The title of this paper is "Rich feature hierarchies for accurate oject detection and semantic segmentation". The translation is a multi-feature hierarchy for high-accuracy target detection and semantic segmentation. In popular terms, it is a target detection and semantics. Segmented neural network.
Author: Ross Girshick, JeffDonahue, TrevorDarrell, Jitendra Malik.
This paper was published in 2014, and it has a lot of significance.
- On the data set of Pascal VOC 2012, the verification indicator mAP of target detection can be increased to 53.3%, which is a 30% improvement over the previous best result.
- This paper proves that neural networks can be applied to candidate regions from the bottom up, so that target classification and target positioning can be performed.
- This paper also brings a point of view, when you lack a lot of labeled data, a better and feasible method is to perform transfer learning of neural networks, use neural networks trained on other large data sets, and then Fine-tune fine tuning in small specific data sets
What is target detection:
Given a picture to identify the category is, object recognition.

For example, the above image needs to predict the object category as cat.
The target detection in addition to identifying category, but also to find their place.
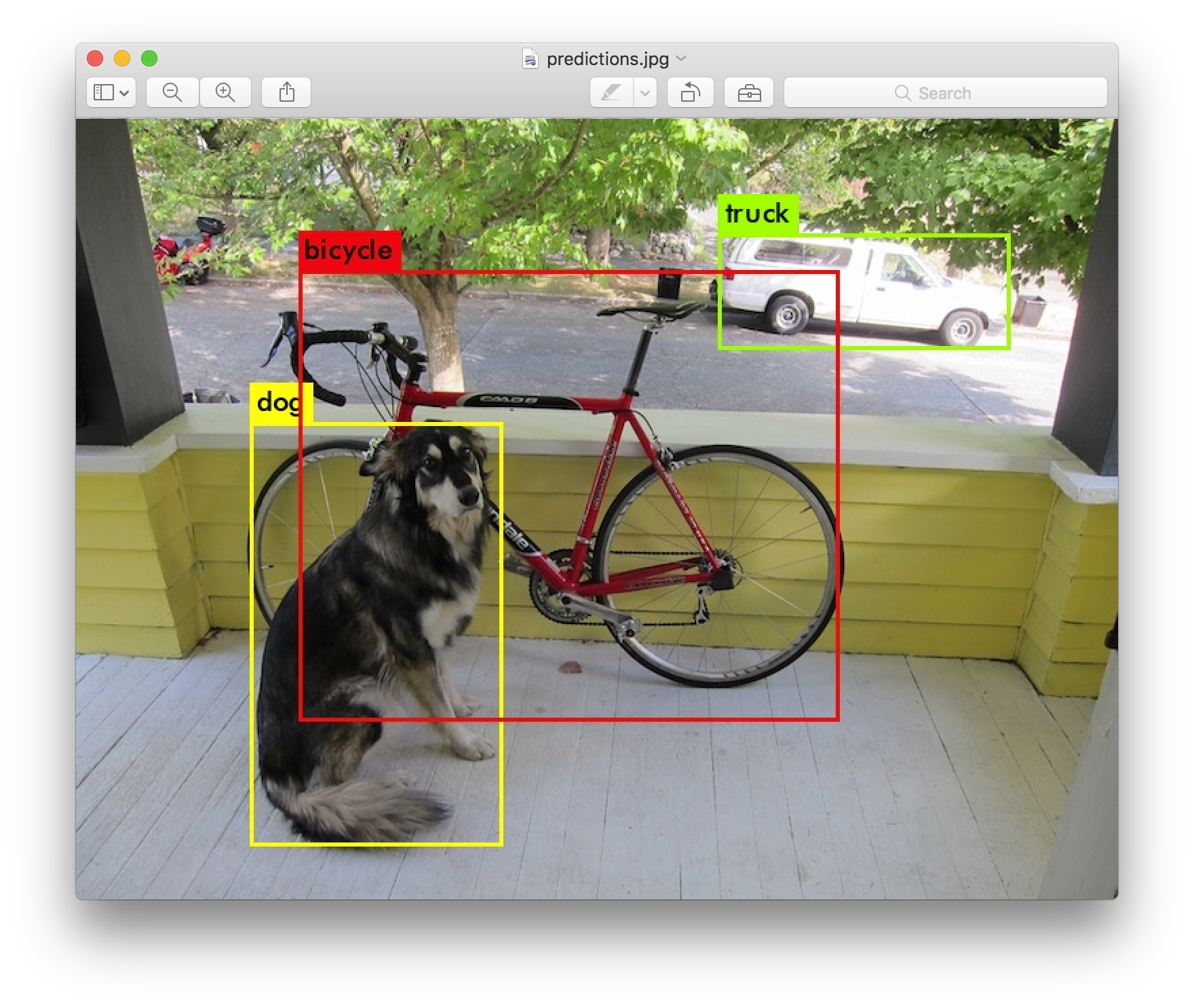
Obviously, Object detection is more difficult than object recognition.
R-CNN walks on the shoulders of predecessors
In the past ten years or so, the traditional machine vision field usually uses feature descriptors to deal with target recognition tasks. The most common feature descriptors are SIFT and HOG. OpenCV has ready-made APIs for everyone to implement related operating.
The kingship of SIFT and HOG has recently been shaken by convolutional neural networks.
In 2012, Krizhevsky and others became famous in the ILSVRC target recognition challenge held by ImageNet, winning the first place of the year, and the Top5 error rate was 15%. The network structure proposed by their team was named after their mentor, which is AlexNet.
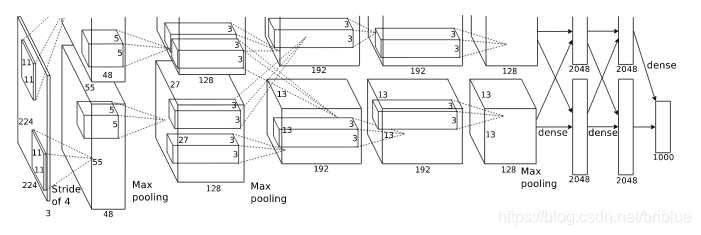
It has 5 convolutional layers and 2 fully connected layers.
Because of the emergence of AlexNet, the world's attention has returned to the field of neural networks. As an opportunity, various networks such as VGG, GoogleNet, ResNet, and so on have emerged.
Inspired by AlexNet, the authors attempt to generalize AlexNet's ImageNet object recognition capabilities to PASCAL VOC object detection.
