An RNN overview
Earlier we described the BP algorithm, CNN algorithm, so why are there RNNs? What is RNN, and what are the differences? What are the main application areas of RNN? These are the issues to be discussed.
1) BP algorithm, after CNN, why is there RNN?
If you think about the BP algorithm, CNN (Convolutional Neural Network), we will find that their output only considers the influence of the previous input and does not consider the influence of other moments of input, such as simple cats, dogs, handwritten numbers and other single objects. Recognition has a good effect. However, for some time-related issues, such as the prediction of the next moment of the video, the prediction of the context of the document, etc., the performance of these algorithms is not satisfactory. Therefore, RNN should be applied. And was born.
2) What is RNN?
RNN is a special neural network structure, which is proposed based on the viewpoint that " human cognition is based on past experience and memory ". It is different from DNN and CNN in that it not only considers the input of the previous moment, And it gives the network a 'memory' function of the previous content .
The reason why RNN is called recurrent neural network is that the current output of a sequence is also related to the previous output. The specific manifestation is that the network memorizes the previous information and applies it to the calculation of the current output, that is, the nodes between the hidden layers are no longer unconnected but connected, and the input of the hidden layer includes not only the output of the input layer It also includes the output of the hidden layer from the previous moment.
3) What are the main application areas of RNN ?
There are many application areas of RNN, it can be said that as long as the problem of chronological order is considered, RNN can be used to solve it. Here are some common application areas:
① Natural Language Processing (NLP) : There are video processing , text generation , language model , image processing
② Machine translation , machine writing novels
③ Speech recognition
④ Image description generation
⑤ Text similarity calculation
⑥ New application areas such as music recommendation , Netease koala product recommendation , Youtube video recommendation, etc.
Two RNN (Recurrent Neural Network)
1) RNN model structure
Earlier we said that RNN has the function of "memory" of time, so how does it realize the so-called "memory"?
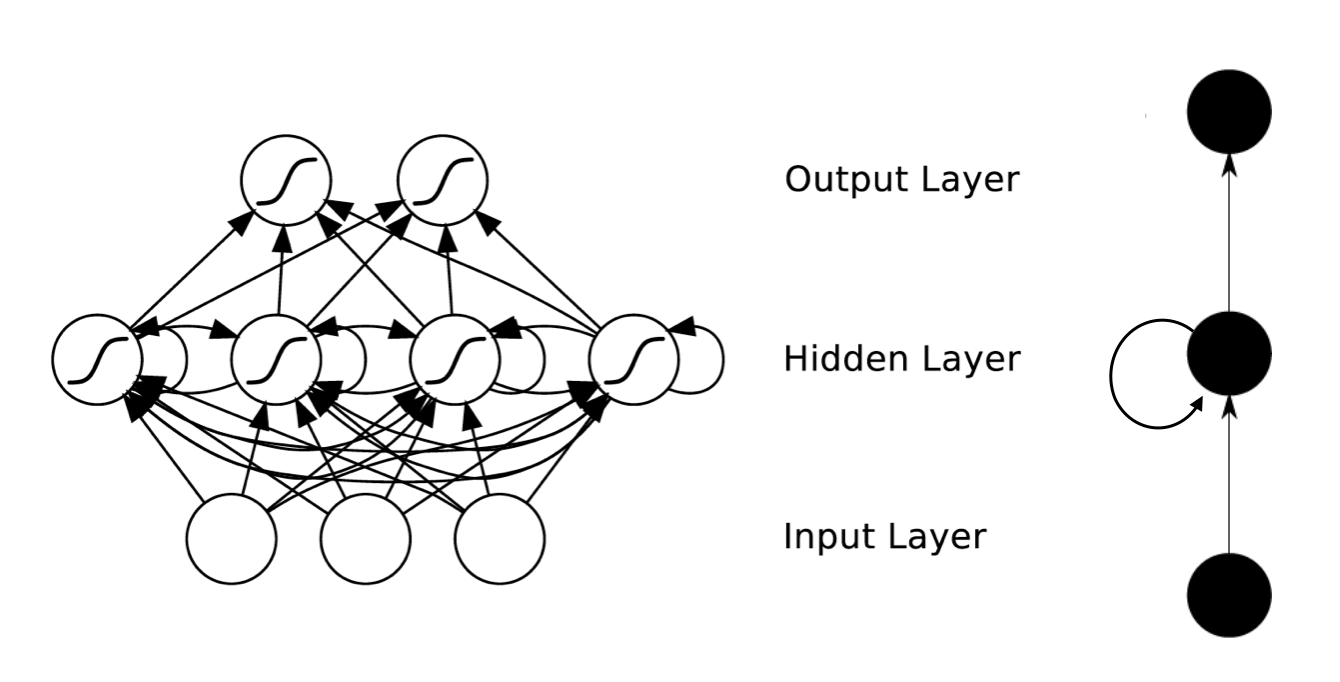
Figure 1 RNN structure diagram
As shown in Figure 1, we can see that the RNN hierarchy is simpler than CNN.It mainly consists of an input layer , a Hidden Layer , and an output layer .
And you will find that there is an arrow in the Hidden Layer indicating the cyclic update of the data.This is the method to implement the time memory function.
If you still don't understand what RNN means here, then continue reading!
