.layers import Embedding, LSTM, Dropout, Dense
from keras.models import Sequential
from keras.utils import to_categorical
from keras.callbacks import ModelCheckpoint, TensorBoard
from sklearn.model_selection import train_test_split
import time
import numpy as np
import pickle
আসুন কিছু হাইপার-প্যারামিটার সংজ্ঞা দিন:
SEQUENCE_LENGTH = 100 # the length of all sequences (number of words per sample)
EMBEDDING_SIZE = 100 # Using 100-Dimensional GloVe embedding vectors
TEST_SIZE = 0.25 # ratio of testing set
BATCH_SIZE = 64
EPOCHS = 20 # number of epochs
# to convert labels to integers and vice-versa
label2int = {"ham": 0, "spam": 1}
int2label = {0: "ham", 1: "spam"}
এই পরামিতিগুলির অর্থ কী তা আপনি নিশ্চিত না থাকলে চিন্তা করবেন না, আমরা পরে সেগুলি সম্পর্কে আমাদের মডেলটি তৈরি করব we
২. ডেটাসেট লোড হচ্ছে
আমরা যে ডেটাসেটটি ব্যবহার করব তা হ'ল এসএমএস স্প্যাম কালেকশন ডেটাসেট , ডাউনলোড, এক্সট্রাক্ট এবং এটিকে "ডেটা" নামে একটি ফোল্ডারে রাখুন , আসুন যে ফাংশনটি এটি লোড করে সেটি নির্ধারণ করুন:
def load_data():
"""
Loads SMS Spam Collection dataset
"""
texts, labels = [], []
with open("data/SMSSpamCollection") as f:
for line in f:
split = line.split()
labels.append(split[0].strip())
texts.append(' '.join(split[1:]).strip())
return texts, labels
ডেটাসেটটি একটি একক ফাইলে রয়েছে, প্রতিটি লাইন একটি ডেটা নমুনার সাথে মিলে যায়, প্রথম শব্দটি হ'ল লেবেল এবং বাকীটি প্রকৃত ইমেল সামগ্রী, সেই কারণেই আমরা বিভাজন হিসাবে [0] এবং সামগ্রীটিকে বিভক্ত হিসাবে [1: ] ।
ফাংশনটি কল করা:
# load the data
X, y = load_data()৩. ডেটাসেট প্রস্তুত করা হচ্ছে
এখন, আমাদের প্রতিটি পাঠ্যকে পূর্ণসংখ্যার অনুক্রমে পরিণত করে পাঠ্য কর্পাসকে ভেক্টরাইজ করার একটি উপায় প্রয়োজন, আপনি এখন ভাবছেন যে পাঠ্যটি কেন পূর্ণসংখ্যার ক্রমিকায় পরিণত করতে হবে, ঠিক আছে, মনে রাখবেন আমরা পাঠ্যটি ফিড করতে যাচ্ছি নিউরাল নেটওয়ার্কে, একটি নিউরাল নেটওয়ার্ক কেবল সংখ্যা বোঝে। আরও স্পষ্টভাবে, পূর্ণসংখ্যার একটি নির্দিষ্ট দৈর্ঘ্যের ক্রম।
তবে আমরা এই সমস্ত কিছু করার আগে, আমাদের বিরামচিহ্নগুলি মুছে ফেলা, সমস্ত অক্ষর, ইত্যাদি ছোট ছোট করে ইত্যাদি দ্বারা এই কর্পসটি পরিষ্কার করা দরকার সৌভাগ্যক্রমে আমাদের জন্য কেরাসের একটি বিল্টিন ক্লাস রয়েছে কেরাস.প্রপ্রসেসিং.টেক্সট. টোকেনাইজার () যা কিছু লাইনগুলিতে সমস্ত কিছু করে কোড:
# Text tokenization
# vectorizing text, turning each text into sequence of integers
tokenizer = Tokenizer()
tokenizer.fit_on_texts(X)
# convert to sequence of integers
X = tokenizer.texts_to_sequences(X)
আসুন প্রথম নমুনা মুদ্রণের চেষ্টা করুন:
In [4]: print(X[0])
[49, 472, 4436, 843, 756, 659, 64, 8, 1328, 87, 123, 352, 1329, 148, 2996, 1330, 67, 58, 4437, 144]
সংখ্যার একগুচ্ছ, প্রতিটি পূর্ণসংখ্যার শব্দভাণ্ডারের একটি শব্দের সাথে মিলে যায়, নিউরাল নেটওয়ার্কটি যেভাবেই প্রয়োজন। তবে, নমুনাগুলির একই দৈর্ঘ্য নেই, আমাদের একটি নির্দিষ্ট দৈর্ঘ্যের ক্রম থাকার একটি উপায় প্রয়োজন।
