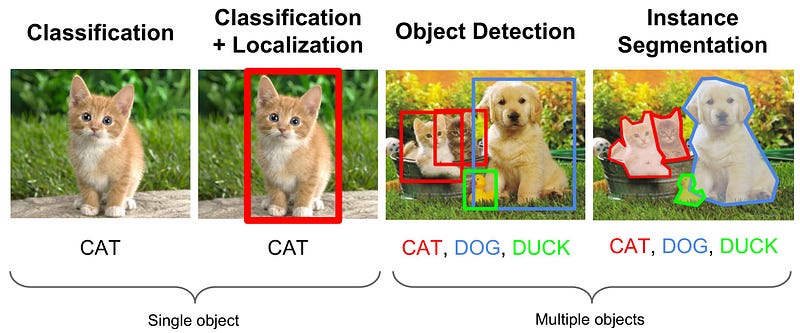
ইমেজ শ্রেণীবিভাগ পরিবর্তে বস্তু সনাক্তকরণ কেন?
মোবাইল ফোনের সাথে নেওয়া ফটোগুলি সাধারণত জটিল এবং এতে একাধিক বস্তু রয়েছে। এই বলে, ইমেজ শ্রেণীবিভাগ মডেল সঙ্গে একটি লেবেল নির্ধারণ করা চতুর এবং অনিশ্চিত হতে পারে। বস্তুর সনাক্তকরণ মডেলগুলি একক চিত্রের মধ্যে একাধিক প্রাসঙ্গিক বস্তুর শনাক্ত করতে আরো উপযুক্ত। অবজেক্ট সনাক্তকরণ মডেলের দ্বিতীয় উল্লেখযোগ্য উপাদানের বিপরীতে ইমেজ শ্রেণিবদ্ধকরণগুলি হল বস্তুর স্থানীয়করণ প্রদান করা। এটি জিলের জন্য উপযুক্ত মানদণ্ড এবং ফটো অ্যালবাম তৈরি বা অনুরূপ সনাক্তকরণের বৈশিষ্ট্য নয় তবে অন্যান্য ব্যবহারের ক্ষেত্রে এটি আকর্ষণীয় হতে পারে। স্বায়ত্বশাসিত গাড়ির বা চিত্র ক্যাপশন প্রজন্মের সম্পর্কে চিন্তা করুন
https://medium.com/comet-app/review-of-deep-learning-algorithms-for-image-classification-5fdbca4a05e2
আমার বিশ্লেষণ মানদণ্ড এক বাস্তব গতি বিশ্লেষণ অনুমতি তাদের গতিতে হবে। উল্লেখ্য যে গবেষকরা বিভিন্ন আলাদা ডেটাসেটগুলি ব্যবহার করে তাদের অ্যালগরিদম পরীক্ষা করে (পাসকাল ভিওসি, কোকো, চিত্রনেট) যা বছরের মধ্যে আলাদা। সুতরাং উদ্ধৃত সংহতি সরাসরি প্রতি সেকেন্ডে তুলনা করা যাবে না।
Datasets and Performance Metricডেটাসেট এবং পারফরম্যান্স মেট্রিক
বিভিন্ন ডেটাসেট বস্তু সনাক্তকরণ চ্যালেঞ্জ জন্য মুক্তি করা হয়েছে। গবেষকরা এই চ্যালেঞ্জগুলিতে প্রয়োগ করা তাদের অ্যালগরিদম ফলাফল প্রকাশ। নির্দিষ্ট কর্মক্ষমতা মেট্রিকগুলি সনাক্তকৃত বস্তুর স্থানিক অবস্থান এবং পূর্বাভাস বিভাগগুলির নির্ভুলতা বিবেচনা করার জন্য উন্নত করা হয়েছে।
ডেটাসেট
PASCAL Visual Object Classification (PASCAL VOC) ডেটাসেট বস্তু সনাক্তকরণ, শ্রেণীবদ্ধকরণ, অবজেক্টের বিভাজন এবং আরও অনেক কিছু জন্য একটি সুপরিচিত ডেটাসেট। ২005 থেকে ২01২ পর্যন্ত 8 টি ভিন্ন ভিন্ন চ্যালেঞ্জ রয়েছে, তাদের প্রতিটি নিজস্ব নিজস্ব বৈশিষ্ট্য রয়েছে। অবজেক্টের সাথে আবদ্ধ বাক্স ধারণকারী প্রশিক্ষণ এবং বৈধতার জন্য প্রায় 10 000 ছবি রয়েছে। যদিও, PASCAL VOC ডেটাসেটটিতে কেবলমাত্র ২0 টি বিভাগ রয়েছে, এটি এখনও বস্তু সনাক্তকরণ সমস্যাতে একটি রেফারেন্স ডেটাসেট হিসাবে বিবেচিত হয়।
ImageNet 2013 সাল থেকে একটি বস্তু সনাক্তকরণ ডেটাসেট প্রকাশ করেছে। প্রশিক্ষণ ডেটাসেট শুধুমাত্র প্রশিক্ষণ এবং 200 বিভাগের জন্য প্রায় 500 000 ইমেজ গঠিত হয়। এটি খুব কমই ব্যবহৃত হয় কারণ ডেটাসেটের আকারের প্রশিক্ষণের জন্য একটি গুরুত্বপূর্ণ কম্পিউটেশাল শক্তি প্রয়োজন। এছাড়াও, ক্লাসের উচ্চ সংখ্যা বস্তুর স্বীকৃতি কার্যকে জটিল করে তোলে। 2014 ইমেজনেট ডেটাসেট এবং 2012 প্যাসকাল ভিওসি ডেটাসেটের মধ্যে একটি তুলনা here পাওয়া যায়।
অন্যদিকে, Common Objects in COntext (COCO) Dataset সাধারণ বস্তুগুলি মাইক্রোসফ্ট দ্বারা তৈরি এবং T.-Y.Lin and al. (2015)। এই ডেটাসেটটি একাধিক চ্যালেঞ্জের জন্য ব্যবহৃত হয়: multiple challenges: caption generation, object detection, key point detection and object segmentation। আমরা COCO অবজেক্ট সনাক্তকরণ চ্যালেঞ্জের উপর নজর রাখি যা একটি ছবিতে বস্তুগুলি লোডিং বাক্সগুলির সাথে স্থানীয়করণে এবং 80 টি বিভাগের মধ্যে প্রতিটিকে শ্রেণীবদ্ধ করে। ডেটাসেট প্রতি বছর পরিবর্তিত হয় তবে সাধারণত প্রশিক্ষণ এবং যাচাইকরণের জন্য 120 টিরও বেশি ইমেজ এবং পরীক্ষার জন্য 40 000 টিরও বেশি চিত্রের সাথে গঠিত হয়। পরীক্ষার ডেটাসেট সম্প্রতি গবেষকদের জন্য পরীক্ষার ডেভ ডেটাসেট এবং প্রতিযোগীদের জন্য পরীক্ষার চ্যালেঞ্জ ডেটাসেটে কাটা হয়েছে। উভয় সংশ্লিষ্ট লেবেলযুক্ত তথ্য পরীক্ষার ডেটাসেটের উপর অতিরিক্ত চাপ এড়ানোর জন্য সর্বজনীনভাবে উপলব্ধ নয়।

Performance Metric পারফরমেন্স মেট্রিক
বস্তু সনাক্তকরণ চ্যালেঞ্জ একই সময়ে, একটি প্রতিক্রিয়া এবং একটি শ্রেণীবিভাগ কাজ। সর্বোপরি, স্পেসিয়াল স্পষ্টতাটি মূল্যায়ন করতে আমাদের কম আস্থা সহ বাক্সগুলি সরাতে হবে (সাধারণত, মডেল প্রকৃত বস্তুর তুলনায় অনেক বেশি বাক্সে আউটপুট করে)। তারপরে, আমরা Intersection over Union (IoU)এলাকাটি ব্যবহার করি, এটি 0 এবং 1 এর মধ্যে একটি মান। এটি পূর্বাভাস বাক্স এবং স্থল-সত্য বাক্সের মধ্যে ওভারল্যাপিং এলাকাটির সাথে সংশ্লিষ্ট। IOU উচ্চতর, প্রদত্ত বস্তুর জন্য বাক্সের পূর্বাভাসযুক্ত অবস্থানটি আরও ভাল। সাধারণত, আমরা কোনও threshold./প্রবেশস্থল চেয়েও বেশি IOU সহ সমস্ত আবদ্ধ বক্স প্রার্থীকে রাখি।