But before everything starts, two main issues need to be addressed.
- How to use deep neural networks to locate targets?
- How to train a powerful network model on a small-scale data set?
The author of the paper gives the idea.
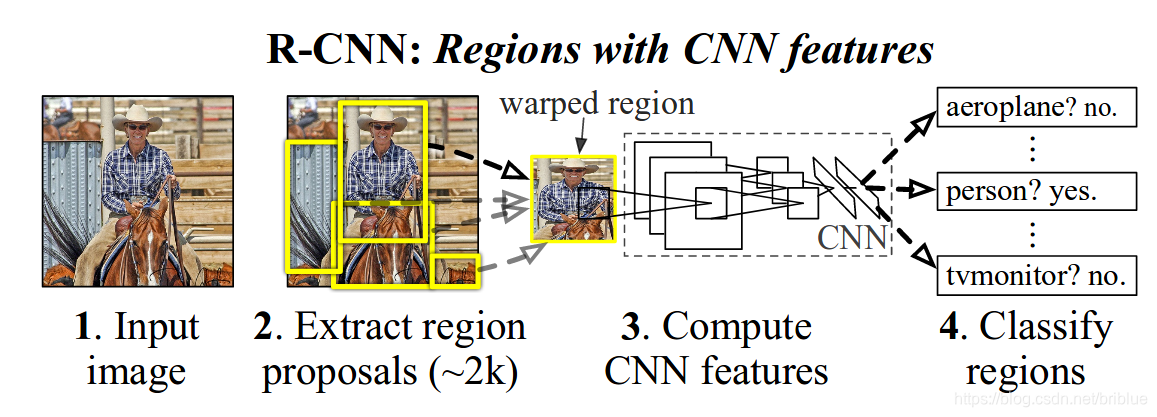
Using candidate areas and CNN for target positioning
Drawing on the idea of sliding windows, R-CNN uses a scheme for identifying regions.
specifically is:
- Given an input image, 2000 categories of independent candidate regions are extracted from the image.
- For each region, a fixed-length feature vector is extracted using CNN.
- Then use SVM for target classification for each area.
The image below is from the paper itself.
Use pre-training and fine-tuning to solve the problem of lack of labeled data
Take the model that has been trained on ImageNet, and then perform fine-tune on the PASCAL VOC dataset.
Because ImageNet's images are up to several million, using convolutional neural networks to fully learn shallow features and then doing large-scale training on small-scale data sets can achieve good results.
Now, what we call transfer learning is an essential skill.
R-CNN's road to target recognition
As mentioned earlier, the R-CNN system is divided into 3 stages, which are reflected in the architecture by 3 modules.
Produces candidate regions with independent categories. These candidate regions contain the final positioning results of R-CNN.
The neural network extracts fixed-length feature vectors for each candidate region.
A series of SVM classifiers.
Candidate area
There are many ways to generate candidate regions, such as:
objectness
selective search
category-independen object proposals
constrained parametric min-cuts (CPMC)
multi-scale combinatorial grouping
Ciresan
R-CNN uses the Selective Search algorithm.
Feature extraction
R-CNN extracts a 4096-dimensional feature vector, uses Alexnet, and develops code based on Caffe.
Note that the input image size of Alextnet is 227x227.
The size of the candidate areas generated by Selective Search is different. In order to be compatible with Alexnet, R-CNN uses a very violent method, that is, it ignores the size and shape of the candidate area and uniformly transforms to the size of 227 * 227.
There is a detail. When transforming Regions, these regions are first inflated, and p pixels are added around the box, that is, a border is artificially added, here p = 16.
Object detection during the test phase
During the test phase, R-CNN extracts nearly 2000 candidate regions on each image.
Then each candidate region is subjected to a trimming transformation of size, sent to a neural network to read features, and then uses SVM to identify the category and generate a score.
There are 2,000 candidate regions, so many will overlap.
For each class, by calculating the IoU index, taking non-maximum suppression , based on the region with the highest score, remove those areas that overlap.
Runtime analysis
Two factors can make target recognition efficient.
The parameters of the CNN are shared by all categories.
R-CNN generates fewer feature vectors. Compared with the spatial pyramid technology used in UVA, the paper generates feature dimensions of 360k, while R-cnn has more than 4K.
That is, during the operation, the parameters become less, so it is more efficient than the traditional ones.
Reflected in the time of feature extraction, if GPU is used, 13s / sheet, CPU 53s / sheet.
R-cnn is capable of processing 100k categories, and it only takes more than 10 seconds on a multi-core CPU.
Compared with UVA, if you process 100k predictions, you need 134GB of memory space, while R-CNN only needs 1.5GB.
training
As mentioned earlier, R-CNN adopts transfer learning.
Extract the model and weights in ILSVRC 2012, and perform fine-tune on VOC.
It should be noted that what is trained on ImageNet here is the ability of the model to recognize the type of object, not the ability to predict the position of the bbox.
ImageNet's training needs to predict 1000 categories, and when R-CNN performs transfer learning on VOC, the neural network only needs to identify 21 categories. These are the 20 categories defined by VOC plus the background category.
R-CNN compares the candidate region with the box label in GroundTrue. If IoU> 0.5, it means that two objects overlap more locations, so you can consider this candidate region to be Positive, otherwise it is Negetive.
The training strategy is: using SGD training, the initial learning rate is 0.001, and the mini-batch size is 128.
Object recognition related
A binary classifier is usually treated, and its result is only 2 of Positive and Negetive.
For example, if you have a car classifier that can easily confirm that a box contains a car, then it must be Positive.
It can also be clearly confirmed that if a car is not included in a background box, it is Negetive.
However, it is more difficult to confirm that if a part of a box overlaps with a car, how to label this box?
R-CNN uses the threshold of IoU. This threshold is 0.3. If the IoU value of a region and Ground tureth is lower than the set threshold, then it can be regarded as Negetive.
IoU's threshold is not the author's random value, but the combination of values from {0,0.1,0.2,0.3,0.4,0.5}.
Moreover, this value is very important. If the threshold value is 0.5, the mAP index will drop by 5 points directly. If the value is 0, mAP will decrease by 4 points.
Once feature extraction is successful, R-CNN will use SVM to identify the category of each region, but this needs to be optimized.
Because the training data is too large to be filled into the computer's memory at once, the R-CNN author adopted a method called Hard negetive mining.