ফলস্বরূপ, আমরা কেরাস.প্রিপ্রসেসিং.সেক্সেন্স.প্যাড_সেক্সেন্সস () ফাংশনটি ব্যবহার করছি যা জিরোসের সাথে প্রতিটি অনুক্রমের শুরুতে প্যাড সিকোয়েন্সগুলি:
# convert to numpy arrays
X = np.array(X)
y = np.array(y)
# pad sequences at the beginning of each sequence with 0's
# for example if SEQUENCE_LENGTH=4:
# [[5, 3, 2], [5, 1, 2, 3], [3, 4]]
# will be transformed to:
# [[0, 5, 3, 2], [5, 1, 2, 3], [0, 0, 3, 4]]
X = pad_sequences(X, maxlen=SEQUENCE_LENGTH)
যেমনটি আপনি মনে করতে পারেন, আমরা SEQUENCE_LENGTH 100 এ সেট করেছি , এইভাবে, সমস্ত সিকোয়েন্সের দৈর্ঘ্য 100 হয়।
এখন আমাদের লেবেলগুলিও পাঠ্য, তবে আমরা এখানে একটি ভিন্ন পন্থা তৈরি করব, যেহেতু লেবেলগুলি কেবল "স্প্যাম" এবং "হ্যাম" , তাই আমাদের সেগুলিকে এক-হট এনকোড করা দরকার :
# One Hot encoding labels
# [spam, ham, spam, ham, ham] will be converted to:
# [1, 0, 1, 0, 1] and then to:
# [[0, 1], [1, 0], [0, 1], [1, 0], [0, 1]]
y = [ label2int[label] for label in y ]
y = to_categorical(y)
আমরা এখানে keras.utils.to_categorial () ব্যবহার করেছি , যা এর নাম থেকে যা বোঝা যায় তা করে, আসুন লেবেলের প্রথম নমুনা মুদ্রণের চেষ্টা করি:
In [7]: print(y[0])
[1.0, 0.0]
তার মানে প্রথম নমুনা হ্যাম।
এর পরে, আসুন পরিবর্তন ও বিভাজন প্রশিক্ষণ এবং পরীক্ষার ডেটা:
# split and shuffle
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=TEST_SIZE, random_state=7)4. মডেল বিল্ডিং
এখন আমরা আমাদের মডেলটি তৈরির জন্য প্রস্তুত, সাধারণ আর্কিটেকচারটি নিম্নলিখিত চিত্রটিতে দেখানো হয়েছে:
 প্রথম স্তরটি একটি প্রাক-প্রশিক্ষিত এম্বেডিং স্তর যা প্রতিটি শব্দেরকে আসল সংখ্যার এন-ডাইমেনশনাল ভেক্টরকে ম্যাপ করে ( EMBEDDING_SIZE এই ভেক্টরের আকারের সাথে সামঞ্জস্য রাখে, এই ক্ষেত্রে 100)। দুটি শব্দ যার সাথে একই অর্থ রয়েছে খুব কাছের ভেক্টর থাকে to
প্রথম স্তরটি একটি প্রাক-প্রশিক্ষিত এম্বেডিং স্তর যা প্রতিটি শব্দেরকে আসল সংখ্যার এন-ডাইমেনশনাল ভেক্টরকে ম্যাপ করে ( EMBEDDING_SIZE এই ভেক্টরের আকারের সাথে সামঞ্জস্য রাখে, এই ক্ষেত্রে 100)। দুটি শব্দ যার সাথে একই অর্থ রয়েছে খুব কাছের ভেক্টর থাকে to
দ্বিতীয় স্তরটি এলএসটিএম ইউনিটগুলির সাথে একটি পুনরাবৃত্ত নিউরাল নেটওয়ার্ক । অবশেষে, আউটপুট স্তরটি 2 টি নিউরন যা প্রতিটি সফটম্যাক্স অ্যাক্টিভেশন ফাংশনের সাথে "স্প্যাম" বা "হ্যাম" এর সাথে সম্পর্কিত ।
আসুন প্রাক প্রশিক্ষিত এম্বেডিং ভেক্টরগুলি লোড করার জন্য একটি ফাংশন লিখে শুরু করি:
def get_embedding_vectors(tokenizer, dim=100):
embedding_index = {}
with open(f"data/glove.6B.{dim}d.txt", encoding='utf8') as f:
for line in tqdm.tqdm(f, "Reading GloVe"):
values = line.split()
word = values[0]
vectors = np.asarray(values[1:], dtype='float32')
embedding_index[word] = vectors
word_index = tokenizer.word_index
embedding_matrix = np.zeros((len(word_index)+1, dim))
for word, i in word_index.items():
embedding_vector = embedding_index.get(word)
