এই পোস্টে, আমি বস্তু সনাক্তকরণ এবং বিভিন্ন আলগোরিদিম যেমন Faster R- CNN, YOLO, SSD, YOLO, SSD ব্যাখ্যা করব। আমরা নতুনদের শুরু থেকে শুরু করাব এবং the state-of-the-art in object detection পর্যন্ত যাব, প্রতিটি পদ্ধতির অন্তর্দৃষ্টি, পদ্ধতি এবং প্রধান বৈশিষ্ট্যগুলি বুঝতে পারব।
 What is Image Classification?:
What is Image Classification?:
চিত্র শ্রেণীবিভাগ জন্য একটি ছবি নেই এবং ছবিতে বস্তুর (predicts)পূর্বাভাস দেই । উদাহরণস্বরূপ, যখন আমরা একটি বিড়াল-কুকুর শ্রেণীবদ্ধ তৈরি করি, তখন আমরা বিড়াল বা কুকুরের চিত্রগুলি গ্রহণ করি এবং তাদের ক্লাসের পূর্বাভাস দিয়েছি।
 ছবিতে উভয় বিড়াল এবং কুকুর উপস্থিত থাকলে আপনি কী করবেন?
ছবিতে উভয় বিড়াল এবং কুকুর উপস্থিত থাকলে আপনি কী করবেন?
আমাদের মডেল পূর্বাভাস কি হবে? এই সমস্যার সমাধান করতে আমরা একটি মাল্টি লেবেল শ্রেণীবদ্ধকারীকে প্রশিক্ষণ দিতে পারি যা উভয় শ্রেণীর (কুকুর এবং বিড়াল) ভবিষ্যদ্বাণী করবে।যাইহোক, আমরা এখনও বিড়াল বা কুকুর অবস্থান জানি না। একটি ছবিতে একটি বস্তুর অবস্থান (শ্রেণী দেওয়া) চিহ্নিত করার সমস্যাটিকে স্থানীয়করণ localization বলা হয়।যাইহোক, যদি বস্তুর শ্রেণীটি পরিচিত না হয়, তবে আমাদের কেবল অবস্থান নির্ধারণ করতে হবে না বরং প্রতিটি বস্তুর বর্গের ভবিষ্যদ্বাণীও করতে হবে।

বর্গ বরাবর বস্তুর অবস্থান পূর্বাভাস বস্তু সনাক্তকরণ বলা হয়।একটি চিত্র থেকে বস্তুর বর্গ পূর্বাভাসের জায়গায়, আমরা এখন সেই বস্তু ধারণকারী শ্রেণির পাশাপাশি একটি আয়তক্ষেত্র (called bounding box) পূর্বাভাস করতে হবে।এটি একটি আয়তক্ষেত্র সনাক্ত করতে 4 টি ভেরিয়েবল নেয়। সুতরাং, চিত্রের বস্তুর প্রতিটি উদাহরণের জন্য, আমরা নিম্নোক্ত ভেরিয়েবলগুলি পূর্বাভাস দেব:
- class_name,
- bounding_box_top_left_x_coordinate,
- bounding_box_top_left_y_coordinate,
- bounding_box_width,bounding_box_height

multi-label image classification সমস্যাগুলির মতোই, আমরা multi-class object detection সমস্যা থাকতে পারি যেখানে আমরা একটি মাএ চিত্রের মধ্যে একাধিক ধরণের বস্তু সনাক্ত করি:নিচের অংশে, আমি অবজেক্ট ডিটেক্টরকে প্রশিক্ষণের জন্য সমস্ত জনপ্রিয় পদ্ধতিগুলি Cover করব।ঐতিহাসিকভাবে, 2001 সালে ভিয়ালা এবং জোন্স (Viola and Jones )প্রস্তাবিত করে Haar Cascades থেকে শুরু হওয়া সনাক্তকরণের অনেকগুলি উপায় রয়েছে.। যাইহোক, আমরা neural networks and Deep Learning.ফোকাস করেতে এর উপর অত্যাধুনিক পদ্ধতির ব্যবহার করাব।
অবজেক্ট ডিটেকশনটি ক্লাসিফিকেশন সমস্যা হিসাবে মডেল করা হয় যেখানে আমরা সম্ভাব্য অবস্থানগুলিতে ইনপুট ইমেজ থেকে নির্দিষ্ট মাপের windows জানালাগুলি নিতে পারি এই প্যাচগুলিকে একটি চিত্র শ্রেণিবদ্ধে ফিড করে।

প্রতিটি উইন্ডোটি শ্রেণীবদ্ধকে খাওয়ানো হয় যা উইন্ডোতে বস্তুর বর্গের পূর্বাভাস দেয় (অথবা যদি background কেউ উপস্থিত না থাকে )। অতএব, আমরা ইমেজ বস্তুর class and location উভয় জানি । সহজ শব্দ! আচ্ছা, আরো কিছু সমস্যা আছে। উইন্ডোটির আকার আপনি কিভাবে জানেন যাতে এটিতে সর্বদা চিত্র থাকে? উদাহরণ দেখুন:

Small sized object Big sized object. What size do you choose for your sliding window detector?