বাইনারি শ্রেণিতে, গড় নির্ভুলতা (AP) মেট্রিক নির্ভুলতা-প্রত্যাহার বক্ররেখার একটি সারাংশ, here বিশদ সরবরাহ করা হয়েছে। বস্তুর সনাক্তকরণের চ্যালেঞ্জগুলির জন্য ব্যবহৃত সাধারণভাবে ব্যবহৃত mean Average Precision নির্ভুলতা (Map) বলা হয়।এটি কেবলমাত্র চ্যালেঞ্জের সমস্ত ক্লাসগুলির উপর গণনা করা গড় অভিক্ষেপগুলির গড়। এমএপি মেট্রিক কয়েক শ্রেণীর মধ্যে চরম বিশেষজ্ঞতা এবং এইভাবে অন্যদের মধ্যে দুর্বল পারফরম্যান্স আছে এড়ানো।
Map স্কোরটি সাধারণত নির্দিষ্ট IoU-র জন্য গণনা করা হয় তবে উচ্চ সংখ্যক আবদ্ধ বাক্সগুলি প্রার্থী বাক্সগুলির সংখ্যা বাড়িয়ে তুলতে পারে। বাক্সের ওভার প্রজন্মের এড়াতে COCO চ্যালেঞ্জটি একটি সরকারী মেট্রিক তৈরি করেছে। ভুল শ্রেণীবদ্ধকরণের সাথে উচ্চ সংখ্যক আবদ্ধ বাক্সগুলি দণ্ডিত করার জন্য এটি পরিবর্তনশীল আইওইউ মানের জন্য Map স্কোরগুলির একটি গড় গণনা করে।
Region-based Convolutional Network (R-CNN)অঞ্চল ভিত্তিক কনভোলিউশনাল নেটওয়ার্ক (আর-সিএনএন)
প্রথম মডেলটি intuitively অঞ্চলের অনুসন্ধান শুরু এবং তারপর শ্রেণীবিভাগ সঞ্চালন। In R-CNN, নির্বাচনী অনুসন্ধান পদ্ধতি J.R.R. Uijlings and al. (2012) দ্বারা উন্নত। Uijlings এবং আল। (2012) বস্তুর অবস্থান ক্যাপচার করার জন্য একটি ছবিতে সম্পূর্ণ অনুসন্ধানের বিকল্প। এটি একটি চিত্রের ছোট অঞ্চলগুলিকে সূচনা করে এবং একটি শ্রেণীবদ্ধ গোষ্ঠী দিয়ে তাদের মার্জ করে। সুতরাং চূড়ান্ত গ্রুপ একটি সম্পূর্ণ বক্স ধারণকারী বাক্স। সনাক্ত অঞ্চলগুলি বিভিন্ন রঙের স্পেস এবং সমতা মেট্রিক অনুসারে বিযুক্ত হয়। আউটপুটটি কয়েকটি অঞ্চলের প্রস্তাবনা যা ছোট অঞ্চলে একত্রিত করে একটি বস্তু ধারণ করতে পারে।

Selective Search application, top: visualisation of the segmention results of the algorithm, down: visualisation of the region proposals of the algorithm. Source: J.R.R. Uijlings and al. (2012)
নির্বাচনী অনুসন্ধান অ্যাপ্লিকেশন, শীর্ষ: অ্যালগরিদম বিভাগের ফলাফলের দৃশ্যমানতা, নিচে: অ্যালগরিদম অঞ্চলের প্রস্তাবগুলির ভিজ্যুয়ালাইজেশন। উত্স: জেআরআর। Uijlings এবং আল। (2012)
R-CNN মডেল (আর। গিরশিক et al।, 2014) এই অঞ্চলে বস্তুর সন্ধানের জন্য অঞ্চল প্রস্তাবগুলি এবং গভীর শিক্ষার সন্ধানের জন্য নির্বাচনী অনুসন্ধান পদ্ধতিকে সমন্বিত করে। প্রতিটি অঞ্চলের প্রস্তাবটি একটি সিএনএন এর ইনপুট মিলিয়ে পুনরায় আকার পরিবর্তন করা হয় যার থেকে আমরা বৈশিষ্ট্যগুলির একটি 4096-মাত্রা ভেক্টর বের করি। বৈশিষ্ট্যাবলী ভেক্টর প্রতিটি শ্রেণীর অন্তর্গত সম্ভাব্যতা উত্পাদন করতে একাধিক শ্রেণীকক্ষ মধ্যে খাওয়ানো হয়। এই ক্লাসগুলির প্রত্যেকটি একটি SVM শ্রেণীবদ্ধকারীকে বৈশিষ্ট্যগুলির প্রদত্ত ভেক্টরটির জন্য এই বস্তুর সনাক্তকরণের সম্ভাব্যতার কারনে প্রশিক্ষণ দেওয়া হয়েছে। এই ভেক্টর একটি অঞ্চল প্রস্তাবের জন্য সীমানা বাক্সের আকারগুলি মাপসই করার জন্য একটি রৈখিক রিডারকেও ফিড করে এবং এভাবে স্থানীয়করণ ত্রুটিগুলি কমাতে পারে।
লেখক দ্বারা বর্ণিত CNN মডেলটি চিত্র শ্রেণির মূল চ্যালেঞ্জের ২01২ ইমেজনেট ডেটাসেটে প্রশিক্ষিত। এটি স্থল-সত্য বাক্সগুলির সাথে 0.5 এরও বেশি IOU সংশ্লিষ্ট অঞ্চলের প্রস্তাবগুলি ব্যবহার করে। দুটি সংস্করণ উত্পাদিত হয়, PASCAL VOC dataset and the other the 2013 ImageNet dataset with bounding boxes দিয়ে ব্যবহার করছে। SVM ক্লাসিফায়ারগুলি প্রতিটি ডেটাসেটের প্রতিটি শ্রেণীর জন্যও প্রশিক্ষিত।
সেরা R-CNN মডেলগুলি PASCAL VOC 2012 পরীক্ষার ডেটাসেটে একটি 62.4% MAP স্কোর অর্জন করেছে (২২.0 পয়েন্টগুলি leader board দ্বিতীয় সেরা ফলাফলটি জাগিয়ে তুলছে) এবং ২013 ইমেজনেট ডেটাসেটে 31.4% এমএপি স্কোর (দ্বিতীয় সেরা ফলাফল 7.1 পয়েন্ট বৃদ্ধি করে w.r.t leader board )।
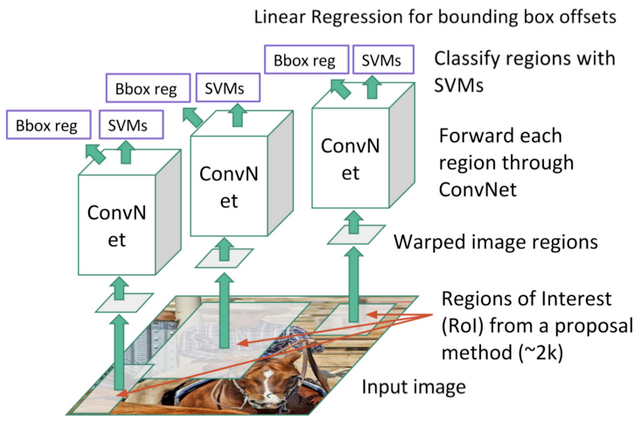
Region-based Convolution Network (R-CNN). Each region proposal feeds a CNN to extract a features vector, possible objects are detected using multiple SVM classifiers and a linear regressor modifies the coordinates of the bounding box. Source: J. Xu’s Blog
অঞ্চল ভিত্তিক কনভোলিউশন নেটওয়ার্ক (আর-সিএনএন)। প্রতিটি অঞ্চল প্রস্তাব একটি বৈশিষ্ট্য ভেক্টর বের করার জন্য একটি সিএনএন ফিড করে, একাধিক SVM শ্রেণীকক্ষ ব্যবহার করে সম্ভাব্য বস্তুগুলি সনাক্ত করা হয় এবং একটি রৈখিক রিগ্রসর সীমানা বাক্সের সমন্বয়কে সংশোধন করে। উত্স: জে জু এর ব্লগ
Fast Region-based Convolutional Network (Fast R-CNN)
R. Girshick (2015) দ্বারা উন্নত ফাস্ট অঞ্চলভিত্তিক কনভোলনালাল নেটওয়ার্ক (Fast R-CNN) এর উদ্দেশ্য হল সমস্ত অঞ্চলের প্রস্তাব বিশ্লেষণের জন্য প্রয়োজনীয় সংখ্যক মডেলের সাথে সময় খরচ হ্রাস করা