R-CNN performance at PASCAL-VOC 2010-12
R-CNN performs the final fine-tune at PASCAL VOC 2012, and also optimizes the SVM on the training set of VOC 2012.
Then, it was also compared with 4 powerful opponents at the time, that is, 4 different target detection algorithms.

It is worth noting that the UVA detection system in the above table also adopts the same candidate region algorithm, but R-CNN performs better than it.
Visualization, framework reduction and error detection
We all know that in convolutional neural networks, the first layer can be used directly for display and visible to the naked eye. Usually they are used to capture the edges of objects and prominent color information, but the later the convolutional layer is, the more abstract it is. Visualizing at this time is a challenge.
Zeiler and Fergus proposed a visualization study based on deconvolution, but the authors of R-CNN directly provided a method without parameters, which is simple and straightforward.
The idea is to pick a feature, treat it directly as an object classifier, and then calculate the activation value when they process different candidate regions. This value represents the response of the feature to this region, and then rank activation as the score. Take the first few, and then display these candidate areas. Naturally, you can clearly understand what this feature is about.
The author of R-CNN takes pool5 as a visualization object, and its feature map is 6x6x255. It can be understood that there are 256 small squares, and each square corresponds to a feature.
The following chart shows the effect of this visualization. Only 6 of the 256 features are shown here, and each feature takes the 16 areas with the highest activation value.

The above picture should be very clear. For the same type of features, activations are not much different, which is also a visual manifestation of the convolutional neural network's ability to accurately identify objects.
Streamlined framework
AlexNet has 7 layers, so what are the key indicators? Which layers are optional?
pool5 has been discussed in the previous section, then fc6 and f7 become the object of research.
fc6 and pool5 form a full connection. In order to calculate the feature, it is multiplied by a weight matrix of 4096x9216 and then added to a set of biases, so it has more than 37 million parameters.
fc7 is the last layer, its weight matrix is 4096x409, and its parameters have more than 16.78 million parameters.
However, after the author does not do fine-tune processing on PASCAL and directly tests, it can be found that fc7 is not as significant as fc6, and even after removing it, it has no effect on the mAP result indicators.
Removing fc7 means that nearly 18 million parameters can be reduced.
What's even more pleasant is that removing fc6 and fc7 at the same time does not have much loss, and the result is even better.
Therefore, the most amazing power of neural networks comes from the convolutional layer, not the fully connected layer.
The above is the case without fine-tune, so what is the situation with fine-tune?
The results prove that the effects of fc6 and fc7 increase after fine-tune are obvious.
So the conclusion is that pool5 learns the generalization ability of the object from the ImageNet training set, and the improvement of the ability is through the fine-tune of the specific domain.
For example, the neural network learned the characteristics of 100 cats in the ImageNet dataset, and my own data set only has two types of cats. After fine-tune training, this neural network can more accurately identify these two cats.
R-CNN also compares its capabilities with other feature methods. The author chose two DPM-based methods, DPM ST and DPM HSC. The results prove that R-CNN is better than them.
Object detection error analysis
The author of R-CNN uses the object detection and analysis tool proposed by Hoiem to visually expose the wrong model. The author uses this tool to perform fine-tune in a targeted manner.
bbox returns
The value of bbox is actually the position of the object box. Predicting it is a regression problem, not a classification problem.
Inspired by DPM, the author trained a linear regression model that can predict a new box position for pool5 data in the candidate area. Specific details, the author put in supplementary materials.
Semantic segmentation
What is semantic segmentation?
Region classification technology is the standard method of semantic segmentation, so R-CNN can also do semantic segmentation, and the author compares it with O2P.
The semantic segmentation of R-CNN is divided into three stages.
Use CPMC to generate candidate regions, and then resize these regions to 227x227 and send them to the neural network. This is the full stage. There are backgrounds and prospects in the regions.
In this stage, only the foreground of the candidate region is processed. The background is replaced by the input average value, and then the background becomes 0. This stage is called fg.
Full + fg stage, simple stitching of background and foreground.
review
R-CNN uses AlexNet
R-CNN uses Selective Search technology to generate Region Proposal.
R-CNN is pre-trained on ImageNet, then fine-tuned on the PASCAL VOC dataset using mature weight parameters
R-CNN uses CNN to extract features, and then uses a series of SVMs for class prediction.
R-CNN's bbox position regression is based on the inspiration of DPM and trained a linear regression model on its own.
Semantic segmentation of R-CNN uses CPMC to generate regions
R-CNN flexibly used the existing advanced tools and technologies, fully absorbed them, and transformed according to its own logic, and finally made great progress.
By 2018, R-CNN is no longer the most advanced object detection model or the most advanced semantic segmentation model, but the most significant significance of this paper is to show the author how to integrate existing advanced technologies to solve the problem in the absence of resources Means of own problems.
In addition to R-CNN, there are some excellent target detection algorithms. I personally love YOLO. Interested students can check out this article.