আপনি দেখতে পারেন যে বস্তুটি বিভিন্ন মাপের হতে পারে। এই সমস্যার সমাধান করতে ইমেজ স্কেল করে একটি চিত্র পিরামিড তৈরি করা হয়। আইডিয়াটি হল আমরা একাধিক স্কেলে ইমেজটি পুনরায় আকার দিয়েছি এবং আমরা এই যে আমাদের নির্বাচিত উইন্ডো আকারটি পুরোপুরি এই আকারের চিত্রগুলির মধ্যে একটিতে বস্তুটি ধারণ করবে তার উপর আমরা নির্ভর করি। বেশিরভাগ ক্ষেত্রে, ছবিটি ডাউনস্যামপ্লাইড (আকার হ্রাস করা হয়) যতক্ষণ না নির্দিষ্ট শর্তটি সাধারণত সর্বনিম্ন আকারে পৌঁছে যায়। এই ইমেজ প্রতিটি উপর, একটি নির্দিষ্ট আকার উইন্ডো ডিটেকটর চালানো হয়। যেমন পিরামিড উপর 64 স্তর হিসাবে সাধারণ আছে। এখন, এই সমস্ত উইন্ডো আগ্রহের বস্তু সনাক্ত করার জন্য একটি শ্রেণীবদ্ধকে খাওয়ানো হয়। এটি আমাদের আকার এবং অবস্থান সমস্যা সমাধানে সাহায্য করবে।
 আরও একটি সমস্যা, দৃষ্টি অনুপাত আছে। অনেকগুলি বস্তুগুলি বিভিন্ন আকারে উপস্থিত থাকতে পারে যেমন একজন স্থায়ী ব্যক্তির স্থায়ী ব্যক্তি বা ঘুমন্ত ব্যক্তির তুলনায় ভিন্ন দৃষ্টিভঙ্গি থাকবে। আমরা এই পোস্টে একটু পরে এই আবরণ হবে। RCNN, Faster-RCNN, SSD etc বস্তুর সনাক্তকরণের বিভিন্ন পদ্ধতি রয়েছে। কেন আমাদের কাছে এতগুলি পদ্ধতি রয়েছে এবং এর প্রতিটিটির বৈশিষ্ট্য কী? চল একটু দেখি:
আরও একটি সমস্যা, দৃষ্টি অনুপাত আছে। অনেকগুলি বস্তুগুলি বিভিন্ন আকারে উপস্থিত থাকতে পারে যেমন একজন স্থায়ী ব্যক্তির স্থায়ী ব্যক্তি বা ঘুমন্ত ব্যক্তির তুলনায় ভিন্ন দৃষ্টিভঙ্গি থাকবে। আমরা এই পোস্টে একটু পরে এই আবরণ হবে। RCNN, Faster-RCNN, SSD etc বস্তুর সনাক্তকরণের বিভিন্ন পদ্ধতি রয়েছে। কেন আমাদের কাছে এতগুলি পদ্ধতি রয়েছে এবং এর প্রতিটিটির বৈশিষ্ট্য কী? চল একটু দেখি:H0G বৈশিষ্ট্য ব্যবহার করে বস্তু সনাক্তকরণ:
কম্পিউটার দৃষ্টিভঙ্গির ইতিহাসে একটি গ্রাউন্ডব্র্যাকিং পেপারে,Navneet Dalal and Bill Triggs ২005 সালে Oriented Gradients(HOG) বৈশিষ্ট্যগুলির হিস্টোগ্রাম উপস্থাপন করেছিলেন। হগ বৈশিষ্ট্যগুলি computationally inexpensive এবং অনেক বাস্তব-বিশ্বের সমস্যাগুলির জন্য ভাল। পিরামিডের স্লাইডিং উইন্ডোটি চালানোর প্রতিটি উইন্ডোতে আমরা হগ বৈশিষ্ট্যগুলি গণনা করি যা ক্লাসিফায়ারগুলি তৈরি করতে একটি SVM (Support vector machine) সরবরাহ করা হয়। আমরা পথচারী সনাক্তকরণ, মুখ সনাক্তকরণ, এবং অন্যান্য অনেক বস্তুর সনাক্তকরণ ব্যবহার-ক্ষেত্রে ভিডিওগুলিতে রিয়েল টাইমে এটি চালাতে সক্ষম হয়েছিল।২) Region-based Convolutional Neural Networks(R-CNN): অঞ্চল ভিত্তিক কনভোলনালাল নিউরাল নেটওয়ার্ক (আর-সিএনএন):
যেহেতু আমরা একটি মডেল বস্তুর সনাক্তকরণ শ্রেণীবিভাগ এর সমস্যা ছিল, সাফল্য শ্রেণীবিভাগতার সঠিকতা উপর নির্ভর করে। গভীর শিক্ষার উত্থানের পরে, স্পষ্ট ধারণা হ'ল HOG based classifiers কে প্রতিস্থাপিত করা আরও সঠিক কনভোলিউশনাল নিউরাল নেটওয়ার্ক ভিত্তিক শ্রেণীবদ্ধকারী। যাইহোক, একটি সমস্যা ছিল। CNNs on so many patches generated by sliding window detector এবং computationally খুব ব্যয়বহুল ছিল। উইন্ডো ডিটেক্টর স্লাইড করে তৈরি করা অনেকগুলি প্যাচগুলিতে CNN চালানো অসম্ভব ছিল। R-CNN এই সমস্যাটিকে সিলেক্টিভ সার্চ নামক একটি বস্তু প্রস্তাব অ্যালগরিদম ব্যবহার করে সমাধান করে যা 2000 region proposals এর কাছে শ্রেণীবদ্ধকে সরবরাহ করা bounding boxes সংখ্যা হ্রাস করে। নির্বাচনী অনুসন্ধান বস্তুর সমস্ত সম্ভাব্য অবস্থান জেনারেট করার জন্য টেক্সচার, তীব্রতা, রঙ এবং / অথবা পরিমাপের পরিমাপ ইত্যাদি(texture, intensity, color and/or a measure of insideness etc) স্থানীয় সংকেত ব্যবহার করে। এখন, আমরা এই বাক্সগুলি আমাদের CNN ভিত্তিক শ্রেণীবদ্ধকারীতে ফিড করতে পারি। মনে রাখবেন, CNN এর পুরোপুরি সংযুক্ত অংশটি একটি নির্দিষ্ট মাপের ইনপুট নেয়, তাই আমরা সমস্ত উত্পন্ন বাক্সগুলিকে একটি নির্দিষ্ট আকারে (224 × 224 VGG) প্রতিস্থাপন এবং CNN অংশে ফিড করতে পারি। তাই, R-CNN এর 3 টি গুরুত্বপূর্ণ অংশ রয়েছে:
- Run Selective Search to generate probable objects.
- Feed these patches to CNN, followed by SVM to predict the class of each patch.