একাধিক সংহত স্তর সহ একটি প্রধান সিএনএন প্রতিটি অঞ্চলের প্রস্তাবগুলির জন্য একটি সিএনএন ব্যবহার করার পরিবর্তে সমগ্র চিত্রটিকে ইনপুট হিসাবে গ্রহণ করছে (আর-সিএনএন)। আগ্রহের অঞ্চল (RoIs) উত্পাদিত বৈশিষ্ট্য মানচিত্রে প্রয়োগ করা নির্বাচনী অনুসন্ধান পদ্ধতির সাথে সনাক্ত করা হয়। আনুষ্ঠানিকভাবে, নির্দিষ্ট মান এবং প্রস্থের হাইপারপারমিটার হিসাবে প্রস্থের বৈধ অঞ্চল পেতে একটি ROI পুলিং স্তর ব্যবহার করে বৈশিষ্ট্য মানচিত্রের আকার হ্রাস করা হয়। প্রতিটি RoI স্তর সম্পূর্ণরূপে সংযুক্ত স্তর feeds একটি বৈশিষ্ট্য ভেক্টর তৈরি। ভেক্টরটি নরমমেক্স শ্রেণীবদ্ধকারীর সাথে পর্যবেক্ষিত বস্তুর পূর্বাভাস এবং লিনিয়ার রিগ্রেশারের সাথে সীমানা বাক্স স্থানীয়করণগুলি মাপসই করার জন্য ব্যবহৃত হয়।
২007 পাসকাল ভিওসি পরীক্ষার ডেটাসেটের জন্য সেরা ফাস্ট আর সিএনএন 70.0% এর mAp স্কোর পৌঁছেছে, ২010 PASCAL VOC পরীক্ষার ডেটাসেটের 68.8% এবং ২01২ PASCAL VOC পরীক্ষার ডেটাসেটের জন্য 68.4%।
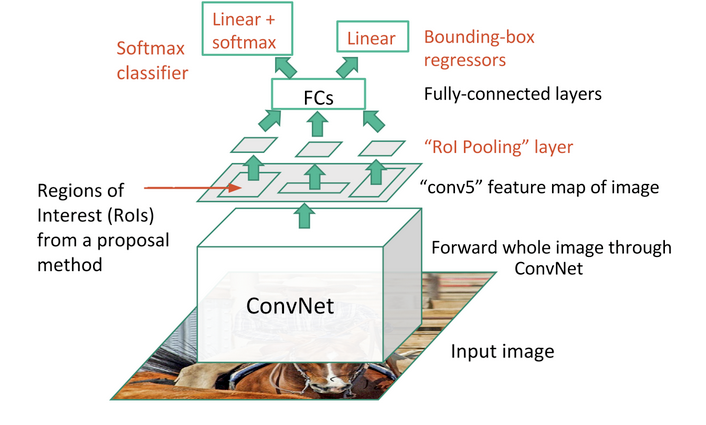
The entire image feeds a CNN model to detect RoI on the feature maps. Each region is separated using a RoI pooling layer and it feeds fully-connected layers. This vector is used by a softmax classifier to detect the object and by a linear regressor to modify the coordinates of the bounding box. Source: J. Xu’s Blog
সম্পূর্ণ চিত্র বৈশিষ্ট্যের মানচিত্রে RoI সনাক্ত করার জন্য একটি সিএনএন মডেল ফিড করে। প্রতিটি অঞ্চল একটি RoI পুলিং স্তর ব্যবহার করে পৃথক করা হয় এবং এটি সম্পূর্ণরূপে সংযুক্ত স্তরগুলি ফিড করে। বস্তুর সনাক্তকরণ এবং বেনামী বাক্সের সমন্বয়কারীগুলিকে সংশোধন করতে একটি লিনিয়ার রিগ্রেসার দ্বারা এই ভেক্টরটি একটি softmax classifier দ্বারা ব্যবহৃত হয়। উত্স: জে জু এর ব্লগ
Faster Region-based Convolutional Network (Faster R-CNN)
নির্বাচনী অনুসন্ধান পদ্ধতির সাথে সনাক্ত করা অঞ্চল প্রস্তাবগুলি এখনও পূর্ববর্তী মডেলের মধ্যে প্রয়োজনীয় ছিল যা তুলনামূলকভাবে ব্যয়বহুল। S. Ren and al. (2016) অঞ্চল প্রস্তাব সরাসরি উৎপন্ন করতে, সীমানা বাক্স পূর্বাভাস এবং বস্তু সনাক্ত করার জন্য অঞ্চল প্রস্তাব নেটওয়ার্ক (RPN) চালু করেছে। দ্রুত অঞ্চল-ভিত্তিক কনভোলনাল নেটওয়ার্ক (দ্রুততর আর-সিএনএন/Faster R-CNN) RPN এবং Faster R-CNN মডেলের মধ্যে সমন্বয়।
একটি সিএনএন মডেল সমগ্র ইমেজ ইনপুট হিসাবে লাগে এবং বৈশিষ্ট্য মানচিত্র উত্পাদন করে। সাইজ 3x3 এর একটি উইন্ডো সমস্ত বৈশিষ্ট্যের মানচিত্র স্লাইড করে এবং দুটি সম্পূর্ণরূপে সংযুক্ত স্তরগুলির সাথে সংযুক্ত একটি বৈশিষ্ট্য ভেক্টর আউটপুট করে, একটি বক্স-রিগ্রেশন এবং বক্স-শ্রেণীবিভাগের জন্য একটি। একাধিক অঞ্চল প্রস্তাব সম্পূর্ণরূপে সংযুক্ত স্তর দ্বারা পূর্বাভাস করা হয়। সর্বাধিক কে অঞ্চলে সংশোধন করা হয়েছে, ফলে বক্স-রিগ্রেশন স্তরটির আউটপুট 4k (আকারের বাক্স, তাদের উচ্চতা এবং প্রস্থের সমন্বয়) এবং বক্স-শ্রেণীবিভাগ স্তরটির আউটপুট 2k ("বস্তুগত" স্কোরের আকারের আকারের আকার রয়েছে। একটি বস্তু সনাক্ত বা বক্সে না)। স্লাইডিং উইন্ডো দ্বারা সনাক্ত করা K অঞ্চলের প্রস্তাবগুলি অ্যাঙ্কার/anchors/ নঙ্গর করা বলা হয়।
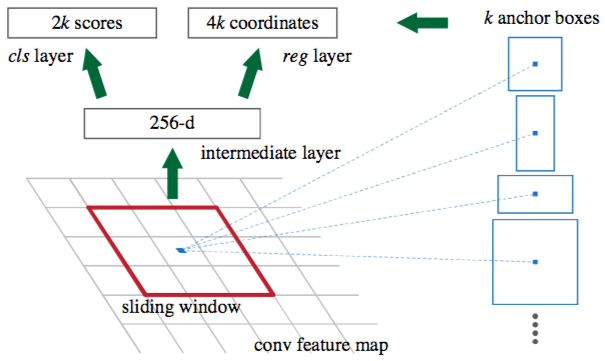
Detecting the anchor boxes for a single 3x3 window. Source: S. Ren and al. (2016)
একটি একক 3x3 উইন্ডো জন্য নোঙ্গর বাক্স সনাক্ত করা। উত্স: এস। রেন এবং আল। (2016)
যখন নোঙ্গর বাক্স সনাক্ত করা হয়, তখন কেবলমাত্র প্রাসঙ্গিক বাক্সগুলি রাখার জন্য "বস্তুগত" স্কোরের উপর একটি থ্রেশহোল্ড প্রয়োগ করে নির্বাচিত হয়। এই এনকর বাক্সগুলি এবং প্রাথমিক CNN মডেল দ্বারা চিহ্নিত বৈশিষ্ট্যের মানচিত্রগুলি একটি Fast R-CNN মডেলকে ফিড করে।
দ্রুততর আর-সিএনএন নির্বাচনী অনুসন্ধান পদ্ধতি এড়ানোর জন্য RPN ব্যবহার করে, এটি প্রশিক্ষণ এবং পরীক্ষার প্রক্রিয়াগুলিকে ত্বরান্বিত করে এবং পারফরম্যান্সের উন্নতি করে। RPN শ্রেণীবিভাগের জন্য ইমেজনেট ডেটাসেটের উপর একটি প্রাক-প্রশিক্ষিত মডেল ব্যবহার করে এবং এটি PASCAL VOC ডেটাসেটে সুসংগত হয়। তারপরে অ্যাঙ্কর বাক্সগুলির সাথে উত্পন্ন অঞ্চলের প্রস্তাবগুলি Fast R-CNN কে প্রশিক্ষণের জন্য ব্যবহার করা হয়। এই প্রক্রিয়া পুনরাবৃত্তিমূলক।