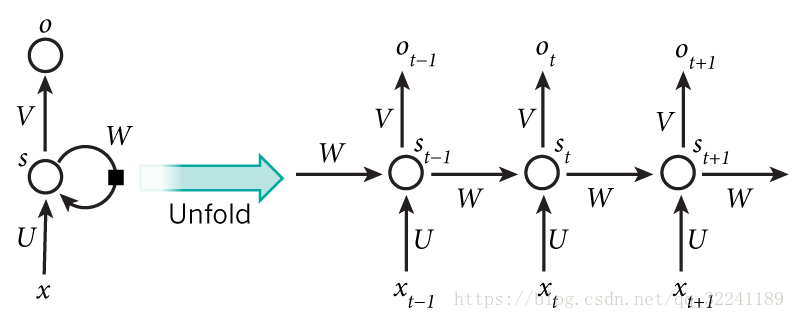
Figure 2 Hierarchy of Hidden Layer
Figure 2 shows the hierarchical expansion of the Hidden Layer. T-1, t, t + 1 represent the time series. X represents the input sample. St represents the memory of the sample at time t, St = f (W * St -1 + U * Xt) . W is the weight of the input, U is the weight of the input sample at the moment, and V is the weight of the output sample.
At t = 1, the general initialization input S0 = 0, randomly initializes W, U, V, and calculates the following formula:
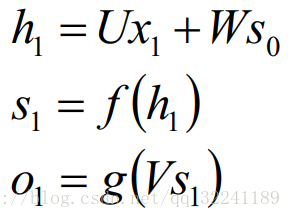
Among them, f and g are activation functions. Among them, f can be tanh, relu, sigmoid and other activation functions, g is usually softmax or other.
Time advances, and the state s1 at this time, as the memory state at time 1, will participate in the prediction activity at the next time, that is:
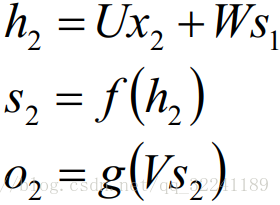
By analogy, you can get the final output value:
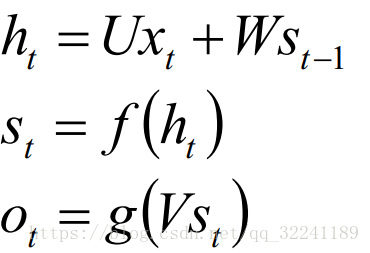
Note : 1. Here W, U, V are equal at each moment ( weight sharing ).
2. The hidden state can be understood as: S = f (existing input + past memory summary )
2) Back propagation of RNN
Earlier we introduced the forward propagation method of the RNN, so how are the weight parameters W, U, and V of the RNN updated?
Each output will have a value Ot error value Et, the total error may be expressed as: .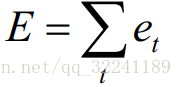
The loss function can use either the cross-entropy loss function or the squared error loss function .
Because the output of each step does not only depend on the network of the current step, but also the state of the previous steps, then this modified BP algorithm is called Backpropagation Through Time ( BPTT ), which is the reverse transfer of the error value at the output end. The gradient descent method is updated. (If you are not familiar with BP, you can refer here )
That is, the gradient of the required parameter:
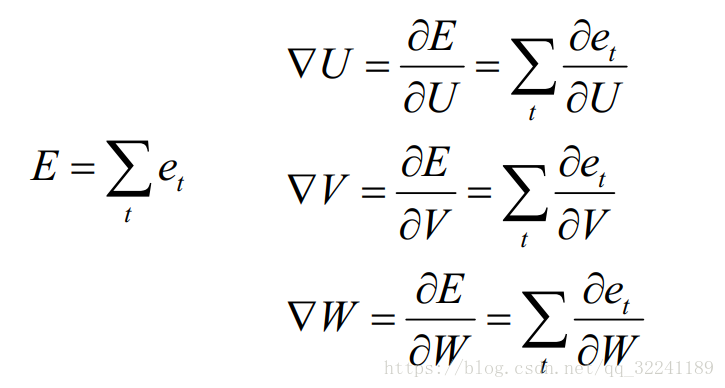
First we solve the update method of W. From the previous update of W, it can be seen that it is the sum of the partial derivatives of the deviations at each moment.
Here we take time t = 3 as an example.According to the chain derivation rule, we can get the partial derivative at time t = 3 as:
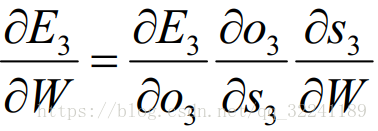
At this time, according to the formula 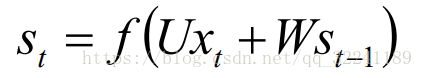 , we will find that, in addition to W, S3 is also related to S2 at the previous moment.
, we will find that, in addition to W, S3 is also related to S2 at the previous moment.