পটভূমি
এই কাগজের শিরোনামটি হ'ল "Rich feature hierarchies for accurate oject detection and semantic segmentation/যথাযথ অবজেক্ট সনাক্তকরণ এবং শব্দার্থ বিভাজনের জন্য সমৃদ্ধ বৈশিষ্ট্যক্রম"। অনুবাদটি উচ্চ-নির্ভুলতার লক্ষ্য সনাক্তকরণ এবং শব্দার্থক বিভাগের জন্য একাধিক বৈশিষ্ট্যযুক্ত শ্রেণিবিন্যাস। জনপ্রিয় ভাষায়, এটি একটি লক্ষ্য সনাক্তকরণ এবং শব্দার্থবিজ্ঞান। Segmented/বিভাগযুক্ত নিউরাল নেটওয়ার্ক ।
লেখক: রস Girshick, JeffDonahue, TrevorDarrell, জিতেন্দ্র মালিক।
এই কাগজটি 2014 সালে প্রকাশিত হয়েছিল এবং এর অনেক তাত্পর্য রয়েছে/lot of significance।
- Pascal VOC 2012-এর ডেটা সেট-এটি, লক্ষ্য সনাক্তকরণের যাচাইকরণ সূচক mAP বাড়ানো যেতে পারে ৫৩.৩%, যা আগের সেরা ফলাফলের তুলনায় সম্পূর্ণ ৩০% উন্নতি।
- এই কাগজটি প্রমাণ করে যে নিউরাল নেটওয়ার্কগুলি bottom up থেকে candidate regions এর প্রয়োগ করা যেতে পারে, যাতে target classification and target positioning নির্ধারণ করা যায়।
- এই কাগজটি একটি দৃষ্টিভঙ্গিও এনেছে, যখন আপনার অনেকগুলি লেবেলযুক্ত ডেটার অভাব হয়, তখন স্নায়ু নেটওয়ার্কগুলির স্থানান্তর শিখন সম্পাদন করা, অন্যান্য বৃহত ডেটা সেটগুলিতে প্রশিক্ষিত নিউরাল নেটওয়ার্কগুলি ব্যবহার করা এবং তারপরে একটি আরও ভাল এবং সম্ভাব্য পদ্ধতি হ'ল small scale specific data সেটগুলিতে ফাইন-টিউন করণ।
লক্ষ্য সনাক্তকরণ কি
বিভাগটি শনাক্ত করার জন্য একটি চিত্র দেওয়া হয়েছে, অবজেক্টের স্বীকৃতি ।
উদাহরণস্বরূপ, উপরের চিত্রটিকে বিড়াল হিসাবে অবজেক্ট বিভাগের পূর্বাভাস দেওয়া দরকার।
লক্ষ্য সনাক্তকরণ তাদের জায়গা খুঁজে পেতে বিভাগ চিহ্নিতকরণের, কিন্তু ছাড়াও।
স্পষ্টতই, লক্ষ্য সনাক্তকরণ বস্তুর স্বীকৃতির চেয়ে বেশি কঠিন।
R-CNN walks on the shoulders of predecessors কাঁধে হাঁটছে
বিগত দশ বছর বা তার বেশি সময়ে, traditional machine vision field ক্ষেত্রটি সাধারণত লক্ষ্য স্বীকৃতি সংক্রান্ত কাজগুলি মোকাবেলায় বৈশিষ্ট্য বর্ণনাকারী ব্যবহার করে। সর্বাধিক সাধারণ বৈশিষ্ট্য বর্ণনাকারী হ'ল SIFT and HOG। OpenCV হচ্ছে ready-made APIs যা সবাই operating করতে পারে এই implement related জন্য.
SIFT এবং HOG এর রাজত্বটি সম্প্রতি কনভ্যুশনাল নিউরাল নেটওয়ার্কগুলির দ্বারা কাঁপানো হয়েছে।
SIFT (Scale-invariant feature transform) and HOG (Histogram of Oriented Gradient).
(HOG oriented gradients/ওরিয়েন্টেড গ্রেডিয়েন্টের হিস্টোগ্রামের জন্য দাঁড়িয়েছে। যা প্রথম অর্ডার চিত্রের গ্রেডিয়েন্টের উপর ভিত্তি করে। চিত্রের গ্রেডিয়েন্টগুলি একটি ঘন পদ্ধতিতে ওভারল্যাপিং ওরিয়েন্টেশন বিনগুলিতে পুল করা হয়।
প্রথম অর্ডার গ্রেডিয়েন্টের উপর ভিত্তি করেকোর্স, এটি difference of gaussian (DoG) key point detector ব্যবহার করে প্রাপ্ত স্কেল ইনভেরেন্ট ফিচার পয়েন্টগুলির আশেপাশে মূল্যায়ন করা হয়। dense-SIFTটি নামে পরিচিত, একটি dense variant রয়েছে। হাত ইঞ্জিনিয়ারড এবং এভাবে নিজেই উপস্থাপনাটি শিখেনি, এটি হার্ড কোডেড
SIFT (Scale-invariant feature transform) and HOG (Histogram of Oriented Gradient).
(HOG oriented gradients/ওরিয়েন্টেড গ্রেডিয়েন্টের হিস্টোগ্রামের জন্য দাঁড়িয়েছে। যা প্রথম অর্ডার চিত্রের গ্রেডিয়েন্টের উপর ভিত্তি করে। চিত্রের গ্রেডিয়েন্টগুলি একটি ঘন পদ্ধতিতে ওভারল্যাপিং ওরিয়েন্টেশন বিনগুলিতে পুল করা হয়।
1 প্রথম অর্ডার চিত্রের গ্রেডিয়েন্টের ভিত্তিতে ওরিয়েন্টেশন বিনগুলিতে পোল করা।
2 ঘন (সমস্ত চিত্র জুড়ে মূল্যায়ন)
3 হ্যান্ড ইঞ্জিনিয়ারড, HOG বৈশিষ্ট্যগুলির জন্য কোনও লার্নিং অ্যালগরিদম নেই।
SIFT
scale invariant feature transform-র জন্য যা কেবলমাত্র HOG এর সমান, SIFT টি বিশেষত একটি 128 মাত্রিক ভেক্টর যা একটি 16 × 16 উইন্ডো প্যাচের summarizes/describes/সংক্ষিপ্তসার / বর্ণনা করে।এসআইএফটিটি 16 × 16 উইন্ডোটিকে 4×4 bins টি ভাগে ভাগ করে প্রাপ্ত হয়। প্রতিটি বিনের 8 টি ওরিয়েন্টেশন বিন বা চ্যানেল রয়েছে। সুতরাং এটি SIFT বর্ণনাকারীর মাত্রাটিকে সমান করে তোলে