if embedding_vector is not None:
# words not found will be 0s
embedding_matrix[i] = embedding_vector
return embedding_matrix
দ্রষ্টব্য: এই ফাংশনটি সঠিকভাবে চালানোর জন্য আপনাকে গ্লোভিও ডাউনলোড করতে হবে , নিষ্কাশন করতে হবে এবং "ডেটা" ফোল্ডারটি লাগাতে হবে, আমরা এখানে 100-মাত্রিক ভেক্টর ব্যবহার করব।
আসুন ফাংশনটি সংজ্ঞায়িত করি যা মডেল তৈরি করে:
def get_model(tokenizer, lstm_units):
"""
Constructs the model,
Embedding vectors => LSTM => 2 output Fully-Connected neurons with softmax activation
"""
# get the GloVe embedding vectors
embedding_matrix = get_embedding_vectors(tokenizer)
model = Sequential()
model.add(Embedding(len(tokenizer.word_index)+1,
EMBEDDING_SIZE,
weights=[embedding_matrix],
trainable=False,
input_length=SEQUENCE_LENGTH))
model.add(LSTM(lstm_units, recurrent_dropout=0.2))
model.add(Dropout(0.3))
model.add(Dense(2, activation="softmax"))
# compile as rmsprop optimizer
# aswell as with recall metric
model.compile(optimizer="rmsprop", loss="categorical_crossentropy",
metrics=["accuracy", keras_metrics.precision(), keras_metrics.recall()])
model.summary()
return model
উপরের ফাংশনটি পুরো মডেলটি তৈরি করে, আমরা পূর্ব-প্রশিক্ষিত এম্বেডিং ভেক্টরকে এমবেডিং স্তরে লোড করেছি এবং ট্রেনেবল = ফলস সেট করব, এটি প্রশিক্ষণ প্রক্রিয়া চলাকালীন এমবেডিং ওজনকে হিমায়িত করবে।
আমরা আরএনএন স্তর যুক্ত করার পরে, আমরা একটি 30% ড্রপআউট সুযোগ যুক্ত করেছি, এটি প্রতিটি পুনরাবৃত্তির আগের স্তরটিতে 30% নিউরন হিমায়িত করবে যা আমাদের ওভারফিটিং হ্রাস করতে সহায়তা করবে ।
নোট করুন যে মডেলটি দুর্দান্ত করছে কিনা তা নির্ধারণের জন্য নির্ভুলতা যথেষ্ট নয়, কারণ এই ডেটাসেট ভারসাম্যহীন, কেবলমাত্র কয়েকটি নমুনা স্প্যাম। ফলস্বরূপ, আমরা নির্ভুলতা ব্যবহার করব এবং মেট্রিকগুলি প্রত্যাহার করব ।
আসুন ফাংশন কল:
# constructs the model with 128 LSTM units
model = get_model(tokenizer=tokenizer, lstm_units=128)5. মডেল প্রশিক্ষণ
আমরা প্রায় সেখানে রয়েছি, আমাদের কেবলমাত্র লোড হওয়া ডেটা দিয়ে আমাদের এই মডেলটি প্রশিক্ষণ দিতে হবে:
# initialize our ModelCheckpoint and TensorBoard callbacks
# model checkpoint for saving best weights
model_checkpoint = ModelCheckpoint("results/spam_classifier_{val_loss:.2f}", save_best_only=True,
verbose=1)
# for better visualization
tensorboard = TensorBoard(f"logs/spam_classifier_{time.time()}")
# print our data shapes
print("X_train.shape:", X_train.shape)
print("X_test.shape:", X_test.shape)
print("y_train.shape:", y_train.shape)
print("y_test.shape:", y_test.shape)
# train the model
model.fit(X_train, y_train, validation_data=(X_test, y_test),
batch_size=BATCH_SIZE, epochs=EPOCHS,
callbacks=[tensorboard, model_checkpoint],
verbose=1)
প্রশিক্ষণ শুরু হয়েছে:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_1 (Embedding) (None, 100, 100) 901300