For S3, expand directly to get the following formula:
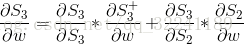
For S2, expand directly to get the following formula:
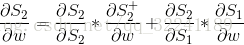
For S1, expand directly to get the following formula:
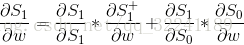
The above three formulas are combined to get:
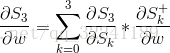
This gives the formula:
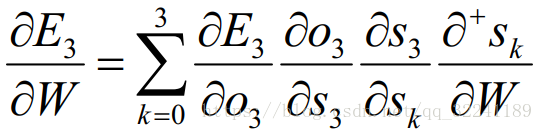
What is to be explained here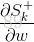 is that it means that S3 directly differentiates W without considering the effect of S2 (that is, for example, y = f (x) * g (x) is the same as the derivative of x)
is that it means that S3 directly differentiates W without considering the effect of S2 (that is, for example, y = f (x) * g (x) is the same as the derivative of x)
is that it means that S3 directly differentiates W without considering the effect of S2 (that is, for example, y = f (x) * g (x) is the same as the derivative of x)
The second is the update method for U. Since the parameter U and W are similar, they will not be described here, and the specific formula obtained in the end is as follows:
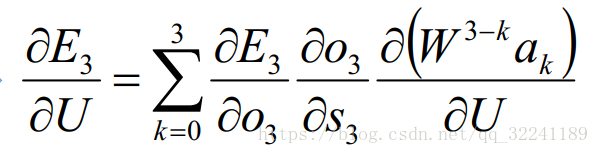
Finally, give the updated formula of V (V is only related to output O):
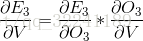
Some improved algorithms for triple RNN
In front of us the RNN algorithm that effect deal with the problem of time series is very good, but there are still some problems, which is more serious is prone gradient disappear or gradient explosion problem (of BP algorithm and time-dependent result ) Note: The disappearance of the gradient here is not the same as that of BP. Here, it mainly refers to the phenomenon that the memory value is small due to the long time.
Therefore, a series of improved algorithms have emerged.Here are two main algorithms: LSTM and GRU .
LSTM and GRU mainly deal with the problem of gradient disappearance or gradient explosion:
For the disappearance of gradients : Because they all have a special way to store "memory", the "memory" with a relatively large previous gradient will not be erased immediately like a simple RNN, so the problem of gradient disappearance can be overcome to a certain extent.
For gradient explosion : The problem used to overcome gradient explosion is gradient clipping , that is, when your calculated gradient exceeds the threshold c or less than the threshold -c, set the gradient at this time to c or -c.
1) LSTM algorithm (Long Short Term Memory, long short-term memory network) --- the most important time series algorithm currently used
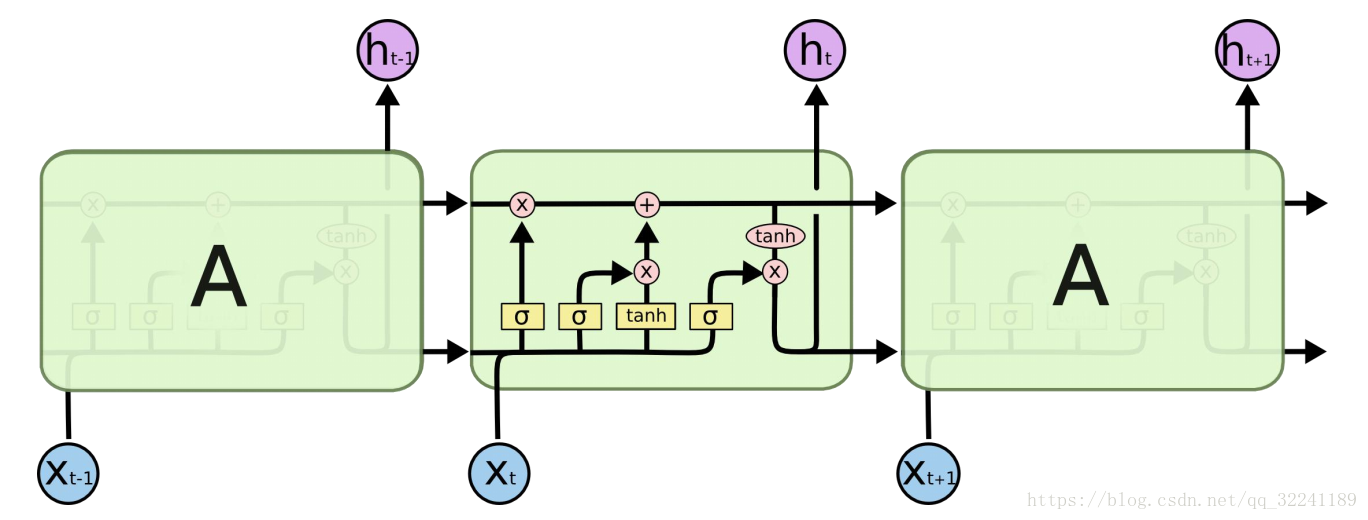 Figure 3 LSTM algorithm structure
Figure 3 LSTM algorithm structure
Figure 3 shows the structure of the LSTM algorithm.
Different from RNN: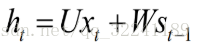 RNN is a simple linear summation process. LSTM can remove or add information about " cell state " through the " gate " structure , which realizes the retention of important content and the non-important content. Removal. A probability value between 0 and 1 is output through the Sigmoid layer, describing how much each part can pass, 0 means "do not allow task variables to pass", 1 means "run all variables to pass".
RNN is a simple linear summation process. LSTM can remove or add information about " cell state " through the " gate " structure , which realizes the retention of important content and the non-important content. Removal. A probability value between 0 and 1 is output through the Sigmoid layer, describing how much each part can pass, 0 means "do not allow task variables to pass", 1 means "run all variables to pass".
RNN is a simple linear summation process. LSTM can remove or add information about " cell state " through the " gate " structure , which realizes the retention of important content and the non-important content. Removal. A probability value between 0 and 1 is output through the Sigmoid layer, describing how much each part can pass, 0 means "do not allow task variables to pass", 1 means "run all variables to pass".
The gate for forgetting is called " forgetting gate ", the one for adding information is called " information adding gate ", and finally the " output gate " for output . It will not be introduced here.