4×4×8 = 128প্রথম অর্ডার গ্রেডিয়েন্টের উপর ভিত্তি করেকোর্স, এটি difference of gaussian (DoG) key point detector ব্যবহার করে প্রাপ্ত স্কেল ইনভেরেন্ট ফিচার পয়েন্টগুলির আশেপাশে মূল্যায়ন করা হয়। dense-SIFTটি নামে পরিচিত, একটি dense variant রয়েছে। হাত ইঞ্জিনিয়ারড এবং এভাবে নিজেই উপস্থাপনাটি শিখেনি, এটি হার্ড কোডেড
CNNCNN
convolutional neural network-র জন্য দাঁড়িয়েছে, এটি একটি hierarchical deep learning architecture। এটি repeated convolutional operations গুলির উপর ভিত্তি করে - যা প্রতিটি পর্যায়ে বারবার সংকেত ফিল্টার করে। ফিল্টারগুলি প্রশিক্ষণযোগ্য, অর্থাৎ, তারা শেখার সময় হাতে থাকা কাজের সাথে খাপ খাইয়ে নিতে শেখে।
CNNs are:
- Trainable feature detector যা এগুলিকে অত্যন্ত adaptive করে তোলে। এ কারণেই তারা বেশিরভাগ অ্যাপ্লিকেশন যেমন চিত্র স্বীকৃতি হিসাবে উচ্চ নির্ভুলতার স্তর অর্জন করতে পারে। এগুলি শেষ থেকে শেষ পর্যন্ত প্রশিক্ষিত হতে পারে।
- convolutions and pooling layersগুলির alternating layers গুলির সাথে প্রাথমিক visual cortex দ্বারা motivated মূলত তদারকি করা deep learning models গুলি।
- তারা একা training examples থেকে SIFT and HOG features গুলির মতো learn low-level features গুলি শিখতে পারে, that is amazing. এটি CNNs ব্যবহার করার ক্ষেত্রে feature engineering কে ন্যূনতম করতে পারে।
২০১২ সালে, Krizhevsky/ক্রিজেভস্কি এবং অন্যান্যরা ILSVRC target recognition challenge এ বিখ্যাত হয়েছিলেন, বছরের প্রথম স্থানটি অর্জন করেছিলেন, টপ ৫ ত্রুটি হারের সাথে ১৫%, এবং তাদের দলের প্রস্তাবিত নেটওয়ার্ক কাঠামোটি তাদের পরামর্শদাতার নামে নামকরণ করেছিল। AlexNet।
এটিতে 5 convolutional layers এবং 2 2 fully connected layers রয়েছে।
AlexNet উত্থান কারণে বিশ্বের মনোযোগ স্নায়ুর নেটওয়ার্ক ক্ষেত্রের ফিরে এসেছে। একটা সুযোগ হিসেবে, এই ধরনের VGG, GoogleNet, ResNet বিভিন্ন নেটওয়ার্ক, ইত্যাদি আবির্ভূত হয়েছে।
AlexNet দ্বারা অনুপ্রাণিত, লেখক PASCAL VOC বস্তুর শনাক্তকরণ করতে সাধারণের AlexNet ImageNet object recognition capabilities করার প্রচেষ্টা করে।
তবে সবকিছু শুরুর আগে দুটি প্রধান বিষয় বিবেচনা করা দরকার।
- targets গুলি locate করতে deep neural networks গুলি কীভাবে ব্যবহার করবেন?
- একটিsmall-scale data set টিতে একটি powerful network model কে কীভাবে প্রশিক্ষণ দেওয়া যায়?
কাগজের লেখক এই ধারণা দেয়।
target positioning-র জন্য candidate areas and CNNব্যবহার করা
Sliding windows করার ধারণাটি Drawing করলে, R-CNN অঞ্চলগুলি চিহ্নিত করার জন্য একটি scheme/পরিকল্পনা করা ব্যবহার করে।
বিশেষ করে:
- একটি ইনপুট চিত্র দেওয়া, 2000 প্রার্থী অঞ্চল থেকে স্বতন্ত্র প্রার্থী অঞ্চলগুলি বিভাগ থেকে নেওয়া হয়।
- প্রতিটি অঞ্চলের জন্য, CNN ব্যবহার করে একটি fixed-length feature vector বের করা হয়।
- তারপরে প্রতিটি অঞ্চলের জন্য লক্ষ্য শ্রেণিবিন্যাসের জন্য এসভিএম ব্যবহার করুন।
নীচের চিত্রটি কাগজ থেকেই।
লেবেলযুক্ত ডেটার অভাবের সমস্যা সমাধানের জন্য pre-training and fine-tuningব্যবহার করা
ইমেজনেটে প্রশিক্ষণ প্রাপ্ত মডেলটি ধরুন এবং তারপরে PASCAL VOC dataset fine-tune করুন।
কারণ ImageNet এর ইমেজ কয়েক মিলিয়ন পর্যন্ত হয়,সম্পূর্ণরূপে অগভীর বৈশিষ্ট্য শিখতে convolutional নিউরাল নেটওয়ার্ক ব্যবহার এবং তারপর ক্ষুদ্রায়তন ডেটা সেট উপর বড় মাপের প্রশিক্ষণ করছেন ভালো ফল অর্জন করতে পারেন।
এখন, আমরা যাকে ট্রাtransfer learning বলি একটি essential skill.।
R-CNN's road to target recognition
পূর্বে উল্লিখিত হিসাবে, আর-সিএনএন সিস্টেমটি 3 টি পর্যায়ে বিভক্ত, যা 3 টি মডিউল দ্বারা আর্কিটেকচারে প্রতিফলিত হয়।
- স্বতন্ত্র বিভাগ সহ প্রার্থী অঞ্চল উত্পাদন করে। এই প্রার্থী অঞ্চলগুলিতে আর-সিএনএন এর চূড়ান্ত অবস্থানের ফলাফল রয়েছে।
- নিউরাল নেটওয়ার্ক প্রতিটি candidate region-র জন্য neural network extracts fixed-length feature vectors আহরণ করে।
- SVM শ্রেণিবদ্ধের একটি series
Candidate area/প্রার্থী অঞ্চল
প্রার্থী অঞ্চল উত্পন্ন করার বিভিন্ন উপায় রয়েছে যেমন:
- selective searchনির্বাচনী অনুসন্ধান