সেরা ফাস্টার আর-সিএনএন 2007 পাসক্যাল ভিওসি পরীক্ষার ডেটাসেটে 78.8% এর এমএপি স্কোর অর্জন করেছে এবং ২01২ পাসকাল ভিওসি পরীক্ষার ডেটাসেটে 75.9%। তারা PASCAL ভিওসি এবং COCO ডেটাসেট সঙ্গে প্রশিক্ষিত হয়েছে। এই মডেলগুলির মধ্যে একটি হল নির্বাচনী অনুসন্ধান পদ্ধতি ব্যবহার করে ফাস্ট আর-সিএনএন থেকে 34 গুণ দ্রুত।
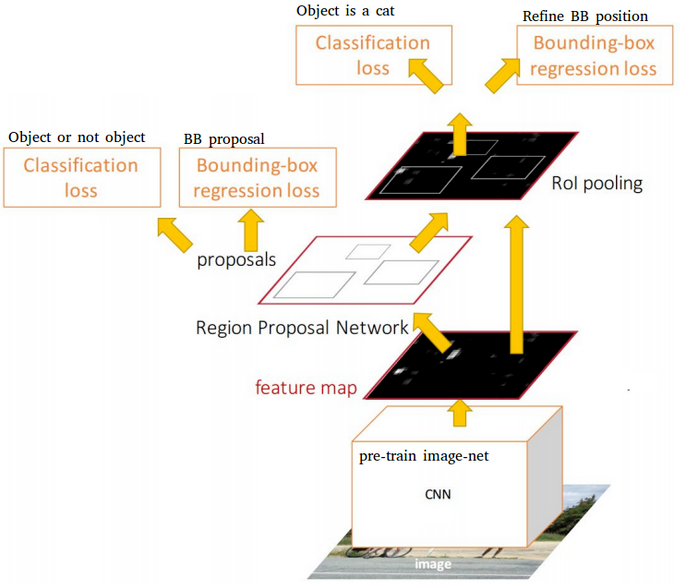
The entire image feeds a CNN model to produce anchor boxes as region proposals with a confidence to contain an object. A Fast R-CNN is used taking as inputs the feature maps and the region proposals. For each box, it produces probabilities to detect each object and correction over the location of the box. Source: J. Xu’s Blog
পুরো চিত্রটি একটি বস্তু ধারণ করার জন্য আস্থা সহ অঞ্চল প্রস্তাব হিসাবে নোঙ্গর বাক্সগুলি উত্পাদন করতে একটি সিএনএন মডেলকে ফিড করে। একটি দ্রুত আর-সিএনএন বৈশিষ্ট্য মানচিত্র এবং অঞ্চলের প্রস্তাব ইনপুট গ্রহণ হিসাবে গ্রহণ করা হয়। প্রতিটি বাক্সের জন্য, এটি বাক্সের অবস্থানের উপর প্রতিটি বস্তু এবং সংশোধন সনাক্ত করার সম্ভাবনাগুলি তৈরি করে। উত্স: জে জু এর ব্লগ
Region-based Fully Convolutional Network (R-FCN)অঞ্চল ভিত্তিক সম্পূর্ণ রূপান্তরমূলক নেটওয়ার্ক (R-FCN)
ফাস্ট এবং ফাস্টার R-CNN পদ্ধতিগুলি অঞ্চলের প্রস্তাবগুলি সনাক্ত করতে এবং প্রতিটি অঞ্চলে একটি বস্তুর স্বীকৃতি দেয়। অঞ্চল ভিত্তিক Fully Convolutional Network (R-FCN) জে দাই এবং আল দ্বারা মুক্তিপ্রাপ্ত। (2016) শুধুমাত্র একটি সংগ্রাহক স্তরের মডেল যা প্রশিক্ষণ এবং পরিমাপের জন্য সম্পূর্ণ ব্যাকপ্রোগেশনকে অনুমোদন করে। লেখক একযোগে বস্তুর সনাক্তকরণ (অবস্থানের পরিবর্তন) এবং এর অবস্থান (অবস্থানের বৈকল্পিক)(location invariant) and its position (location variant). বিবেচনা করতে একক মডেলের দুটি মৌলিক পদক্ষেপগুলি একত্রিত করেছেন।
একটি ResNet-101 মডেল ইনপুট হিসাবে প্রাথমিক চিত্র নেয়। শেষ স্তর বৈশিষ্ট্য মানচিত্র আউটপুট, প্রতিটি এক অবস্থানে একটি বিভাগ সনাক্তকরণ বিশেষ। উদাহরণস্বরূপ, একটি বৈশিষ্ট্য মানচিত্রটি বিড়ালের সনাক্তকরণে, অন্য একটি কলা এবং অন্যান্য ক্ষেত্রে বিশেষ করে। এই বৈশিষ্ট্যগুলির মানচিত্রকে অবস্থান সংবেদনশীল সংবেদনশীল মানচিত্র বলা হয় কারণ তারা একটি নির্দিষ্ট বস্তুর স্থানীয় স্থানীয়করণকে বিবেচনা করে। এটি k * k * (C + 1) স্কোর মানচিত্র ধারণ করে যেখানে ক স্কোর সংখ্যা মানচিত্র এবং C নম্বরগুলির সংখ্যা। এই সব মানচিত্র স্কোর ব্যাংক গঠন। মূলত, আমরা প্যাচ তৈরি করি যা একটি বস্তুর অংশকে চিনতে পারে। উদাহরণস্বরূপ, K = 3 জন্য, আমরা একটি বস্তুর 3x3 অংশ সনাক্ত করতে পারি।
সমান্তরালভাবে, আমাদের আগ্রহের অঞ্চল তৈরির জন্য একটি RPN চালানো দরকার (ROI)। অবশেষে, আমরা প্রতিটি RoI কে Bins মধ্যে কাটি এবং আমরা স্কোর ব্যাঙ্কের বিরুদ্ধে তাদের চেক করি। এই অংশের যথেষ্ট সক্রিয় হলে, patch vote ‘yes’, I recognized the object.
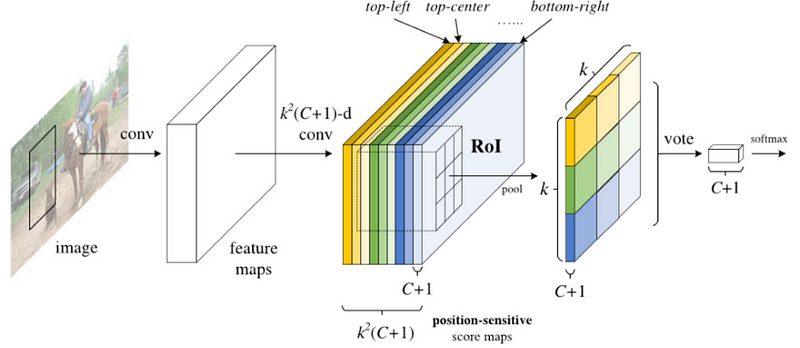
The input image feeds a ResNet model to produce feature maps. A RPN model detects the Region of Interests and a score is computed for each region to determine the most likely object if there is one. Source: J. Dai and al. (2016)
ইনপুট ইমেজ বৈশিষ্ট্য মানচিত্র উত্পাদন একটি ResNet মডেল ফিড। একটি RPN মডেল স্বার্থের অঞ্চল সনাক্ত করে এবং প্রতিটি অঞ্চলের জন্য যদি কোনও সম্ভাব্য বস্তু নির্ধারণ করতে একটি স্কোর গণনা করা হয়। উত্স: জেদাই এবং আল। (2016)
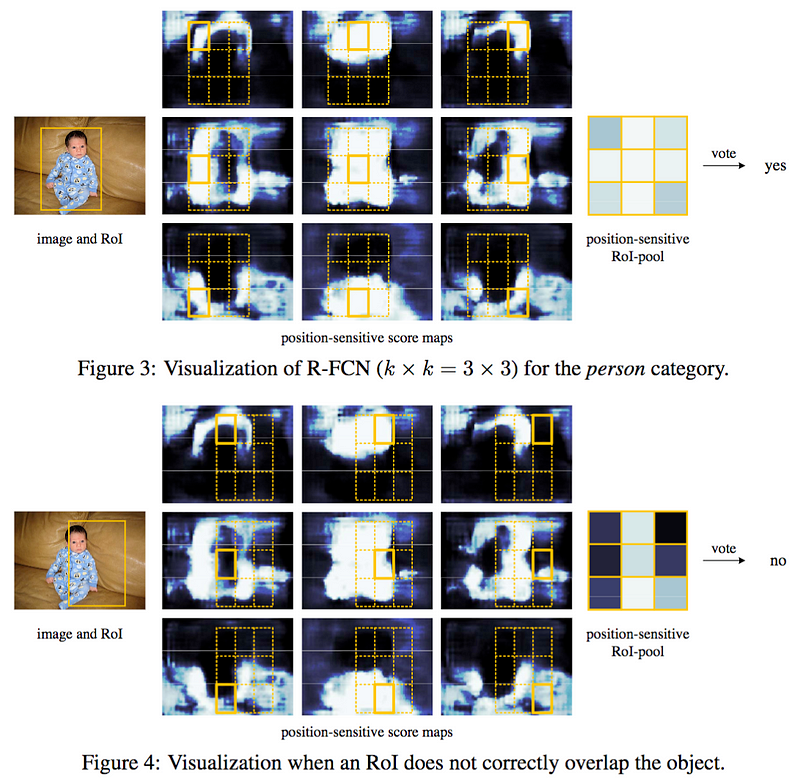
জেদাই এবং আল। (2016) নিচে প্রদর্শিত একটি উদাহরণ বিস্তারিত আছে। পরিসংখ্যান একটি ব্যক্তির সনাক্তকরণ মধ্যে একটি R-FCN মডেল প্রতিক্রিয়া প্রদর্শন। ইমেজ কেন্দ্রে একটি RoI (চিত্র 3) এর জন্য, বৈশিষ্ট্যের মানচিত্রগুলির উপগমনগুলি একটি ব্যক্তির সাথে সম্পর্কিত নিদর্শনগুলির জন্য নির্দিষ্ট। সুতরাং তারা 'হ্যাঁ, এই স্থানে একটি ব্যক্তি আছে' জন্য ভোট। চিত্র 4 এ, RoI ডান দিকে স্থানান্তরিত হয় এবং এটি আর ব্যক্তির উপর কেন্দ্রীভূত হয় না। বৈশিষ্ট্যের মানচিত্রের উপবিভাগগুলি ব্যক্তি সনাক্তকরণে একমত নয়, এইভাবে তারা 'না, এই স্থানে কোনও ব্যক্তি নেই' ভোট দেয়।
২007 পাসক্যাল ভিওসি পরীক্ষার ডেটাসেট এবং 82.0% এর জন্য সেরা R-FCNs 83.6% এর এমএপি স্কোরগুলিতে পৌঁছেছে, তাদের 2007, ২01২ পাসকাল ভিওসি ডেটাসেট এবং COCO ডেটাসেটের প্রশিক্ষণ দেওয়া হয়েছে। 2015 সিওসি চ্যালেঞ্জের পরীক্ষা-দ্টা Dve সেটের উপর, তাদের আইওইউ = 0.5 এবং 53.9% স্কোর সরকারী Map মেট্রিকের জন্য 53.2% স্কোর ছিল। লেখক লক্ষ্য করেছেন যে R-FCN to Fast R-CNN সদৃশের তুলনায় 2.5 থেকে ২0 গুণ বেশি দ্রুত।