- Optimize patches by training bounding box regression separately
সম্ভাব্য বস্তু উৎপন্ন নির্বাচনী অনুসন্ধান চালান।
প্রতিটি প্যাচের ক্লাসের ভবিষ্যদ্বাণী করার জন্য SVM দ্বারা এই প্যাচগুলিকে ফিড করা । প্রশিক্ষণ বিচ্ছিন্নতা বাক্সে পৃথকীকরণ প্রশিক্ষণ দ্বারা প্যাচ অপটিমাইজ করুন।
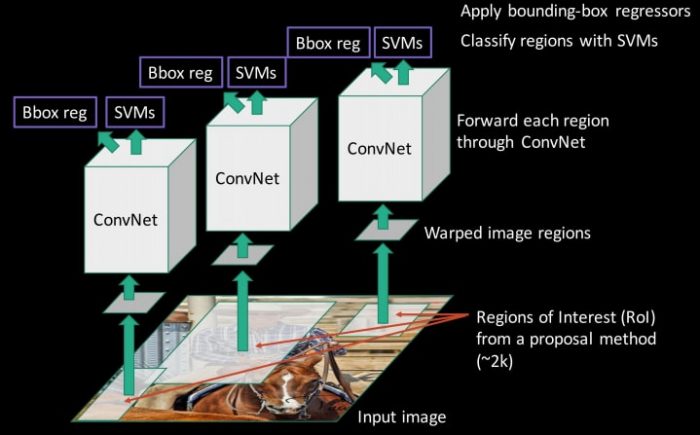
৩) Spatial Pyramid Pooling(SPP-net):
এখনও, R-CNN খুব ধীর ছিল,2000 CNN চালানোর কারণে সিলেক্টিভ অনুসন্ধান দ্বারা উত্পন্ন প্রস্তাবগুলি অনেক সময় নেয়। SPP-net ঠিক করার চেষ্টা করে।
এই অঞ্চলের সাথে সামঞ্জস্যপূর্ণ শেষ কনভার স্তরটির বৈশিষ্ট্য মানচিত্রের অংশটি কেবলমাত্র পুলিংয়ের অপারেশন সম্পাদন করে সম্পন্ন করা যেতে পারে। মধ্যবর্তী স্তরগুলিতে (যা VGG এর ক্ষেত্রে 16 দ্বারা সমন্বয় বিভাজন করে) ভাগ করে নেওয়ার স্তরটি বিবেচনা করে একটি অঞ্চলের সাথে সংকোচকারী স্তরটির আয়তক্ষেত্রের অংশটি কভার লেয়ারের উপর অঞ্চলটিকে প্রক্ষেপণ করে গণনা করা যেতে পারে।
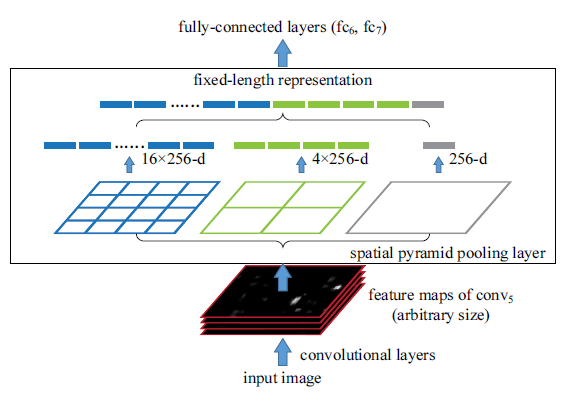




আরও একটি চ্যালেঞ্জ ছিল: আমাদের সিএনএন এর সম্পূর্ণরূপে সংযুক্ত স্তরগুলির জন্য নির্দিষ্ট আকারের ইনপুট জেনারেট করতে হবে তাই এসপিপি আরও একটি কৌশল উপস্থাপন করে। এটি ঐতিহ্যগতভাবে ব্যবহৃত সর্বোচ্চ-পুলিংয়ের বিরোধিতায় শেষ সংকোচকারী স্তর পরে স্থানীয় পুলিং ব্যবহার করে। এসপিপি স্তর কোনও নিরপেক্ষ আকারের একটি অঞ্চলে বিন্দুগুলির একটি ধ্রুবক সংখ্যার মধ্যে ভাগ করে এবং সর্বাধিক পুকুরটি প্রতিটি বিন্দুতে সঞ্চালিত হয়। যেহেতু বিন্দুগুলির সংখ্যা একই থাকে, নিচের চিত্রটিতে প্রদর্শিত হিসাবে একটি স্থির আকারের ভেক্টর উত্পাদিত হয়।
যাইহোক, SPP নেটের সাথে একটি বড় অসুবিধা ছিল, স্থানীয় পুলিং লেয়ারের মাধ্যমে ব্যাক-প্রপোজেশনটি চালানো এটা তুচ্ছ ছিল না। অতএব, নেটওয়ার্কে to নেটওয়ার্কে সম্পূর্ণরূপে সংযুক্ত অংশটি কেবলমাত্র সুরক্ষিত। SPP-নেট আরও জনপ্রিয় Fast RCNN এর জন্য পথ তৈরি করেছে যা আমরা পরবর্তী দেখতে পাব।
4. Fast R-CNN:
Fast R-CNN SPP-নেট এবং R-CNN থেকে ধারনাগুলি ব্যবহার করে এবং SPP-নেটের মূল সমস্যাটি স্থির করে, যেমন তারা শেষ পর্যন্ত প্রশিক্ষণের জন্য সম্ভব করে। স্পেসিয়াল পুলিংয়ের মাধ্যমে গ্র্যাডেন্টগুলি প্রচার করার জন্য, এটি একটি সহজ (back-propagation calculation) ব্যাক-প্রপাগ্যাগন গণনা ব্যবহার করে যা সর্বাধিক-পুলিং গ্রেডিয়েন্ট গণনার সাথে খুব অনুরূপ যা ব্যতিক্রমগুলি পুলিং অঞ্চলগুলি ওভারল্যাপ করে এবং তাই একটি কোষটিতে একাধিক অঞ্চল থেকে gradients pumping বা নতিমাত্রা থাকতে পারে।
Fast R-CNN আরেকটি জিনিস যা তারা নিউরাল নেটওয়ার্ক প্রশিক্ষণ নিজেই বাঁধন বক্স রিগ্রেশন যোগ করেছেন। সুতরাং, এখন network had two heads, classification head, and bounding box regression head। এই মাল্টিটাস উদ্দেশ্যটি Fast R-CNN-এর একটি উল্লেখযোগ্য বৈশিষ্ট্য হিসাবে শ্রেণীবদ্ধকরণ এবং স্থানীয়করণের জন্য এটি আর স্বাধীনভাবে নেটওয়ার্কে প্রশিক্ষণের প্রয়োজন নেই। এই দুটি পরিবর্তনগুলি সামগ্রিক প্রশিক্ষণের সময়কে কমিয়ে দেয় এবং CNN শিখতে শেষ হওয়ার কারণে SPP নেটের তুলনায় সঠিকতা বাড়ায়।
5. Faster R-CNN:
সুতরাং, Faster R-CNN কি উন্নতি করেছে? আচ্ছা, এটা দ্রুত। এবং কিভাবে এটা অর্জন করে? Faster R-CNN-এর সর্বাধিক অংশটি সিলেক্টিভ অনুসন্ধান বা এজ বাক্স ছিল। দ্রুততর RCNN আগ্রহের অঞ্চলগুলি তৈরি করতে অঞ্চল প্রস্তাব নেটওয়ার্ক নামে একটি খুব ছোট সংক্রামক নেটওয়ার্কের সাথে নির্বাচনী অনুসন্ধান প্রতিস্থাপন করে।
দৃষ্টি অনুপাত এবং বস্তুর স্কেল মধ্যে বৈচিত্র্য পরিচালনা করার জন্য, দ্রুত R-CNN নোঙ্গর বাক্সের ধারণা প্রবর্তন করে। প্রতিটি অবস্থানে, মূল কাগজটি 3x ধরণের 128x 128, 256 × 256 এবং 512 × 512 স্কেল জন্য 3 ধরণের নোঙ্গর বাক্স ব্যবহার করে। অনুরূপভাবে, অনুপাত অনুপাতের জন্য, এটি তিনটি দিক অনুপাত 1: 1, 2: 1 এবং 1: 2 ব্যবহার করে। সুতরাং, প্রতিটি অবস্থানে মোট 9 টি বক্স রয়েছে যার উপর RPN ব্যাকগ্রাউন্ড বা ফোরাম হওয়ার সম্ভাবনার পূর্বাভাস দেয়। আমরা প্রতিটি অবস্থানে নোঙ্গর বক্স উন্নত করার জন্য বাঁধাই বক্স রিগ্রেশন প্রয়োগ। সুতরাং, RPN বিভিন্ন মাপের সীমাবদ্ধ বাক্সগুলিকে প্রতিটি শ্রেণির সংশ্লিষ্ট সম্ভাবনার সাথে দেয়। ফাস্ট-আরসিএনএন-এর মত স্পেসিয়াল পুলিং প্রয়োগ করে সীমাবদ্ধ বাক্সগুলির পরিবর্তিত আকারগুলি আরও পাশ হতে পারে। অবশিষ্ট নেটওয়ার্ক দ্রুত-আরসিএনএন অনুরূপ। দ্রুত-আরসিএনএন দ্রুত-আরসিএনএন-এর তুলনায় 10 গুণ বেশি দ্রুত VOC-2007 মত ডেটাসেটের সাথে সঠিক। এজন্য ফাস্ট-আরসিএনএন সবচেয়ে সঠিক বস্তু সনাক্তকরণ অ্যালগরিদমগুলির মধ্যে একটি হয়েছে। এখানে RCNN এর বিভিন্ন সংস্করণের মধ্যে একটি দ্রুত তুলনা।