- category-independen object proposalsবিভাগ-স্বতন্ত্র অবজেক্ট প্রস্তাব
- constrained parametric min-cuts (CPMC)সীমাবদ্ধ প্যারামেট্রিক মিনিট কাটস
- multi-scale combinatorial groupingবহু-স্কেল সমন্বিত গ্রুপিং
- Ciresan
আর-সিএনএন নির্বাচনী অনুসন্ধান অ্যালগরিদম ব্যবহার করে।
বৈশিষ্ট্য নিষ্কাশন/Feature extraction
R-CNN একটি 4096-dimensional feature vector বের করেছে code development জন্য Caffe উপর ভিত্তি করে Alexnet ব্যবহার করা।
নোট করুন Alextnet ইনপুট ছবির আকার 227x227 হয়।
Selective Search দ্বারা generated করা candidate areas গুলির আকার পৃথক। Alexnet-র সাথে সামঞ্জস্যপূর্ণ হওয়ার জন্য, R-CNN very violent/হিংসাত্মক method ব্যবহার করে, এটি candidate are- র size and shape ignores/উপেক্ষা করে 227 * 227 আকারে অভিন্ন transforms/রূপান্তরিত করে।
একটি বিশদ আছে। Regionsগুলি transforming করার সময়, এই অঞ্চলগুলি প্রথমে ফুলে উঠেছে, এবং বাক্সের চারদিকে p pixels যুক্ত করা হয়, অর্থাৎ একটি সীমানা artificially added করা হয়েছে, এখানে P = 16
Object detection during the test phaseপরীক্ষার পর্যায়ে অবজেক্ট সনাক্তকরণ
পরীক্ষার পর্যায়ে, আর-সিএনএন প্রতিটি চিত্রে প্রায় 2000 প্রার্থী অঞ্চলগুলি বের করে।
তারপরে, প্রতিটি candidate region কে transformation size করতে হবে, read feature গুলিকে neural network পাঠানো হয়েছে, এবং তারপরে, বিভাগটি সনাক্ত করতে এবং একটি score/স্কোর তৈরি করতে SVM ব্যবহার করে।
2,000 candidate regions আছে, তাই অনেক ওভারল্যাপ হবে।
প্রতিটি শ্রেণীর জন্য,IoU index গণনা করুন, non-maximum suppression গ্রহণ করুন, highest score সহ অঞ্চলটির উপর ভিত্তি করে, overlap করে এমন অঞ্চলগুলি সরিয়ে ফেলুন।
Runtime analysisরানটাইম বিশ্লেষণ
দুটো কারণ target recognition efficient করে তুলতে পারে।
- সিএনএন এর প্যারামিটারগুলি সমস্ত বিভাগ দ্বারা ভাগ করা হয়।
- R-CNN আরও কম বৈশিষ্ট্যযুক্ত ভেক্টর তৈরি করে।UVA ব্যবহৃত spatial pyramid technology সঙ্গে তুলনা ক্রে।এই কাগজ 360k feature dimensions জেনারেট করে, যখন, আর-সিএনএন 4K এর বেশি রয়েছে।
অর্থাৎ, এটাই,অপারেশন চলাকালীন, প্যারামিটারগুলি কম হয়ে যায়, তাই এটি প্রচলিতগুলির চেয়ে বেশি দক্ষ।
Feature extraction/বৈশিষ্ট্য নিষ্কাশন সময় Reflected যদি GPU ব্যবহার করা হয়, 13s / sheet, CPU- র 53s / sheet।
আর-সিএনএন 100k বিভাগগুলি প্রক্রিয়াকরণে সক্ষম এবং এটি একটি বহু-কোর সিপিইউতে কেবল 10 সেকেন্ডের বেশি সময় নেয়।
UVA সাথে তুলনা করা,যদি আপনি 100 কে ভবিষ্যদ্বাণীগুলি প্রক্রিয়া করেন,আপনি মেমরি স্পেস 134GB প্রয়োজন,আর-সিএনএন শুধুমাত্র 1.5GB প্রয়োজন হয়।
trainingপ্রশিক্ষণ
পূর্বে উল্লিখিত হিসাবে, আর-সিএনএন স্থানান্তর শেখার গ্রহণ করে।
আইএলএসভিআরসি ২০১২-তে মডেল এবং ওজনগুলি বের করুন এবং ভিওসি-তে সূক্ষ্ম সুর করুন।
এটি লক্ষ করা উচিত যে এখানে ইমেজনেটে প্রশিক্ষণ দেওয়া হচ্ছে হ'ল মডেলটির অবজেক্টের ধরণের স্বীকৃতি দেওয়ার ক্ষমতা, ববক্সের অবস্থান অনুমান করার ক্ষমতা নয়।
ইমেজনেটের প্রশিক্ষণের জন্য 1000 টি বিভাগের পূর্বাভাস দেওয়া দরকার, এবং যখন আর-সিএনএন ভিওসি-তে স্থানান্তর শিখন সম্পাদন করে, তখন নিউরাল নেটওয়ার্কটি কেবলমাত্র 21 টি বিভাগ চিহ্নিত করতে হবে। এটি 20 টি বিভাগ যা ভিওসি প্লাস ব্যাকগ্রাউন্ড বিভাগ দ্বারা নির্ধারিত হয়েছে।
আর-সিএনএন প্রার্থী অঞ্চলের সাথে গ্রাউন্ডট্রুতে বক্স লেবেলের সাথে তুলনা করে If
প্রশিক্ষণের কৌশলটি হ'ল: এসজিডি প্রশিক্ষণ ব্যবহার করে, প্রাথমিক শিক্ষার হার 0.001 এবং মিনি-ব্যাচের আকার 128।
সম্পর্কিত স্বীকৃতি সম্পর্কিত
একটি বাইনারি শ্রেণিবদ্ধকারী সাধারণত চিকিত্সা করা হয়, এবং এর ফলাফল ইতিবাচক এবং নেতিবাচক মাত্র 2।
উদাহরণস্বরূপ, আপনার যদি একটি গাড়ী শ্রেণিবদ্ধ রয়েছে যা সহজেই নিশ্চিত করতে পারে যে কোনও বাক্সে একটি গাড়ী রয়েছে, তবে এটি অবশ্যই ইতিবাচক হবে।
এটি স্পষ্টভাবে নিশ্চিতও করা যায় যে কোনও গাড়ী যদি কোনও পটভূমির বাক্সে অন্তর্ভুক্ত না করা হয় তবে তা নেতিবাচক।
যাইহোক, এটি নিশ্চিত করা আরও কঠিন যে কোনও বাক্সের একটি অংশ যদি গাড়ীর সাথে ওভারল্যাপ করে তবে এই বাক্সটিকে কীভাবে লেবেল করবেন?