_________________________________________________________________
lstm_1 (LSTM) (None, 128) 117248
_________________________________________________________________
dropout_1 (Dropout) (None, 128) 0
_________________________________________________________________
dense_1 (Dense) (None, 2) 258
=================================================================
Total params: 1,018,806
Trainable params: 117,506
Non-trainable params: 901,300
_________________________________________________________________
X_train.shape: (4180, 100)
X_test.shape: (1394, 100)
y_train.shape: (4180, 2)
y_test.shape: (1394, 2)
Train on 4180 samples, validate on 1394 samples
Epoch 1/20
4180/4180 [==============================] - 9s 2ms/step - loss: 0.1712 - acc: 0.9325 - precision: 0.9524 - recall: 0.9708 - val_loss: 0.1023 - val_acc: 0.9656 - val_precision: 0.9840 - val_recall: 0.9758
Epoch 00001: val_loss improved from inf to 0.10233, saving model to results/spam_classifier_0.10
Epoch 2/20
4180/4180 [==============================] - 8s 2ms/step - loss: 0.0976 - acc: 0.9675 - precision: 0.9765 - recall: 0.9862 - val_loss: 0.0809 - val_acc: 0.9720 - val_precision: 0.9793 - val_recall: 0.9883
প্রশিক্ষণ শেষ:
Epoch 20/20
4180/4180 [==============================] - 8s 2ms/step - loss: 0.0130 - acc: 0.9971 - precision: 0.9973 - recall: 0.9994 - val_loss: 0.0629 - val_acc: 0.9821 - val_precision: 0.9916 - val_recall: 0.98756. মডেল মূল্যায়ন
আসুন আমাদের মডেলটি মূল্যায়ন করুন:
# get the loss and metrics
result = model.evaluate(X_test, y_test)
# extract those
loss = result[0]
accuracy = result[1]
precision = result[2]
recall = result[3]
print(f"[+] Accuracy: {accuracy*100:.2f}%")
print(f"[+] Precision: {precision*100:.2f}%")
print(f"[+] Recall: {recall*100:.2f}%")
আউটপুট:
1394/1394 [==============================] - 1s 569us/step
[+] Accuracy: 98.21%
[+] Precision: 99.16%
[+] Recall: 98.75%
প্রতিটি মেট্রিকের অর্থ এখানে:
- নির্ভুলতা : পূর্বাভাসের শতাংশ যা সঠিক ছিল।
- প্রত্যাহার : স্প্যাম ইমেলের শতকরা যা সঠিকভাবে পূর্বাভাস দেওয়া হয়েছিল।
- যথার্থতা : স্প্যাম হিসাবে শ্রেণীবদ্ধ ইমেলগুলির শতাংশ যা আসলে স্প্যাম ছিল।
গ্রেট! আসুন এটি পরীক্ষা করে দেখুন:
def get_predictions(text):
sequence = tokenizer.texts_to_sequences([text])
# pad the sequence
sequence = pad_sequences(sequence, maxlen=SEQUENCE_LENGTH)
# get the prediction
prediction = model.predict(sequence)[0]
# one-hot encoded vector, revert using np.argmax
return int2label[np.argmax(prediction)]
একটি স্প্যাম ইমেল জাল করা যাক:
text = "Congratulations! you have won 100,000$ this week, click here to claim fast"
print(get_predictions(text))
আউটপুট:
spam
ওকে, আসুন বৈধ হওয়ার চেষ্টা করি:
text = "Hi man, I was wondering if we can meet tomorrow."