You Only Look Once (YOLO)আপনি শুধুমাত্র একবার তাকান (YOLO)
YOLO মডেল (জে। রেডমোন এট আল।, 2016) সরাসরি একক মূল্যায়নে একক নেটওয়ার্ক সহ বদ্ধ বক্স এবং বর্গ সম্ভাবনাগুলির পূর্বাভাস দেয়। YOLO মডেলের সাদৃশ্য বাস্তব সময় পূর্বাভাস দেয়।
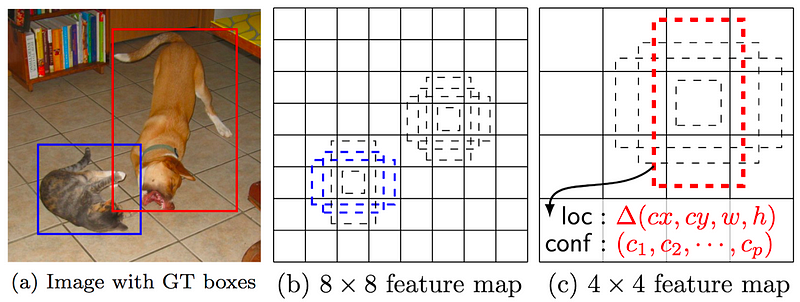
প্রাথমিকভাবে, মডেল ইনপুট হিসাবে একটি চিত্র লাগে। এটি একটি SxS গ্রিড মধ্যে এটি বিভক্ত। এই গ্রিডের প্রতিটি সেল একটি আত্মবিশ্বাসের স্কোরের সাথে B বদ্ধ বাক্সগুলি পূর্বাভাস দেয়। এই আস্থা কেবলমাত্র পূর্বাভাস এবং স্থল সত্য বক্সগুলির মধ্যে আইওইউ দ্বারা বস্তুর সংখ্যা সনাক্ত করার সম্ভাবনা।
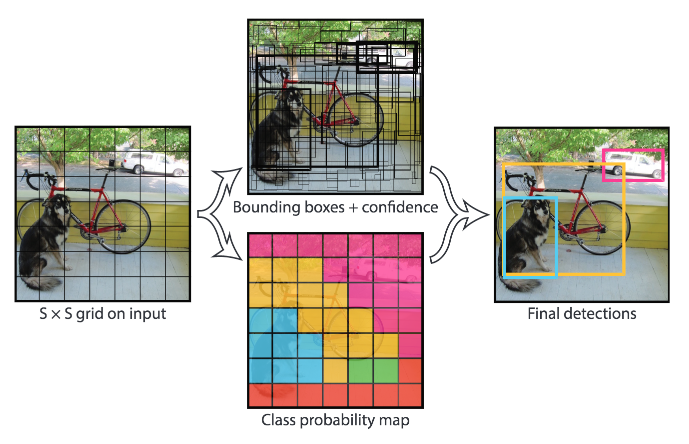
Example of application. The input image is divided into an SxS grid, B bounding boxes are predicted (regression) and a class is predicted among C classes (classification) over the most confident ones. Source: J. Redmon and al. (2016)
আবেদন উদাহরণ। ইনপুট চিত্রটি একটি SxS গ্রিডে বিভক্ত, বি বামিং বাক্সগুলির পূর্বাভাস দেওয়া হয় (প্রতিক্রিয়া) এবং একটি শ্রেণিকে সবচেয়ে বেশি আত্মবিশ্বাসী ব্যক্তির উপর সি ক্লাসগুলির (শ্রেণীবিভাগ) মধ্যে পূর্বাভাস দেওয়া হয়। উত্স: জে। রেডমোন এবং আল। (2016)
সিএনএন ব্যবহৃত GoogLeNet মডেল দ্বারা অনুপ্রেরণা মডিউল প্রবর্তন করে। নেটওয়ার্কের ২4 টি সংশ্লেষিক স্তর রয়েছে যা ২ টি সম্পূর্ণরূপে সংযুক্ত স্তর দ্বারা অনুসরণ করে। 1x1 ফিল্টারগুলির সাথে হ্রাস স্তর 3x3 সংশ্লেষ স্তরগুলি প্রাথমিক সূচনা মডিউলগুলি প্রতিস্থাপন করে। দ্রুত YOLO মডেল একটি হালকা সংস্করণ মাত্র 9 সংহত স্তর এবং কম সংখ্যক ফিল্টারগুলির সাথে। সংগ্রাহক স্তরগুলির অধিকাংশই শ্রেণীবিভাগ সহ চিত্রনেট ডেটাসেট ব্যবহার করে প্রিন্ট করা হয়। চারটি কনভোলিউশন লেয়ার দুটি সম্পূর্ণরূপে সংযুক্ত লেয়ার অনুসরণ করে পূর্ববর্তী নেটওয়ার্কে যোগ করা হয় এবং এটি সম্পূর্ণভাবে ২007 এবং ২01২ প্যাসকেল ভিওসি ডেটাসেটগুলির সাথে পুনরুদ্ধার করা হয়।
চূড়ান্ত স্তর গ্রিডের প্রতিটি কোষের পূর্বাভাস অনুসারে একটি
S*S*(C+B*5) tensor আউটপুট করে। C প্রতিটি বর্গ জন্য আনুমানিক সম্ভাবনা সংখ্যা। B প্রতি কক্ষে নোঙ্গর বাক্সগুলির নির্দিষ্ট সংখ্যা, এই বাক্সগুলির মধ্যে প্রতিটি 4 টি সমন্বয় (বক্স, প্রস্থ এবং উচ্চতার কেন্দ্রের সমন্বয়) এবং আস্থা মান সম্পর্কিত।
আগের মডেলগুলির সাথে, পূর্বনির্ধারিত আবদ্ধ বাক্সগুলিতে প্রায়ই একটি বস্তু থাকে। YOLO মডেল যদিও একটি উচ্চ সংখ্যক আবদ্ধ বাক্স ভবিষ্যদ্বাণী। সুতরাং কোন বস্তু ছাড়া অনেক আবদ্ধ বাক্স আছে। Non-Maximum Suppression (NMS) পদ্ধতি নেটওয়ার্ক শেষে প্রয়োগ করা হয়। এটি একটি একই বস্তুর অত্যন্ত merging highly-overlapping bounding boxes একটি একই সঙ্গে গঠিত। এখনও কয়েক মিথ্যা ইতিবাচক সনাক্ত করা আছে লক্ষ্য।

YOLO architecture: it is composed of 24 convolutional layers and 2 fully-connected layers. Source: J. Redmon and al. (2016)YOLO আর্কিটেকচার: এটি 24 সংহত স্তর এবং 2 সম্পূর্ণরূপে সংযুক্ত স্তর গঠিত হয়। উত্স: জে। রেডমোন এবং আল। (2016)
YOLO মডেলটি 2007 পাসক্যাল ভিওসি ডেটাসেটে 63.7% এমএপি স্কোর এবং 2012 পাসক্যাল ভিওসি ডেটাসেটে 57.9% এমএপি স্কোর। দ্রুত YOLO মডেল কম স্কোর আছে কিন্তু তারা বাস্তব ও সময় পারফরমেন্স উভয় আছে।
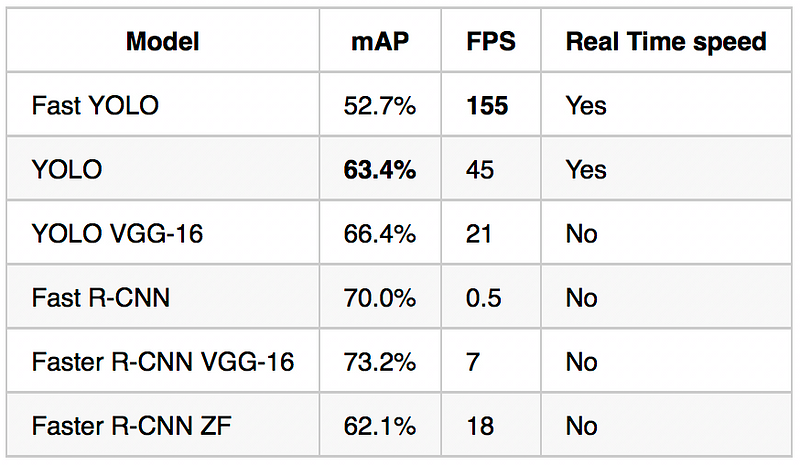
Real Time Systems on PASCAL VOC 2007. Comparison of speeds and performances for models trained with the 2007 and 2012 PASCAL VOC datasets. The published results correspond to the implementations of J. Redmon and al. (2016).PASCAL VOC 2007 এর রিয়েল টাইম সিস্টেম। ২007 এবং ২01২ প্যাসকাল ভিওসি ডেটাসেটগুলির সাথে প্রশিক্ষিত মডেলের গতি এবং পারফরম্যান্সের তুলনা। প্রকাশিত ফলাফল জে Redmon এবং আল বাস্তবায়নের সাথে সামঞ্জস্যপূর্ণ। (2016)।
Single-Shot Detector (SSD)একক শট আবিষ্কারক (এসএসডি)
একইভাবে YOLO মডেল, W. Liu et al. (2016) একটি সিঙ্গল-শট ডিটেক্টর (এসএসডি) তৈরি করেছে যা একেবারে সীমানার বাক্স এবং ক্লাসের সম্ভাব্যতাগুলি শেষ-থেকে-শেষ সিএনএন আর্কিটেকচারের সাথে ভবিষ্যদ্বাণী করে।
মডেলটি এমন একটি চিত্র গ্রহণ করে যা ইনপুট যা বিভিন্ন আকারের ফিল্টার (10x10, 5x5 এবং 3x3) সহ একাধিক সংশ্লেষিক স্তরের মধ্য দিয়ে যায়। নেটওয়ার্কে বিভিন্ন অবস্থানে কনভোলিউশনাল স্তর থেকে বৈশিষ্ট্য মানচিত্রগুলি বদ্ধ বাক্সগুলি পূর্বাভাসের জন্য ব্যবহার করা হয়। ফাস্ট রে-সিএনএন এর নোঙ্গর বাক্সগুলির মতো আবদ্ধ বাক্সগুলির একটি সেট উত্পাদন করতে অতিরিক্ত বৈশিষ্ট্য স্তরগুলির নামক 3x3 ফিল্টারগুলির সাথে একটি নির্দিষ্ট সংশ্লেষিক স্তরের দ্বারা প্রক্রিয়া করা হয়।