আর-সিএনএন আইওইউর প্রান্তিক ব্যবহার করে .এই প্রান্তিকতা ০.০. যদি কোনও অঞ্চলের এবং গ্রাউন্ড টুরিথের আইওইউ মান সেট থ্রেশহোল্ডের চেয়ে কম হয়, তবে এটি নেগেটিভ হিসাবে গণ্য হতে পারে।
আইওইউয়ের প্রান্তিকতা লেখকের র্যান্ডম মান নয়, তবে of 0,0.1,0.2,0.3,0.4,0.5 from থেকে মানগুলির সংমিশ্রণ}
তদুপরি, এই মানটি অত্যন্ত গুরুত্বপূর্ণ If থ্রোসোল্ডের মানটি যদি 0.5 হয় তবে এমএপি সূচকটি সরাসরি 5 পয়েন্টে নেমে যায় the মানটি 0 হয়, এমএপি 4 পয়েন্ট হ্রাস পাবে।
বৈশিষ্ট্য নিষ্কাশন সফল হয়ে গেলে, আর-সিএনএন প্রতিটি অঞ্চলের বিভাগ চিহ্নিত করতে এসভিএম ব্যবহার করবে, তবে এটি অপ্টিমাইজ করা দরকার।
প্রশিক্ষণের ডেটা কম্পিউটারের স্মৃতিতে একবারে পূরণের পক্ষে অনেক বড়, আর-সিএনএন লেখক হার্ড নেগেটিভ মাইনিং নামে একটি পদ্ধতি গ্রহণ করেছিলেন।
পাস্কাল-ভোক 2010-10-এ আর-সিএনএন সম্পাদনা
আর সিএনএন পাস্কাল ভিওসি ২০১২ এ চূড়ান্ত সূক্ষ্ম সুর সম্পাদন করে এবং ভিওসি ২০১২ এর প্রশিক্ষণ সংস্থায় এসভিএমকেও অনুকূলিত করে।
তারপরে, এটি 4 টি শক্তিশালী বিরোধীদের সাথেও তুলনা করা হয়েছিল, অর্থাৎ 4 টি পৃথক লক্ষ্য সনাক্তকরণ অ্যালগোরিদম।
এটি লক্ষণীয় যে উপরের টেবিলের ইউভিএ সনাক্তকরণ সিস্টেমটি একই প্রার্থী অঞ্চল অ্যালগরিদমকেও গ্রহণ করে, তবে আর-সিএনএন এর চেয়ে ভাল সম্পাদন করে।
ভিজ্যুয়ালাইজেশন, ফ্রেমওয়ার্ক হ্রাস এবং ত্রুটি সনাক্তকরণ
আমরা সকলেই জানি যে কনভোলশনাল নিউরাল নেটওয়ার্কগুলিতে, প্রথম স্তরটি সরাসরি প্রদর্শন এবং খালি চোখে দৃশ্যমান জন্য ব্যবহার করা যেতে পারে Usually সাধারণত তারা অবজেক্টগুলির প্রান্ত এবং বিশিষ্ট বর্ণের তথ্যগুলি ক্যাপচার করতে ব্যবহৃত হয়। এই সময়ে ভিজুয়ালাইজ করা একটি চ্যালেঞ্জ।
জিলার এবং ফার্গাস ডিকনভোলিউশনের উপর ভিত্তি করে একটি ভিজ্যুয়ালাইজেশন অধ্যয়নের প্রস্তাব করেছিলেন, তবে আর-সিএনএন-র লেখকরা সরাসরি পরামিতি ছাড়াই একটি পদ্ধতি সরবরাহ করেছিলেন, যা সহজ এবং সোজা।
ধারণাটি হ'ল কোনও বৈশিষ্ট্য বাছাই করা, এটিকে অবজেক্ট শ্রেণীবদ্ধকারী হিসাবে সরাসরি বিবেচনা করা এবং তারপরে তারা বিভিন্ন প্রার্থী অঞ্চলে প্রক্রিয়া করার সময় অ্যাক্টিভেশন মানটি গণনা করে value প্রথম কয়েকটি নিন এবং তারপরে এই প্রার্থী অঞ্চলগুলি প্রদর্শন করুন display স্বাভাবিকভাবেই, আপনি এই বৈশিষ্ট্যটি কী তা স্পষ্টভাবে বুঝতে পারবেন।
আর-সিএনএন এর লেখক পুল 5 কে ভিজ্যুয়ালাইজেশন অবজেক্ট হিসাবে গ্রহণ করে এবং এর বৈশিষ্ট্যটির মানচিত্রটি 6x6x255 It এটি বোঝা যায় যে এখানে 256 টি ছোট স্কোয়ার রয়েছে এবং প্রতিটি বর্গ একটি বৈশিষ্ট্যের সাথে মিলে যায়।
নীচের চার্টটি এই ভিজ্যুয়ালাইজেশনের প্রভাব দেখায় 25 এখানে 256 টির মধ্যে 6 টি বৈশিষ্ট্য প্রদর্শন করা হয়েছে এবং প্রতিটি বৈশিষ্ট্য সর্বাধিক অ্যাক্টিভেশন মান সহ 16 টি অঞ্চল নিয়েছে।
উপরের চিত্রটি খুব স্পষ্ট হওয়া উচিত type একই ধরণের বৈশিষ্ট্যের জন্য, সক্রিয়করণগুলি খুব বেশি আলাদা নয়, যা বস্তুগুলি সঠিকভাবে সনাক্ত করার জন্য কনভোলশনাল নিউরাল নেটওয়ার্কের ক্ষমতাদির উদ্ভাস।
প্রবাহিত কাঠামো
অ্যালেক্সনেটের 7 স্তর রয়েছে, তাই মূল সূচকগুলি কী? কোন স্তরগুলি alচ্ছিক?
পুল 5 পূর্ববর্তী বিভাগে আলোচনা করা হয়েছে, তারপরে fc6 এবং f7 গবেষণার বিষয়বস্তুতে পরিণত হয়।
fc6 এবং পুল 5 একটি সম্পূর্ণ সংযোগ গঠন করে the বৈশিষ্ট্যটি গণনা করার জন্য, এটি 4096x9216 এর ওজন ম্যাট্রিক্স দ্বারা গুণিত হয় এবং তারপরে একটি পক্ষপাতিত্বের সেটে যোগ করা হয়, সুতরাং এতে 37 মিলিয়নেরও বেশি পরামিতি রয়েছে।
fc7 সর্বশেষ স্তর, এর ওজন ম্যাট্রিক্স 4096x409, এবং এর পরামিতিগুলিতে 16.78 মিলিয়নেরও বেশি পরামিতি রয়েছে।
যাইহোক, লেখক পাস্কাল এবং সরাসরি পরীক্ষাগুলিতে সূক্ষ্ম সুরে প্রক্রিয়াকরণ না করার পরে, এটি পাওয়া যায় যে fc7 fc6 এর মতো তাত্পর্যপূর্ণ নয়, এবং এটি অপসারণের পরেও, এমএপি ফলাফল সূচকগুলিতে এর কোনও প্রভাব নেই।
Fc7 অপসারণ মানে প্রায় 18 মিলিয়ন প্যারামিটার হ্রাস করা যেতে পারে।
আরও মজাদার বিষয় হ'ল একই সাথে fc6 এবং fc7 অপসারণ করলে খুব বেশি ক্ষতি হয় না এবং ফলাফলটি আরও ভাল।
অতএব, স্নায়ুবহুল নেটওয়ার্কগুলির মধ্যে সবচেয়ে আশ্চর্যজনক শক্তি সম্পূর্ণরূপে সংযুক্ত স্তর নয়, কনভলিউশনাল স্তর থেকে আসে।
উপরেরটি সূক্ষ্ম সুর ছাড়াই কেস, তাই ফাইন-টিউন নিয়ে পরিস্থিতি কী?