print(get_predictions(text))
আউটপুট:
ham
অসাধারণ! এই পদ্ধতিটি বর্তমানের অত্যাধুনিক, প্রশিক্ষণ এবং মডেল পরামিতিগুলির সাথে টিউন করার চেষ্টা করুন এবং দেখুন আপনি এটি উন্নত করতে পারেন কিনা।
প্রশিক্ষণের সময় বিভিন্ন মেট্রিকগুলি দেখতে, আমাদের সেন্টিমিডি বা টার্মিনাল টাইপ করে টেনসরবোর্ডে যেতে হবে:
tensorboard --logdir="logs"
ব্রাউজারে যান এবং "লোকালহোস্ট: 6006" টাইপ করুন এবং বিভিন্ন মেট্রিকগুলিতে যান, এখানে আমার ফলাফল:
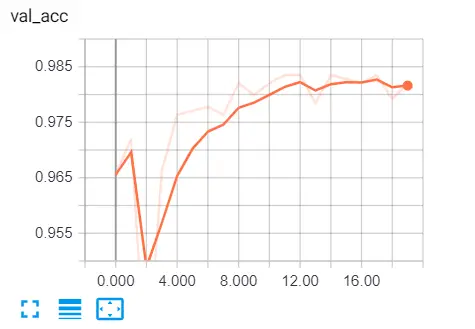
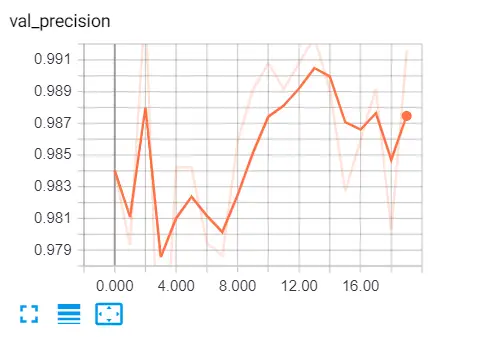
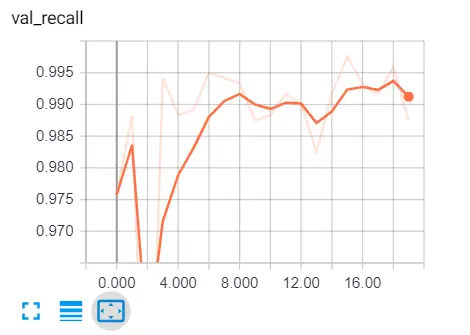
এখানে আরও কিছু রিডিং রয়েছে:
- কেরাসের সাথে ডিপ লার্নিংয়ের জন্য ওয়ার্ড এম্বেডিং স্তরগুলি কীভাবে ব্যবহার করবেন।
- কেরাস ডকুমেন্টেশনে পাঠ্য প্রিপ্রোসেসিং ।
- এলএসটিএম নেটওয়ার্কগুলি বোঝা।
- পাঠ্য শ্রেণিবিন্যাস: এনএলপি মাস্টারির দিকে প্রথম ধাপ
- যথার্থ বনাম পুনরুদ্ধার
পরিশেষে, আমি আপনাকে পুরো কোডটি পরীক্ষা করতে উত্সাহিত করি ।
Code for How to Build a Spam Classifier using Keras in Python
You can also view the full code on github.
utils.py
import tqdm
import numpy as np
from keras.preprocessing.sequence import pad_sequences
from keras.layers import Embedding, LSTM, Dropout, Dense
from keras.models import Sequential
import keras_metrics
SEQUENCE_LENGTH = 100 # the length of all sequences (number of words per sample)
EMBEDDING_SIZE = 100 # Using 100-Dimensional GloVe embedding vectors
TEST_SIZE = 0.25 # ratio of testing set
BATCH_SIZE = 64
EPOCHS = 20 # number of epochs
label2int = {"ham": 0, "spam": 1}
int2label = {0: "ham", 1: "spam"}
def get_embedding_vectors(tokenizer, dim=100):
embedding_index = {}
with open(f"data/glove.6B.{dim}d.txt", encoding='utf8') as f:
for line in tqdm.tqdm(f, "Reading GloVe"):
values = line.split()
word = values[0]
vectors = np.asarray(values[1:], dtype='float32')
embedding_index[word] = vectors
word_index = tokenizer.word_index
# we do +1 because Tokenizer() starts from 1
embedding_matrix = np.zeros((len(word_index)+1, dim))
for word, i in word_index.items():
embedding_vector = embedding_index.get(word)
if embedding_vector is not None:
# words not found will be 0s
embedding_matrix[i] = embedding_vector
return embedding_matrix
def get_model(tokenizer, lstm_units):
"""
Constructs the model,
Embedding vectors => LSTM => 2 output Fully-Connected neurons with softmax activation
"""
# get the GloVe embedding vectors
embedding_matrix = get_embedding_vectors(tokenizer)
model = Sequential()
model.add(Embedding(len(tokenizer.word_index)+1,
EMBEDDING_SIZE,
weights=[embedding_matrix],
trainable=False,
input_length=SEQUENCE_LENGTH))
model.add(LSTM(lstm_units, recurrent_dropout=0.2))
model.add(Dropout(0.3))
model.add(Dense(2, activation="softmax"))
# compile as rmsprop optimizer
# aswell as with recall metric
model.compile(optimizer="rmsprop", loss="categorical_crossentropy",
metrics=["accuracy", keras_metrics.precision(), keras_metrics.recall()])
model.summary()
return model
spam_classifier.py
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.utils import to_categorical
from keras.callbacks import ModelCheckpoint, TensorBoard
from sklearn.model_selection import train_test_split
import time
import numpy as np
import pickle
from utils import get_embedding_vectors, get_model, SEQUENCE_LENGTH, EMBEDDING_SIZE, TEST_SIZE