In addition, there are some variants of the LSTM algorithm.
As shown in Figure 4, it adds a " peephole connections " layer so that the gate layer also accepts input from the cell state.
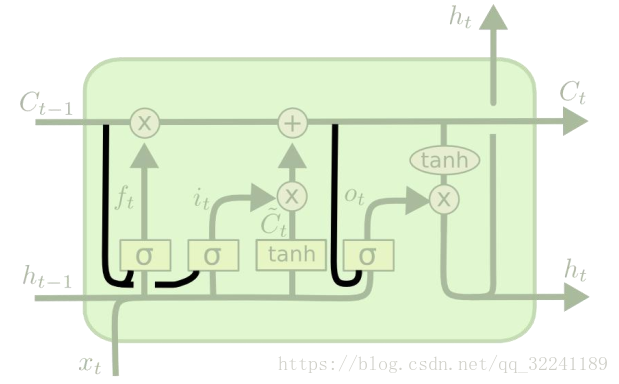
Figure 4 A variant of the LSTM algorithm
Figure 5 shows another variant algorithm of LSTM. It is through coupling forget gate and update input gate (first and second gate); that is, no longer consider what to forget and what information to add separately, and Think together.
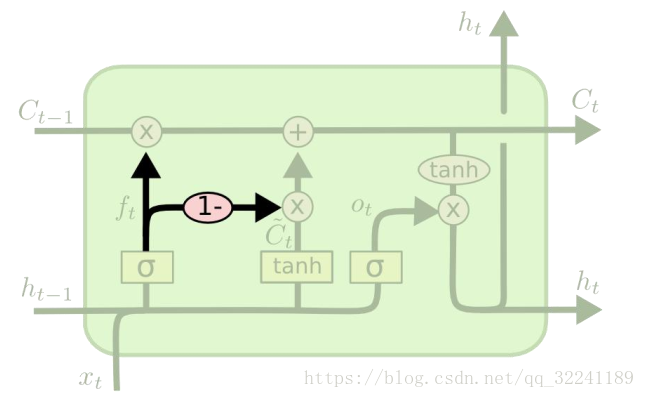
Figure 5 A variant of the LSTM algorithm
2) GRU algorithm
GRU is an improved LSTM algorithm proposed in 2014. It merges forgetting gates and input gates into a single update gate, and combines data unit states and hidden states, making the model structure simpler than LSTM.
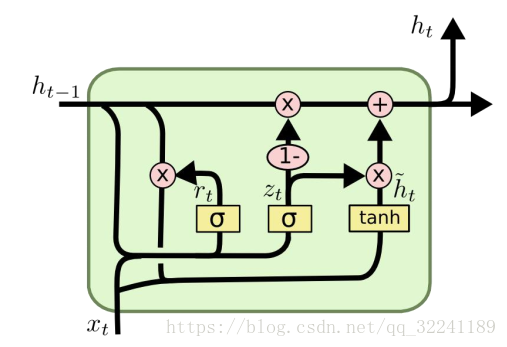
Each part satisfies the relationship as follows:
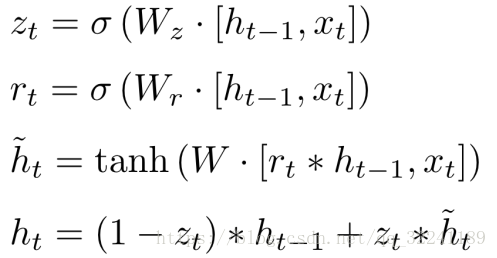
Four basic operations and summary based on Tensorflow
The basic operation using tensorflow is as follows:
# _*_coding:utf-8_*_
import tensorflow as tf
import numpy as np
'''
TensorFlow中的RNN的API主要包括以下两个路径:
1) tf.nn.rnn_cell(主要定义RNN的几种常见的cell)
2) tf.nn(RNN中的辅助操作)
'''
# 一 RNN中的cell
# 基类(最顶级的父类): tf.nn.rnn_cell.RNNCell()
# 最基础的RNN的实现: tf.nn.rnn_cell.BasicRNNCell()
# 简单的LSTM cell实现: tf.nn.rnn_cell.BasicLSTMCell()
# 最常用的LSTM实现: tf.nn.rnn_cell.LSTMCell()
# RGU cell实现: tf.nn.rnn_cell.GRUCell()
# 多层RNN结构网络的实现: tf.nn.rnn_cell.MultiRNNCell()
# 创建cell
# cell = tf.nn.rnn_cell.BasicRNNCell(num_units=128)
# print(cell.state_size)
# print(cell.output_size)
# shape=[4, 64]表示每次输入4个样本, 每个样本有64个特征
# inputs = tf.placeholder(dtype=tf.float32, shape=[4, 64])
# 给定RNN的初始状态
# s0 = cell.zero_state(4, tf.float32)
# print(s0.get_shape())
# 对于t=1时刻传入输入和state0,获取结果值
# output, s1 = cell.call(inputs, s0)
# print(output.get_shape())
# print(s1.get_shape())
# 定义LSTM cell
lstm_cell = tf.nn.rnn_cell.LSTMCell(num_units=128)
# shape=[4, 64]表示每次输入4个样本, 每个样本有64个特征
inputs = tf.placeholder(tf.float32, shape=[4, 48])
# 给定初始状态
s0 = lstm_cell.zero_state(4, tf.float32)
# 对于t=1时刻传入输入和state0,获取结果值
output, s1 = lstm_cell.call(inputs, s0)
print(output.get_shape())
print(s1.h.get_shape())
print(s1.c.get_shape())
Of course, you may find that using cell.call () can only call one at a time to get a state. If there are multiple states that need to be called multiple times, it is more troublesome. So how do we solve it? You can refer to the RNN-based handwriting Example recognition solutions for number recognition and word prediction .