Regression-based object detectors:রিগ্রেশন ভিত্তিক বস্তু ডিটেক্টর:
এ পর্যন্ত, সমস্ত পাইপলাইন নির্মাণের মাধ্যমে শ্রেণীবদ্ধকরণ সমস্যা হিসাবে পরিচালিত সমস্ত পদ্ধতিতে আলোচনা করা হয়েছে যেখানে প্রথম বস্তুর প্রস্তাব তৈরি করা হয় এবং এই প্রস্তাবগুলি শ্রেণীবদ্ধকরণ / প্রতিক্রিয়া মাথা পাঠানো হয়। তবে, কয়েকটি পদ্ধতি রয়েছে যা একটি প্রতিক্রিয়া সমস্যা হিসাবে সনাক্তকরণ সৃষ্টি করে। সবচেয়ে জনপ্রিয় দুটি হল YOLO এবং SSD। এই ডিটেক্টর এছাড়াও একক শট আবিষ্কারক বলা হয়। আসুন তাদের নজর রাখি:
6. YOLO(You only Look Once):YOLO (আপনি শুধুমাত্র একবার দেখুন)
YOLO- এর জন্য, সনাক্তকরণ একটি সহজ প্রতিক্রিয়া সমস্যা যা একটি ইনপুট চিত্র নেয় এবং ক্লাসের সম্ভাব্যতা এবং বাঁধাকপি বাক্স সমন্বয়গুলি শিখায়। সহজ শব্দ?
YOLO S x S এর একটি গ্রিডে প্রতিটি চিত্রকে বিভক্ত করে এবং প্রতিটি গ্রিড ভবিষ্যদ্বাণী করে এন এন বাউন্ডিং বাক্স এবং আস্থা। আস্থা সীমানা বাক্সের নির্ভুলতা প্রতিফলিত করে এবং বাঁধাকপি বাক্সে প্রকৃতপক্ষে একটি বস্তু রয়েছে (বর্গ নির্বিশেষে)। YOLO প্রশিক্ষণ প্রতিটি ক্লাসের জন্য প্রতিটি বক্স জন্য শ্রেণীবিভাগ স্কোর ভবিষ্যদ্বাণী। পূর্বাভাস বাক্সে উপস্থিত প্রতিটি শ্রেণীর সম্ভাব্যতা গণনা করার জন্য আপনি উভয় শ্রেণীকে একত্রিত করতে পারেন।
সুতরাং, মোট SxSxN বক্স পূর্বাভাস করা হয়। যাইহোক, এই বাক্সগুলির বেশিরভাগই আস্থার স্কোর কম এবং আমরা 30% আস্থা বলে একটি থ্রেশহোল্ড সেট করলে, নীচের উদাহরণে দেখানো হিসাবে আমরা তাদের অধিকাংশই সরাতে পারি।
লক্ষ্য করুন যে রানটাইম এ, আমরা সিএনএন থেকে একবারে আমাদের ছবিটি চালাচ্ছি। অতএব, YOLO সুপার দ্রুত এবং বাস্তব সময় চালানো যাবে। আরেকটি মূল পার্থক্য হল যে YOLO একবারে সম্পূর্ণ চিত্রটি দেখেছে পূর্ববর্তী পদ্ধতিগুলিতে কেবল একটি উত্পন্ন অঞ্চলের প্রস্তাবগুলির দিকে তাকিয়ে। সুতরাং, এই প্রাসঙ্গিক তথ্য মিথ্যা ইতিবাচক এড়াতে সাহায্য করে। যাইহোক, YOLO এর জন্য একটি সীমাবদ্ধতা হল যে এটি শুধুমাত্র একটি গ্রিডে 1 ধরনের শ্রেণী ভবিষ্যদ্বাণী করে, তাই এটি খুব ছোট বস্তুর সাথে লড়াই করে।