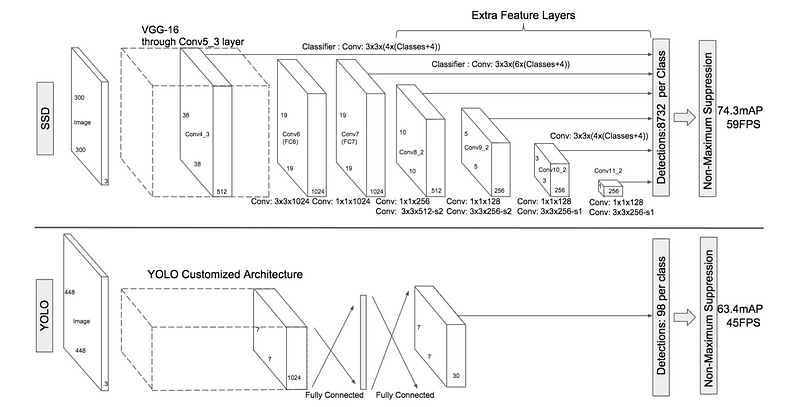
Comparison between the SSD and the YOLO architectures. The SSD model uses extra feature layers from different feature maps of the network in order to increase the number of relevant bounding boxes. Source: W. Liu and al. (2016)
এসএসডি এবং YOLO আর্কিটেকচারের মধ্যে তুলনা। এসএসডি মডেল প্রাসঙ্গিক সীমানা বাক্সের সংখ্যা বাড়ানোর জন্য নেটওয়ার্কের বিভিন্ন বৈশিষ্ট্য মানচিত্র থেকে অতিরিক্ত বৈশিষ্ট্য স্তর ব্যবহার করে। উত্স: w লিউ এবং আল। (2016)
প্রতিটি বাক্সে 4 parameters রয়েছে: কেন্দ্র, প্রস্থ এবং উচ্চতার সমন্বয়কারী the coordinates of the center, the width and the height.। একই সময়ে, এটি বস্তুর প্রতিটি শ্রেণীর উপর আত্মবিশ্বাসের সাথে সম্ভাব্যতার একটি ভেক্টর তৈরি করে।
সর্বাধিক প্রাসঙ্গিক বাঁধন বাক্সগুলি রাখার জন্য এসএসডি মডেলের শেষে নন-সর্বাধিক দমন(Non-Maximum Suppression) পদ্ধতিটি ব্যবহার করা হয়। Hard Negative Mining(HNM) তারপর ব্যবহার করা হয় কারণ অনেক নেতিবাচক বক্স এখনও পূর্বাভাস করা হয়। এটি প্রশিক্ষণের সময় এই বাক্সগুলির শুধুমাত্র একটি subpart নির্বাচন করে গঠিত। বাক্সগুলি আস্থা দ্বারা আদেশ দেওয়া হয় এবং শীর্ষটি 1/3 এর বেশি নেতিবাচক এবং ইতিবাচক সমীকরণের অনুপাতের ভিত্তিতে নির্বাচিত হয়।
W. Liu et al. (2016) SSD300 মডেলটি (the architecture is detailed on the figure above) এবং SSD 512 মডেলটি যা SSD 300, পারফরম্যান্স উন্নত করার জন্য ভবিষ্যদ্বাণী করার জন্য অতিরিক্ত সংশ্লেষ স্তর সহ পার্থক্য করে। সেরা এসএসডি মডেলগুলি ২007, ২01২ পাসকাল ভিওসি ডেটাসেট এবং ২015 কোকো ডেটাসেটের সাথে ডাটা বর্ধিতকরণের সাথে প্রশিক্ষিত। ২007 পাসকাল ভিওসি পরীক্ষার ডেটাসেটে তারা 83.2% এর এমএপি স্কোর অর্জন করেছে এবং ২01২ পাসকাল ভিওসি পরীক্ষার ডেটাসেটে 82.2% পেয়েছে। 2015 সিওসি চ্যালেঞ্জের পরীক্ষা-ডে ডেটাসেটে, তাদের আইওইউ = 0.5, 30.3% স্কোরের আইওইউ = 0.75 এবং 31.5% সরকারী এমএপি মেট্রিকের জন্য 48.5% স্কোর রয়েছে।
YOLO9000 and YOLOv2
J. Redmon and A. Farhadi (2016) লেখকদের মতে প্রায় বাস্তব সময়ে চলমান 9000 টিরও বেশি বস্তু বিভাগ সনাক্ত করার জন্য YOLO9000 নামে একটি নতুন মডেল প্রকাশ করেছে। তারা তার গতি কমিয়ে ছাড়াই তার কর্মক্ষমতা উন্নত করার জন্য প্রাথমিক YOLO মডেলের উপর উন্নতি প্রদান করে around 10 images per second on a recent mobile according to our implementation (আমাদের বাস্তবায়নের অনুসারে সাম্প্রতিক মোবাইলের প্রতি সেকেন্ডে প্রায় 10 টি চিত্র)।
YOLOv2
YOLOv2 মডেল এখনও একটি দ্রুত আবিষ্কারক হচ্ছে সঠিকতা উন্নতির উপর দৃষ্টি নিবদ্ধ করা হয়। ব্যাচ স্বাভাবিকীকরণ ড্রপআউট ব্যবহার না করে overfitting প্রতিরোধ করা হয়। উচ্চ রেজোলিউশন চিত্রগুলি ইনপুট হিসাবে গ্রহণ করা হয়: YOLO মডেলটি 448x448 ছবি ব্যবহার করে, যখন YOLOv2 608x608 চিত্রগুলি ব্যবহার করে, এভাবে সম্ভাব্য ছোট বস্তুর সনাক্তকরণ সক্ষম করে।
YOLO মডেলের চূড়ান্তভাবে সংযুক্ত স্তরটি সীমানা বাক্সগুলির সমন্বয়কারীদের পূর্বাভাস দিয়ে দ্রুততর আর-সিএনএন হিসাবে অ্যাংকার বক্সগুলি ব্যবহার করার জন্য সরানো হয়েছে। ইনপুট চিত্রটি কোষগুলির একটি গ্রিডে হ্রাস করা হয়, প্রতিটিতে 5 অ্যাঙ্কর বাক্স রয়েছে। YOLOv2 YOLO মডেলের জন্য 98 বক্সের পরিবর্তে 19 * 19 * 5 = 1805 অ্যাঙ্কর বাক্সগুলি ইমেজ দ্বারা ব্যবহার করে। YOLOv2 গ্রিড সেলের অবস্থানের সাথে সম্পর্কিত নোঙ্গর বাক্সের সংশোধন পূর্বাভাস দেয় (পরিসীমাটি 0 এবং 1 এর মধ্যে) এবং এসএসডি মডেল হিসাবে তাদের আত্মবিশ্বাস অনুসারে বাক্সগুলি নির্বাচন করে। bounding boxes প্রশিক্ষণ সেটের উপর কে-মিড ব্যবহার করে অ্যাঙ্কর বাক্সের মাত্রা নির্ধারণ করা হয়েছে।
এটি ছোট বস্তুর সনাক্তকরণের জন্য উচ্চ এবং নিম্ন রেজোলিউশনের বৈশিষ্ট্য মানচিত্রগুলি স্ট্যাক করতে ResNet- র মতো আর্কিটেকচার ব্যবহার করে। "ডার্কনেট -19" 3x3 এবং 1x1 ফিল্টারগুলির সাহায্যে 19 টি সংশ্লেষক স্তরের সমন্বয় করা হয়, আউটপুট মাত্রা হ্রাস করার জন্য সংশ্লেষ স্তরগুলির গ্রুপগুলি সর্বাধিক স্তরগুলি অনুসরণ করে। একটি চূড়ান্ত 1x1 সংশ্লেষক স্তর 5 টি সমন্বয় সহ প্রতিটি গ্রিডের 5 টি বাক্সে এবং প্রতিটি 20 টি সম্ভাব্য (20 classes of the PASCAL VOC dataset) আউটপুট করে।