from utils import BATCH_SIZE, EPOCHS, int2label, label2int
def load_data():
"""
Loads SMS Spam Collection dataset
"""
texts, labels = [], []
with open("data/SMSSpamCollection") as f:
for line in f:
split = line.split()
labels.append(split[0].strip())
texts.append(' '.join(split[1:]).strip())
return texts, labels
# load the data
X, y = load_data()
# Text tokenization
# vectorizing text, turning each text into sequence of integers
tokenizer = Tokenizer()
tokenizer.fit_on_texts(X)
# lets dump it to a file, so we can use it in testing
pickle.dump(tokenizer, open("results/tokenizer.pickle", "wb"))
# convert to sequence of integers
X = tokenizer.texts_to_sequences(X)
print(X[0])
# convert to numpy arrays
X = np.array(X)
y = np.array(y)
# pad sequences at the beginning of each sequence with 0's
# for example if SEQUENCE_LENGTH=4:
# [[5, 3, 2], [5, 1, 2, 3], [3, 4]]
# will be transformed to:
# [[0, 5, 3, 2], [5, 1, 2, 3], [0, 0, 3, 4]]
X = pad_sequences(X, maxlen=SEQUENCE_LENGTH)
print(X[0])
# One Hot encoding labels
# [spam, ham, spam, ham, ham] will be converted to:
# [1, 0, 1, 0, 1] and then to:
# [[0, 1], [1, 0], [0, 1], [1, 0], [0, 1]]
y = [ label2int[label] for label in y ]
y = to_categorical(y)
print(y[0])
# split and shuffle
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=TEST_SIZE, random_state=7)
# constructs the model with 128 LSTM units
model = get_model(tokenizer=tokenizer, lstm_units=128)
# initialize our ModelCheckpoint and TensorBoard callbacks
# model checkpoint for saving best weights
model_checkpoint = ModelCheckpoint("results/spam_classifier_{val_loss:.2f}", save_best_only=True,
verbose=1)
# for better visualization
tensorboard = TensorBoard(f"logs/spam_classifier_{time.time()}")
# print our data shapes
print("X_train.shape:", X_train.shape)
print("X_test.shape:", X_test.shape)
print("y_train.shape:", y_train.shape)
print("y_test.shape:", y_test.shape)
# train the model
model.fit(X_train, y_train, validation_data=(X_test, y_test),
batch_size=BATCH_SIZE, epochs=EPOCHS,
callbacks=[tensorboard, model_checkpoint],
verbose=1)
# get the loss and metrics
result = model.evaluate(X_test, y_test)
# extract those
loss = result[0]
accuracy = result[1]
precision = result[2]
recall = result[3]
print(f"[+] Accuracy: {accuracy*100:.2f}%")
print(f"[+] Precision: {precision*100:.2f}%")
print(f"[+] Recall: {recall*100:.2f}%")
test.py
from utils import get_model, int2label, label2int
from keras.preprocessing.sequence import pad_sequences
import pickle
import numpy as np
SEQUENCE_LENGTH = 100
# get the tokenizer
tokenizer = pickle.load(open("results/tokenizer.pickle", "rb"))
model = get_model(tokenizer, 128)
model.load_weights("results/spam_classifier_0.05")
def get_predictions(text):
sequence = tokenizer.texts_to_sequences([text])
# pad the sequence
sequence = pad_sequences(sequence, maxlen=SEQUENCE_LENGTH)
# get the prediction
prediction = model.predict(sequence)[0]
# one-hot encoded vector, revert using np.argmax
return int2label[np.argmax(prediction)]
while True:
text = input("Enter the mail:")
# convert to sequences
print(get_predictions(text))
0 comments:
Post a Comment