7. Single Shot Detector(SSD):একা শট আবিষ্কারক (এসএসডি):
একা শট আবিষ্কারক গতি এবং সঠিকতা মধ্যে একটি ভাল ভারসাম্য অর্জন। এসএসডি শুধুমাত্র একবার ইনপুট ইমেজ একটি সংগ্রাহক নেটওয়ার্ক সঞ্চালিত এবং একটি বৈশিষ্ট্য মানচিত্র গণনা। এখন, আমরা বদ্ধ বাক্স এবং শ্রেণীবিভাগ সম্ভাবনা পূর্বাভাস করার জন্য এই বৈশিষ্ট্যের মানচিত্রে একটি ছোট 3 × 3 আকারের কনভোলিউশনাল কার্নেল চালাচ্ছি। এসএসডি এছাড়াও ফাস্ট-আরসিএনএন-এর মতো বিভিন্ন দিক অনুপাতে নোঙ্গর বাক্সগুলি ব্যবহার করে এবং বাক্সটি শেখার পরিবর্তে অফ-সেট শিখায়। স্কেল হ্যান্ডেল করার জন্য, এসএসডি একাধিক সংশ্লেষ স্তরগুলির পরে আবদ্ধ বাক্সগুলির পূর্বাভাস দেয়। যেহেতু প্রতিটি সংশ্লেষ স্তর একটি ভিন্ন স্কেলে কাজ করে, এটি বিভিন্ন স্কেলগুলির বস্তু সনাক্ত করতে সক্ষম।
যে আলগোরিদিম অনেক। আপনি কোনটি ব্যবহার করা উচিত? বর্তমানে, আপনি যদি নির্ভুলতা সংখ্যার বিষয়ে কৌতুহলী হন তবে ফাস্ট-আরসিএনএন পছন্দসই। তবে, যদি আপনি কম্পিউটেশন (সম্ভবত এটি Nvidia Jetsons এ চলমান) জন্য আটকে আছেন তবে এসএসডি একটি ভাল সুপারিশ। অবশেষে, যদি সঠিকতা কোন উদ্বেগের বিষয় না থাকে তবে আপনি অতি দ্রুত যেতে চান, YOLO যেতে রাস্তা হবে। গতি বনাম নির্ভুলতা বাণিজ্য বন্ধ সমস্ত একটি চাক্ষুষ বোঝার প্রথম:
এসএসডি একটি ভাল পছন্দ বলে মনে হচ্ছে কারণ আমরা এটি একটি ভিডিওতে চালাতে সক্ষম এবং সঠিকতা বাণিজ্য বন্ধ খুব কম। যাইহোক, এটি সহজ হতে পারে না, এই চার্টটি দেখুন যা বিভিন্ন আকারের বস্তুর উপর SSD, YOLO এবং Faster-RCNN এর কার্যকারিতা তুলনা করে। বড় আকারে, এসএসডি দ্রুত-আরসিএনএন অনুরূপ সঞ্চালন বলে মনে হয়। যাইহোক, বস্তুর আকার ছোট যখন সঠিকতা সংখ্যা তাকান, ফাঁক widens।
YOLO vs SSD vs Faster-RCNN for various sizes
একটি সঠিক বস্তুর সনাক্তকরণ পদ্ধতির চয়েস অত্যন্ত গুরুত্বপূর্ণ এবং আপনি সমাধান করার চেষ্টা করছেন এবং সেট-আপের উপর নির্ভর করে। অবজেক্ট ডিটেকশনটি হ'ল স্বায়ত্তশাসিত গাড়ি, নিরাপত্তা এবং নজরদারি এবং অনেক শিল্প অ্যাপ্লিকেশনগুলির মতো কম্পিউটার দৃষ্টিভঙ্গির অনেকগুলি বাস্তব অ্যাপ্লিকেশনের ব্যাকবোন। আশা করি, এই পোস্টটি আপনাকে অবজেক্ট সনাক্তকরণের জন্য জনপ্রিয় অ্যালগরিদমগুলির প্রত্যেকের পিছনে একটি অন্তর্দৃষ্টি এবং বোঝার সুযোগ দিয়েছে।
0 comments:
Post a Comment