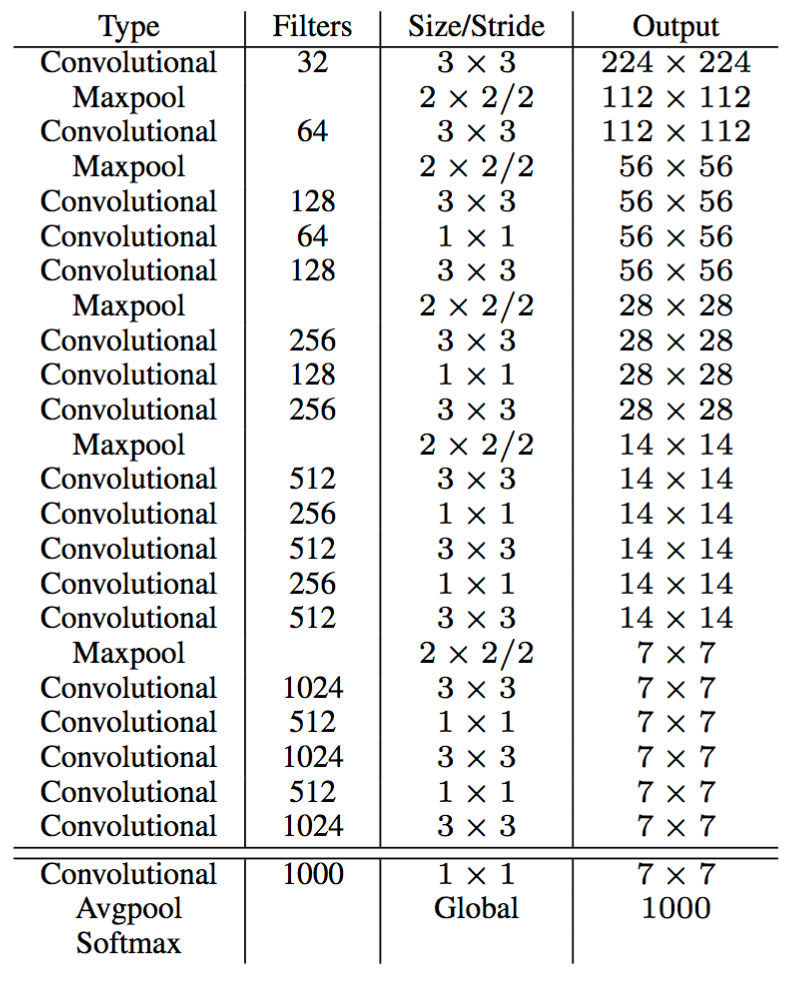
YOLOv2 architecture. Source: J. Redmon and A. Farhadi (2016)
২005 এবং 2012 পাসকাল ভিওসি ডেটাসেটের সাথে প্রশিক্ষিত YOLOv2 মডেলটি 2007 প্যাসকেল ভিওসি পরীক্ষার ডেটাসেটে 40.6% এর একটি FPS মান সহ 78.6% এমএপি স্কোর রয়েছে। ২015 COCO ডেটাসেটের সাথে প্রশিক্ষিত মডেলটিতে পরীক্ষামূলক ডেভ ডেটাসেটের উপর এমএপি স্কোর রয়েছে একটি আইওইউ = 0.5, 44% একটি আইওইউ = 0.75 এবং 19.6% অফিসিয়াল এমএপি মেট্রিকের জন্য 19.2%।
YOLO9000
লেখকগুলি সঠিক বস্তু বা পশু প্রজাতির সনাক্তকরণ করতে সক্ষম একটি মডেল আছে যাতে COCO ডেটাসেটের সাথে ImageNet ডেটাসেট সংযুক্ত করেছে। শ্রেণীবদ্ধকরণের জন্য ImageNet ডেটাসেটটিতে 1000 বিভাগ এবং 2015 COCO ডেটাসেটের কেবলমাত্র 80 বিভাগ রয়েছে। ImageNet ক্লাসগুলি প্রিন্সটন ইউনিভার্সিটি দ্বারা উন্নত WordNet লেক্সিকন(WordNet lexicon developed) উপর ভিত্তি করে তৈরি করা হয়েছে যা ২0,000 এর বেশি শব্দ ধারণ করে। J. Redmon and A. Farhadi (2016) ওয়ার্ডনেটের tree version তৈরির একটি পদ্ধতির বিস্তারিত বিবরণ দিয়েছেন।যখন মডেলটি একটি ছবিতে ভবিষ্যদ্বাণী করে তখন একই hyponym সঙ্গে লেবেলের একটি গোষ্ঠীতে একটি সফটম্যাক্স প্রয়োগ করা হয়। সুতরাং একটি লেবেলের সাথে যুক্ত চূড়ান্ত সম্ভাবনা গাছের পরবর্তী সম্ভাবনার সাথে গণনা করা হয়। লেখক নীচের প্রতিনিধিত্বমূলক বিভাগগুলিকে বাদ দিয়ে সমগ্র ওয়ার্ননেট লেক্সিকনটির ধারণাটি প্রসারিত করলে, 9 000 টিরও বেশি বিভাগে এটি পাওয়া যায়।
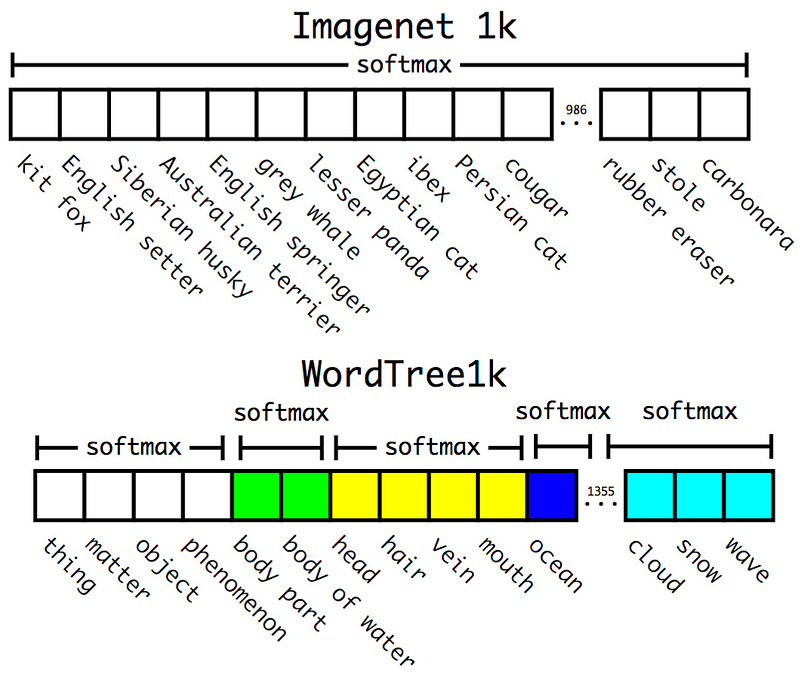
Prediction on ImageNet vs WordTree. Source: J. Redmon and A. Farhadi (2016)
COCO এবং ImageNet ডেটাসেটগুলির মধ্যে একটি সমন্বয়টি YOLOv2- এর মতো আর্কিটেকচারকে 5 টির পরিবর্তে আউটপুট সাইজ সীমাবদ্ধ করার পরিবর্তে 3 পূর্বে কনভোলিউশন স্তরগুলি প্রশিক্ষণের জন্য ব্যবহার করা হয়। প্রায় ২00 লেবেল সহ সনাক্তকরণ টাস্কের জন্য চিত্রটিনেট ডেটাসেটে মডেলটি মূল্যায়ন করা হয়। প্রশিক্ষণ এবং পরীক্ষার ডেটাসেটের মধ্যে কেবলমাত্র 44 টি লেবেল ভাগ করা হয়েছে যাতে ফলাফল কিছুটা অপ্রাসঙ্গিক। এটি একটি 19.7% এমএপি স্কোর সামগ্রিকভাবে পরীক্ষা ডেটাসেট পায়।
Neural Architecture Search Net (NASNet)নিউরাল আর্কিটেকচার অনুসন্ধান নেট (NASNET)
নিউরাল আর্কিটেকচার অনুসন্ধান (B. Zoph and Q.V. Le, 2017)আমার previous post বিস্তারিত। এটি একটি প্রদত্ত ডেটাসেটের উপর নির্ভুলতা উন্নত করার সময় স্তরের সংখ্যাটি অপ্টিমাইজ করার জন্য একটি মডেলের আর্কিটেকচার শিখতে গঠিত। B. Zoph et al. (2017) ২01২ সালের 2012 ImageNet classification challenge আগের আগের চেয়ে lighter model সাথে উচ্চতর পারফরম্যান্সে পৌঁছেছে।
লেখক, স্থানিক বস্তুর সনাক্তকরণ এই পদ্ধতি প্রয়োগ করেছেন। ন্যাশনেট নেটওয়ার্কটি CIFAR-10 ডেটাসেট থেকে শিখেছে, একটি স্থাপত্য এবং 2012 ইমেজনেট ডেটাসেটের সাথে প্রশিক্ষিত। এই মডেল বৈশিষ্ট্য মানচিত্র প্রজন্মের জন্য ব্যবহার করা হয় এবং দ্রুত R-CNN পাইপলাইনে স্ট্যাক করা হয়। তারপর পুরো পাইপলাইনকে COCO ডেটাসেটের সাথে আটকানো হয়।
বস্তু সনাক্তকরণের জন্য সেরা NASNet মডেলগুলি একটি IoU = 0.5 দিয়ে COCO চ্যালেঞ্জের পরীক্ষামূলক-dev dataset 43.1% mAP স্কোর অর্জন করেছে। মোবাইলের জন্য অপ্টিমাইজ হওয়া NASNET এর লাইটার সংস্করণটি একই ডেটাসেটে ২9.6% mAP স্কোর রয়েছে।

Example of object detection results. Comparison of Faster R-CNN pipelines one is using Inception-ResNet as feature maps generator (top) and the other the NASNet model (bottom). Source: B. Zoph and al. (2017)বস্তুর সনাক্তকরণ ফলাফল উদাহরণ। ফাস্ট আর-সিএনএন পাইপলাইনের তুলনা ইনস্পেস-রেসনেটটি বৈশিষ্ট্য মানচিত্র জেনারেটর (শীর্ষ) এবং অন্যটি NASNet মডেল (নীচে) হিসাবে ব্যবহার করছে। উত্স: বি। সোফ এবং আল। (2017)
Mask Region-based Convolutional Network (Mask R-CNN)মাস্ক অঞ্চল ভিত্তিক কনভোলিউশনাল নেটওয়ার্ক (মাস্ক আর-সিএনএন)
K. He and al. (2017) ফস্টার আর-সিএনএন মডেলের আরেকটি এক্সটেনশন প্রকাশ করা হয়েছে। বস্তু মাস্ক পূর্বাভাস করার জন্য সীমানা বাক্স সনাক্তকরণ একটি সমান্তরাল শাখা যোগ। একটি বস্তুর মাস্কটি একটি চিত্রের পিক্সেল দ্বারা এটির বিভাজন। এই মডেলটি চারটি COCO চ্যালেঞ্জগুলির মধ্যে অত্যাধুনিক অতীতকে অতিক্রম করে: উদাহরণ বিভাজন, বদ্ধ বাক্স সনাক্তকরণ, বস্তুর সনাক্তকরণ এবং কী বিন্দু সনাক্তকরণ।instance segmentation, the bounding box detection, the object detection and the key point detection.