This article mainly introduces a time series RNN neural network and the variant algorithms LSTM and GRU derived from it.It also introduces the usage scenarios of the RNN algorithm.
Of course, due to space limitations, two-way RNNs and multi-layer RNNs are not introduced here. In addition, the LSTM parameter update algorithm is not introduced here, and it will be added later!
Finally, if you find any problems, welcome to discuss together and make progress together!
একটি আরএনএন ওভারভিউ
এর আগে আমরা বিপি অ্যালগরিদম, সিএনএন অ্যালগরিদম বর্ণনা করেছি, সুতরাং আরএনএন কেন আছে? আরএনএন কী, এবং পার্থক্যগুলি কী? আরএনএন এর মূল প্রয়োগ ক্ষেত্রগুলি কী? এই বিষয়গুলি নিয়েই আলোচনা করা উচিত।
1) বিপি অ্যালগরিদম, সিএনএন এর পরে আরএনএন কেন?
আপনি যদি বিপি অ্যালগরিদম, সিএনএন (কনভ্যোলিউশনাল নিউরাল নেটওয়ার্ক) সম্পর্কে চিন্তা করেন তবে আমরা দেখতে পাব যে তাদের আউটপুট কেবল পূর্ববর্তী ইনপুটটির প্রভাব বিবেচনা করে এবং অন্যান্য মুহুর্তের ইনপুটগুলির প্রভাব যেমন সাধারণ বিড়াল, কুকুর, হাতে লেখা সংখ্যা এবং অন্যান্য একক বস্তু বিবেচনা করে না। স্বীকৃতিটির একটি ভাল প্রভাব রয়েছে However যাইহোক, কিছু সময়ের সাথে সম্পর্কিত সমস্যার জন্য যেমন ভিডিওর পরবর্তী মুহুর্তের পূর্বাভাস, নথির প্রসঙ্গে ভবিষ্যদ্বাণী ইত্যাদি for এই অ্যালগরিদমের কার্যকারিতা সন্তোষজনক নয় Therefore তাই আরএনএন প্রয়োগ করা উচিত। এবং জন্মগ্রহণ করেছিলেন।
2) আরএনএন কী?
আরএনএন একটি বিশেষ নিউরাল নেটওয়ার্ক কাঠামো, যা " মানুষের জ্ঞান অতীত অভিজ্ঞতা এবং স্মৃতির উপর ভিত্তি করে " এমন দৃষ্টিভঙ্গির ভিত্তিতে প্রস্তাবিত। এটি ডিএনএন এবং সিএনএন থেকে পৃথক যে এটি কেবল আগের মুহুর্তের ইনপুটকেই বিবেচনা করে না, এবং এটি নেটওয়ার্কটিকে পূর্ববর্তী সামগ্রীর একটি 'মেমরি' ফাংশন দেয় ।
আরএনএনকে পুনরাবৃত্ত নিউরাল নেটওয়ার্ক বলা হওয়ার কারণটি হ'ল একটি ক্রমের বর্তমান আউটপুটও পূর্ববর্তী আউটপুটটির সাথে সম্পর্কিত to সুনির্দিষ্ট প্রকাশটি হ'ল নেটওয়ার্কটি পূর্ববর্তী তথ্যগুলি মুখস্থ করে এবং এটি বর্তমান আউটপুটের গণনায় প্রয়োগ করে, অর্থাৎ লুকানো স্তরগুলির মধ্যে নোডগুলি আর সংযুক্ত নয় তবে সংযুক্ত থাকে না এবং লুকানো স্তরটির ইনপুটটি কেবল ইনপুট স্তরটির আউটপুটকেই অন্তর্ভুক্ত করে না এটি পূর্ববর্তী মুহুর্ত থেকে লুকানো স্তরের আউটপুটও অন্তর্ভুক্ত করে।
3) আরএনএন এর মূল প্রয়োগ ক্ষেত্রগুলি কী কী?
আরএনএন-এর অনেকগুলি প্রয়োগের ক্ষেত্র রয়েছে, এটি বলা যেতে পারে যে যতক্ষণ কালানুক্রমিক ক্রমের সমস্যা হিসাবে বিবেচনা করা হয় ততক্ষণ আরএনএন এটি সমাধান করার জন্য ব্যবহার করা যেতে পারে some এখানে কিছু সাধারণ প্রয়োগ ক্ষেত্র রয়েছে:
① প্রাকৃতিক ভাষা প্রসেসিং (NLP) : আছে ভিডিও প্রক্রিয়াকরণ , টেক্সট প্রজন্ম , ভাষা মডেল , ইমেজ প্রসেসিং
② মেশিন অনুবাদ , মেশিন রচনা উপন্যাস
Ech স্পিচ স্বীকৃতি
④ চিত্র বিবরণ প্রজন্ম
⑤ পাঠ্যের মিলের গণনা
⑥ নতুন অ্যাপ্লিকেশন ক্ষেত্র যেমন সঙ্গীত সুপারিশ , নেটেস কোয়ালা পণ্য সুপারিশ , ইউটিউব ভিডিও প্রস্তাবনা ইত্যাদি,
দুটি আরএনএন (পুনরাবৃত্ত নিউরাল নেটওয়ার্ক)
1) আরএনএন মডেল স্ট্রাকচার
এর আগে আমরা বলেছিলাম যে আরএনএন সময়ের "স্মৃতি" এর ফাংশন রয়েছে, সুতরাং এটি তথাকথিত "স্মৃতি" কীভাবে উপলব্ধি করতে পারে?