ফলাফলগুলি প্রমাণ করে যে সূক্ষ্ম সুরের পরে fc6 এবং fc7 এর প্রভাব সুস্পষ্ট।
সুতরাং উপসংহারটি হ'ল পুল 5 ইমেজনেট প্রশিক্ষণ সেট থেকে অবজেক্টের সাধারণীকরণের ক্ষমতাটি শিখেছে এবং নির্দিষ্ট ডোমেনের সূক্ষ্ম সুরের মাধ্যমে দক্ষতার উন্নতি হবে।
উদাহরণস্বরূপ, নিউরাল নেটওয়ার্ক ইমেজনেট ডেটাসেটে 100 টি বিড়ালের বৈশিষ্ট্য শিখেছে, তবে আমার নিজস্ব ডেটাসেটটিতে কেবল দুটি বিড়াল রয়েছে। সূক্ষ্ম সুরের প্রশিক্ষণের পরে, এই নিউরাল নেটওয়ার্কটি আরও দুটি সঠিকভাবে এই দুটি বিড়াল সনাক্ত করতে পারে।
আর-সিএনএন তার বৈশিষ্ট্যগুলি অন্যান্য বৈশিষ্ট্য পদ্ধতির সাথেও তুলনা করে The লেখক দুটি ডিপিএম-ভিত্তিক পদ্ধতি, ডিপিএম এসটি এবং ডিপিএম এইচএসসি চয়ন করেন The ফলাফলগুলি প্রমাণ করে যে আর-সিএনএন তাদের চেয়ে ভাল।
Object detection error analysis/অবজেক্ট সনাক্তকরণ ত্রুটি বিশ্লেষণ
R-CNN এর লেখক ভুল মডেলটি visually expose-র জন্য Hoiem-র প্রস্তাবিত object detection and analysis tool টি ব্যবহার করেন । লেখক একটি targeted manner/উপায়ে fine-tune সম্পাদন করতে এই tool টি ব্যবহার করেন।
bbox returns
বক্সের value আসলে object box-র অবস্থান। এটি Predicting/পূর্বাভাস দেওয়া classification problem নয়, একটি regression problem।
DPM দ্বারা অনুপ্রাণিত, হয়ে লেখক একটি লিনিয়ার রিগ্রেশন মডেলকে প্রশিক্ষণ দিয়েছিলেন যা candidate area এর pool5 data-র জন্য একটি নতুন বক্স অবস্থানের predict দিতে পারে। Specific details, লেখক supplementary materials রাখে ।
Semantic segmentation
semantic segmentation/শব্দার্থক বিভাজন কি?

Region classification প্রযুক্তিটি semantic segmentation-র standard method পদ্ধতি, সুতরাং R-CNN semantic segmentation ও করতে পারে এবং লেখক এটি O2P এর সাথে তুলনা করে।
R-CNN এর semantic segmentation তিনটি পর্যায়ে বিভক্ত।
- candidate regions গুলি তৈরি করতে CPMC ব্যবহার করুন এবং তারপরে এই অঞ্চলগুলিকে পুনরায় আকার দিন 227x227 এ এগুলি নিউরাল নেটওয়ার্কে send করুন This is the full stage রয়েছে. অঞ্চলে backgrounds and prospects ব্যাকগ্রাউন্ড এবং সম্ভাবনা রয়েছে।
- এই পর্যায়ে, কেবলমাত্র প্রার্থীর অঞ্চলের অগ্রভাগ প্রক্রিয়াজাত হয় background ইনপুট গড় মান দ্বারা প্রতিস্থাপিত হয়, এবং তারপরে পটভূমি 0 হয় This এই পর্যায়টিকে বলা হয়।
- Full + fg stage, সাধারণ সেলাইসাধারণ সেলাই এরbackground and foreground।
পর্যালোচনা
- R-CNN AlexNet ব্যবহার করে
- R-CNN generate Region Proposal করতে Selective Search technology ব্যবহার করে।
- R-CNN ImageNet pre-trained হয়, তারপরে mature weight parameters ব্যবহার করে PASCAL VOC dataset fine-tuned হয়
- R-CNN featuresগুলি extract/নিষ্কাশন করতে CNN ব্যবহার করে এবং তারপরে class prediction-র জন্য একটি সিরিজ SVMs ব্যবহার করে।
- R-CNN-এর bbox position regression DPMর অনুপ্রেরণার উপর ভিত্তি করে তৈরি করা হয়েছে এবং নিজে থেকেই লিনিয়ার রিগ্রেশন মডেলকে প্রশিক্ষণ দিয়েছেন।
- R-CNN এর Semantic segmentation অঞ্চলগুলি তৈরি করতে CPMC ব্যবহার করে
আর-সিএনএন নমনীয়ভাবে বিদ্যমান উন্নত সরঞ্জাম এবং প্রযুক্তিগুলি ব্যবহার করেছিল, সেগুলি সম্পূর্ণরূপে শোষিত করে এবং তার নিজস্ব যুক্তি অনুসারে রূপান্তরিত করে এবং অবশেষে দুর্দান্ত অগ্রগতি অর্জন করে।
2018 এর মধ্যে আর-সিএনএন আর সর্বাধিক উন্নত অবজেক্ট সনাক্তকরণ মডেল বা সর্বাধিক উন্নত সিমেটিক সেগমেন্টেশন মডেল নয়, তবে এই কাগজের সর্বাধিক উল্লেখযোগ্য তাৎপর্য হ'ল সংস্থার অভাবে সমস্যা সমাধানের জন্য বিদ্যমান উন্নত প্রযুক্তিগুলিকে কীভাবে সংহত করা যায় তা লেখককে দেখানো নিজস্ব সমস্যা মানে।
আর-সিএনএন ছাড়াও, কয়েকটি দুর্দান্ত লক্ষ্য সনাক্তকরণ অ্যালগরিদম রয়েছে I আমি ব্যক্তিগতভাবে ইওলোকে ভালবাসি আগ্রহী শিক্ষার্থীরা এই নিবন্ধটি পরীক্ষা করে দেখতে পারেন।
0 comments:
Post a Comment