Examples of Mask R-CNN application on the COCO test dataset. The model detects each object of an image, its localization and its precise segmentation by pixel. Source: K. He and al. (2017)COCO পরীক্ষার ডেটাসেটে মাস্ক আর-সিএনএন অ্যাপ্লিকেশনের উদাহরণ। মডেল একটি চিত্র, তার স্থানীয়করণ এবং পিক্সেল দ্বারা তার সুনির্দিষ্ট segmentation প্রতিটি বস্তুর সনাক্ত। উত্স: কে। তিনি এবং আল। (2017)
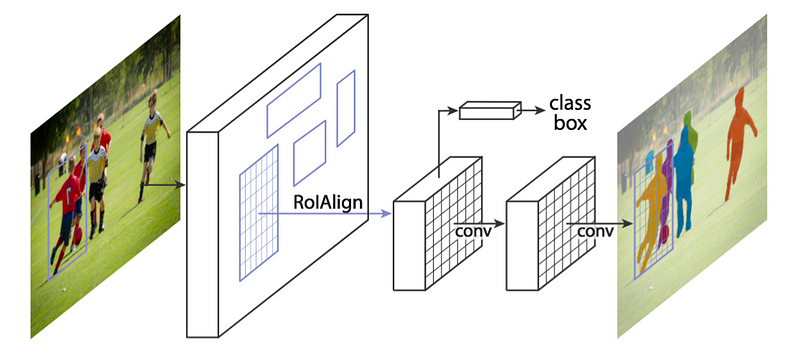
মাস্ক অঞ্চল ভিত্তিক কনভোলিউশনাল নেটওয়ার্ক (মাস্ক আর-সিএনএন) প্রতিটি প্রার্থী বস্তুর জন্য তিনটি আউটপুট শাখার সাথে দ্রুততর-সিএনএন পাইপলাইন ব্যবহার করে: একটি বর্গ লেবেল, একটি আবদ্ধ বাক্স অফসেট এবং বস্তু মাস্ক। এটি সীমানা বাক্স প্রস্তাবগুলি তৈরি করতে অঞ্চল প্রস্তাব নেটওয়ার্ক (RPN) ব্যবহার করে এবং প্রতিটি অঞ্চলের আগ্রহের জন্য (ROI) একই সময়ে তিনটি আউটপুট তৈরি করে।
ফস্টার আর-সিএনএন ব্যবহৃত প্রাথমিক RoIPool স্তরটি RoIAlign স্তর দ্বারা প্রতিস্থাপিত হয়। এটি মূল RoI এর সমন্বয়গুলির পরিমানীকরণকে সরিয়ে দেয় এবং অবস্থানগুলির সঠিক মানগুলি গণনা করে। ROIAlign স্তরটি অঞ্চল প্রস্তাবগুলির সাথে স্কেল-সমষ্টিগত এবং অনুবাদ-সমষ্টিগত সরবরাহ সরবরাহ করে।
মডেল ইনপুট হিসাবে একটি চিত্র লাগে এবং 101 লেয়ার সহ ResNeXt নেটওয়ার্ক ফিড করে। এই মডেলটি রেজনেটের মতো মনে হচ্ছে তবে প্রতিটি অবশিষ্ট ব্লকটি ব্লাইট স্পষ্টতাগুলিতে কাটানো হয় যা ব্লকের স্পারসিটি যোগ করার জন্য সংহত করা হয়। মডেল RoIs সনাক্ত করে যা RoIAlign লেয়ার ব্যবহার করে প্রক্রিয়া করা হয়। নেটওয়ার্কের একটি শাখা সীমানা বাক্সের সমন্বয় এবং বস্তুর সাথে সম্পর্কিত সম্ভাব্যতাগুলির গণনা করার জন্য একটি সম্পূর্ণরূপে সংযুক্ত স্তরযুক্ত করা হয়। অন্য শাখার দুটি সংশ্লেষ স্তরগুলির সাথে যুক্ত করা হয়, শেষটি সনাক্তকৃত বস্তুর মাস্কটি গণনা করে।
সমাধান প্রতিটি টাস্ক সংশ্লিষ্ট তিনটি ক্ষতি ফাংশন সংক্ষেপে হয়। এই সংখ্যার ক্ষুদ্রীকরণ এবং বিরাট পারফরম্যান্স উত্পাদন করে কারণ সেগমেন্টেশন টাস্কটি স্থানীয়করণ উন্নত করে এবং এভাবে শ্রেণীবিভাগটি উন্নত করে।
মাস্ক R-CNN 62.3% mAP স্কোর অর্জন করেছে,একটি IoU = 0.5, একটি IoU = 0.7 জন্য 43.4%এবং ২013 সালের COCO-Dev ডেটাসেটে Official মেট্রিকের জন্য 39.8%।
উপসংহার
বছরের পর বছর ধরে, বস্তু সনাক্তকরণ মডেলগুলি একবারে সম্পূর্ণরূপে আলাদা নেটওয়ার্ক থাকা স্থানীয়করণ এবং শ্রেণিবিন্যাসকে নির্ণয় করতে থাকে। সুতরাং এটি back propagation সঙ্গে মাথা থেকে লেঙ্গুড় প্রশিক্ষিত করা যেতে পারে। তাছাড়া, সাম্প্রতিক মডেলগুলির মধ্যে উচ্চ কার্যকারিতা এবং রিয়েলটাইম পূর্বাভাসের ক্ষমতার মধ্যে একটি বন্ধ করা হয়।
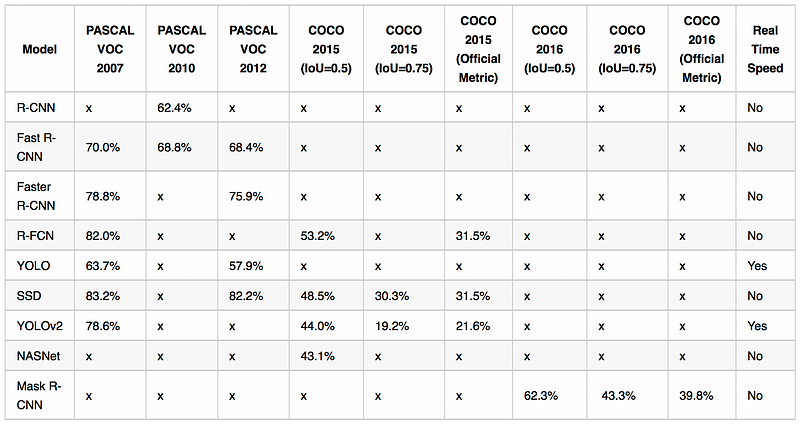
Overview of the mAP scores on the 2007, 2010, 2012 PASCAL VOC dataset and 2015, 2016 COCO datasets.২007, ২010, ২01২ পাসকাল ভিওসি ডেটাসেট এবং ২015, 2016 কোকো ডেটাসেটগুলিতে এমএপি স্কোরগুলির সংক্ষিপ্তসার।
এই ব্লগ পোস্টে উপস্থাপিত মডেলগুলি নিখরচায় সঠিক বা দ্রুত। যাইহোক, তারা সব জটিল এবং ভারী স্থাপত্য আছে। উদাহরণস্বরূপ, YOLOv2 মডেলটি প্রায় ২00 এমবি এবং সর্বনিম্ন NASNet প্রায় 400 এমবি। একই পারফরম্যান্স পালন করার সময় আকার হ্রাস করা, মোবাইল ডিভাইসগুলিতে গভীর শিক্ষার মডেলগুলি এম্বেড করার জন্য গবেষণার একটি সক্রিয় ক্ষেত্র। কিছু বিবরণ একটি আসন্ন পোস্টে প্রদান করা হবে।
- সম্পূর্ণ স্থাপত্যটি VGG16 মডেল থেকে অনুপ্রাণিত, এভাবে এটিতে 13 ক্রভোলিউশনের স্তর এবং 3 সম্পূর্ণরূপে সংযুক্ত স্তর রয়েছে।
- দ্রুততম দ্রুততর আর-সিএনএন M.D. Zeiler and R. Fergus (2013) দ্বারা উপস্থাপিত ZFNet মডেল দ্বারা অনুপ্রাণিত একটি স্থাপত্য। সাধারণভাবে ব্যবহৃত ফস্টার আর-সিএনএনটিতে ভিজিজি 16 মডেলের মতো একটি স্থাপত্য রয়েছে এবং দ্রুত আর-সিএনএন থেকে 10 গুণ দ্রুত।
- সম্পূর্ণ স্তর যা সম্পূর্ণরূপে সংযুক্ত স্তর ছাড়া
- এটি পূর্ববর্তী স্তর থেকে বৈশিষ্ট্য স্থান হ্রাস করে।
- বিস্তারিত পূর্ববর্তী ব্লগ পোস্টে প্রদান করা হয়।
0 comments:
Post a Comment