চিত্র 1 আরএনএন কাঠামোর ডায়াগ্রাম
চিত্র ১-এ দেখানো হয়েছে, আমরা দেখতে পাচ্ছি যে আরএনএন হায়ারার্কি সিএনএন এর চেয়ে সহজ। এটি মূলত একটি ইনপুট স্তর , একটি লুকানো স্তর এবং একটি আউটপুট স্তর নিয়ে থাকে ।
এবং আপনি দেখতে পাবেন যে লুকানো স্তরটিতে একটি তীর রয়েছে যা তথ্যটির চক্রীয় আপডেটকে নির্দেশ করে time এটি সময় মেমরির ক্রিয়াটি বাস্তবায়নের পদ্ধতি।
আপনি যদি এখানে এখনও আরএনএন এর অর্থ বুঝতে না পারেন তবে পড়া চালিয়ে যান!
চিত্র 2 লুকানো স্তর স্তরক্রম
চিত্র 2 টি লুকানো স্তরটির শ্রেণিবিন্যাসের প্রসার দেখায়। টি -1, টি, টি + 1 সময় ধারা উপস্থাপন করে এক্স এক্স ইনপুট নমুনা উপস্থাপন করে St সেন্ট টি সময়ে নমুনার স্মৃতি উপস্থাপন করে -1 + ইউ * এক্সটি) ডাব্লু ইনপুটটির ওজন, ইউ এই মুহুর্তে ইনপুট নমুনার ওজন এবং আউটপুট নমুনার ওজন।
টি = 1 এ, সাধারণ সূচনা ইনপুট এস 0 = 0, এলোমেলোভাবে ডাব্লু, ইউ, ভি শুরু করে এবং নিম্নলিখিত সূত্র গণনা করে:
এর মধ্যে চ এবং জি অ্যাক্টিভেশন ফাংশন রয়েছে তাদের মধ্যে চ, তানহ, রেলু, সিগময়েড এবং অন্যান্য অ্যাক্টিভেশন ফাংশন হতে পারে, জি সাধারণত সফটম্যাক্স বা অন্যান্য other
সময়ের অগ্রগতি, এবং এই সময়ে রাষ্ট্রের এস 1, 1 মেমরির স্থিতি হিসাবে, পরবর্তী মুহুর্তের পূর্বাভাসে অংশ নেবে, এটি হল:
সাদৃশ্য দ্বারা, আপনি চূড়ান্ত আউটপুট মান পেতে পারেন:
দ্রষ্টব্য : 1. এখানে ডাব্লু, ইউ, ভি প্রতিটি মুহুর্তে সমান ( ওজন ভাগ করে নেওয়া )।
২. গোপনীয় অবস্থাটি এই হিসাবে বোঝা যায়: এস = এফ (বিদ্যমান ইনপুট + অতীতের স্মৃতি সংক্ষিপ্তসার )
2) আরএনএন এর পিছনে প্রচার
এর আগে আমরা আরএনএন এর ফরোয়ার্ড প্রসারণ পদ্ধতি প্রবর্তন করেছি, সুতরাং আরএনএন এর ওজন পরামিতিগুলি কীভাবে আপডেট হবে?
প্রতিটি আউটপুট OT ত্রুটি মান এট একটি মান থাকবে, মোট ত্রুটি হিসাবে প্রকাশ করা যেতে পারে: ।
ক্ষতি ফাংশন ব্যবহার করতে পারেন ক্রস এনট্রপি ক্ষতি ফাংশন ব্যবহার করা যায় স্কোয়ারড ত্রুটি ক্ষতি ফাংশন ।
যেহেতু পদক্ষেপ প্রতিটি পদক্ষেপ আউটপুট না শুধুমাত্র বর্তমান নেটওয়ার্কে উপর নির্ভর করে, এবং বেশ কিছু পদক্ষেপ সামনে নেটওয়ার্ক রাষ্ট্র প্রয়োজন, বিপি অ্যালগরিদম পর্যালোচনা সময় Backpropagation (মাধ্যমে তারপর এই বলা হয় BPTT ), ত্রুটি মান বিপরীত পাস আউটপুট, ব্যবহার গ্রেডিয়েন্ট বংশদ্ভুত পদ্ধতি আপডেট করা হয়েছে ((আপনি যদি বিপির সাথে পরিচিত না হন তবে আপনি এখানে উল্লেখ করতে পারেন )
এটি হল প্রয়োজনীয় প্যারামিটারের গ্রেডিয়েন্ট:
প্রথমে আমরা ডব্লিউ এর আপডেট পদ্ধতিটি সমাধান করি , ডাব্লু এর পূর্ববর্তী আপডেট থেকে দেখা যায় যে এটি প্রতিটি মুহুর্তে বিচ্যুতিগুলির আংশিক ডেরাইভেটিভসের যোগফল।
এখানে আমরা উদাহরণ হিসাবে সময় t = 3 নিই। চেইন ডেরাইভেশন বিধি অনুসারে আমরা সময় আংশিক ডেরিভেটিভ পেতে পারি t = 3 হিসাবে:
এই মুহুর্তে, সূত্র অনুসারে আমরা দেখতে পাব যে ডাব্লু ছাড়াও এস 3 পূর্ববর্তী মুহুর্তে এস 2 এর সাথেও সম্পর্কিত।
এস 3 এর জন্য, নিম্নলিখিত সূত্রটি পেতে সরাসরি প্রসারিত করুন:
এস 2 এর জন্য, নিম্নলিখিত সূত্রটি পেতে সরাসরি প্রসারিত করুন:
এস 1 এর জন্য, নিম্নলিখিত সূত্রটি পেতে সরাসরি প্রসারিত করুন:
উপরোক্ত তিনটি সূত্র একত্রিত হওয়ার জন্য:
এটি সূত্র দেয়:
এখানে যেটি ব্যাখ্যা করতে হবে তার অর্থ হ'ল এস 3 এর S2 এর প্রভাব বিবেচনা না করে সরাসরি ডাব্লুকে পৃথক করে (এটি উদাহরণস্বরূপ, y = f (x) * g (x) x এর ডেরিভেটিভের সমান)
দ্বিতীয়টি হ'ল ইউ এর আপডেট পদ্ধতি Since যেহেতু ইউ এবং ডাব্লু প্যারামিটারটি একই, তাই এখানে তাদের বর্ণনা দেওয়া হবে না এবং শেষ পর্যন্ত প্রাপ্ত নির্দিষ্ট সূত্রটি নিম্নরূপ:
শেষ অবধি, ভি এর আপডেট হওয়া সূত্রটি দিন (ভি কেবলমাত্র আউটপুট ও এর সাথে সম্পর্কিত):
ট্রিপল আরএনএন-এর জন্য কিছু উন্নত অ্যালগরিদম
আমাদের সামনে RNN অ্যালগরিদম যে সময় সিরিজ সমস্যার সাথে প্রভাব চুক্তি খুবই ভালো, কিন্তু এখনও কিছু সমস্যা আছে, যা আরো গুরুতর প্রবণ গ্রেডিয়েন্ট অদৃশ্য বা গ্রেডিয়েন্ট বিস্ফোরণ সমস্যা (এর বিপি অ্যালগরিদম এবং সময় নির্ভর ফলাফলের ) দ্রষ্টব্য: এখানে গ্রেডিয়েন্টের অদৃশ্যতা বিপি-র মতো নয় Here এখানে, এটি মূলত সেই ঘটনাকে বোঝায় যে দীর্ঘ সময়ের কারণে স্মৃতির মান ছোট।
অতএব, উন্নত অ্যালগরিদমের একটি সিরিজ উঠে এসেছে e এখানে দুটি প্রধান অ্যালগরিদম: এলএসটিএম এবং জিআরইউ ।
এলএসটিএম এবং জিআরইউ মূলত গ্রেডিয়েন্ট নিখোঁজ হওয়া বা গ্রেডিয়েন্ট বিস্ফোরণের সমস্যা নিয়ে কাজ করে:
গ্রেডিয়েন্টগুলি অন্তর্ধানের জন্য : যেহেতু তাদের সকলের কাছে "মেমরি" সঞ্চয় করার একটি বিশেষ উপায় রয়েছে, তুলনামূলকভাবে বৃহত পূর্ববর্তী গ্রেডিয়েন্ট সহ "মেমরি" তাত্ক্ষণিকভাবে কোনও সাধারণ আরএনএন-এর মতো মুছে ফেলা হবে না, সুতরাং গ্রেডিয়েন্ট অদৃশ্য হওয়ার সমস্যাটি একটি নির্দিষ্ট পরিমাণে কাটিয়ে উঠতে পারে।
জন্য গ্রেডিয়েন্ট বিস্ফোরণ : গ্রেডিয়েন্ট বিস্ফোরণ সমস্যা কাটিয়ে উঠতে হয় গ্রেডিয়েন্ট ক্লিপিং হয়, আপনি গ্রেডিয়েন্ট গণনা করা হলে প্রান্তিক মানের মান বা থ্রেশহোল্ড গ -c কম ছাড়িয়ে গেছে, এই সময়ে গ্রেডিয়েন্ট C অথবা -c করা সেট করা হয়।
1) এলএসটিএম অ্যালগরিদম (দীর্ঘ স্বল্পমেয়াদী মেমরি, দীর্ঘ স্বল্পমেয়াদী মেমরি নেটওয়ার্ক) --- বর্তমানে ব্যবহৃত সবচেয়ে গুরুত্বপূর্ণ সময় সিরিজের অ্যালগোরিদম
চিত্র 3 এলএসটিএম অ্যালগরিদম কাঠামো
চিত্র 3 এলএসটিএম অ্যালগরিদমের কাঠামো দেখায়।
আরএনএন থেকে পৃথক: আরএনএন একটি সরল রৈখিক সমষ্টি প্রক্রিয়া L এলএসটিএম " গেট " কাঠামোর মাধ্যমে " সেল স্টেট " সম্পর্কিত তথ্য সরিয়ে বা যুক্ত করতে পারে, যা গুরুত্বপূর্ণ সামগ্রী এবং অ-গুরুত্বপূর্ণ সামগ্রীর ধারণাকে উপলব্ধি করে। অপসারণ: 0 এবং 1 এর মধ্যে একটি সম্ভাব্য মান হ'ল সিগময়েড স্তর মাধ্যমে আউটপুট, প্রতিটি অংশ কতটা পার করতে পারে তা বর্ণনা করে 0 এর অর্থ "টাস্ক ভেরিয়েবলগুলি পাস করার অনুমতি দেয় না", 1 এর অর্থ "সমস্ত ভেরিয়েবলগুলি পাস করার জন্য চালানো হয়"।
ভুলে যাওয়ার গেটটিকে " ভুলে যাওয়া গেট " বলা হয়, তথ্য যুক্ত করার জন্য " ইনফরমেশন অ্যাডিং গেট " এবং অবশেষে আউটপুট জন্য " আউটপুট গেট " বলা হয় এটি এখানে প্রবর্তিত হবে না।
এছাড়াও, এলএসটিএম অ্যালগরিদমের কয়েকটি রূপ রয়েছে।
চিত্র ৪-তে দেখানো হয়েছে, এটি একটি " পিফোল সংযোগগুলি " স্তর যুক্ত করে যাতে গেট স্তরটি সেল স্টেট থেকে ইনপুট গ্রহণ করে।
চিত্র 4 এলএসটিএম অ্যালগরিদমের একটি বৈকল্পিক
চিত্র ৫-এ এলএসটিএমের আরও একটি বৈকল্পিক অ্যালগোরিদম দেখানো হয়েছে It এটি কাপলিং ভুলে যাওয়া গেট এবং আপডেট ইনপুট গেট (প্রথম এবং দ্বিতীয় গেট) এর মাধ্যমে হয়; এটি কী আর ভুলে যেতে হবে এবং কোন তথ্য আলাদাভাবে যুক্ত করতে হবে তা বিবেচনা করে না, এবং একসাথে ভাবুন।
চিত্র 5 এলএসটিএম অ্যালগরিদমের একটি বৈকল্পিক
2) জিআরইউ অ্যালগরিদম
জিআরইউ ২০১৪ সালে প্রস্তাবিত একটি উন্নত এলএসটিএম অ্যালগরিদম It এটি ভুলে যাওয়া গেট এবং ইনপুট গেটগুলিকে একক আপডেট গেটে একীভূত করে এবং ডেটা ইউনিট রাজ্য এবং লুকানো রাজ্যগুলিকে একত্রিত করে, মডেল কাঠামোটিকে এলএসটিএম থেকে সহজতর করে তোলে।
প্রতিটি অংশ নীচে হিসাবে সম্পর্ক সন্তুষ্ট:
টেনসরফ্লো ভিত্তিক চারটি বুনিয়াদি ক্রিয়াকলাপ এবং সংক্ষিপ্তসার
টেনসরফ্লো ব্যবহার করে বেসিক অপারেশনটি নিম্নরূপ:
# _*_coding:utf-8_*_
import tensorflow as tf
import numpy as np
'''
TensorFlow中的RNN的API主要包括以下两个路径:
1) tf.nn.rnn_cell(主要定义RNN的几种常见的cell)
2) tf.nn(RNN中的辅助操作)
'''
# 一 RNN中的cell
# 基类(最顶级的父类): tf.nn.rnn_cell.RNNCell()
# 最基础的RNN的实现: tf.nn.rnn_cell.BasicRNNCell()
# 简单的LSTM cell实现: tf.nn.rnn_cell.BasicLSTMCell()
# 最常用的LSTM实现: tf.nn.rnn_cell.LSTMCell()
# RGU cell实现: tf.nn.rnn_cell.GRUCell()
# 多层RNN结构网络的实现: tf.nn.rnn_cell.MultiRNNCell()
# 创建cell
# cell = tf.nn.rnn_cell.BasicRNNCell(num_units=128)
# print(cell.state_size)
# print(cell.output_size)
# shape=[4, 64]表示每次输入4个样本, 每个样本有64个特征
# inputs = tf.placeholder(dtype=tf.float32, shape=[4, 64])
# 给定RNN的初始状态
# s0 = cell.zero_state(4, tf.float32)
# print(s0.get_shape())
# 对于t=1时刻传入输入和state0,获取结果值
# output, s1 = cell.call(inputs, s0)
# print(output.get_shape())
# print(s1.get_shape())
# 定义LSTM cell
lstm_cell = tf.nn.rnn_cell.LSTMCell(num_units=128)
# shape=[4, 64]表示每次输入4个样本, 每个样本有64个特征
inputs = tf.placeholder(tf.float32, shape=[4, 48])
# 给定初始状态
s0 = lstm_cell.zero_state(4, tf.float32)
# 对于t=1时刻传入输入和state0,获取结果值
output, s1 = lstm_cell.call(inputs, s0)
print(output.get_shape())
print(s1.h.get_shape())
print(s1.c.get_shape())
অবশ্যই, আপনি দেখতে পেয়েছেন যে সেল.ক্যাল () ব্যবহার করে একটি রাষ্ট্র পেতে কেবল একবারে ফোন করতে পারে there একাধিক স্টেট রয়েছে যা একাধিকবার বলা প্রয়োজন, এটি আরও ঝামেলাজনক So তাই আমরা কীভাবে এটি সমাধান করব? আপনি নিম্নলিখিত আরএনএন-ভিত্তিক হস্তাক্ষরটি উল্লেখ করতে পারেন সংখ্যা স্বীকৃতি এবং শব্দের পূর্বাভাসের জন্য উদাহরণ স্বীকৃতি সমাধান।
এই নিবন্ধটি মূলত একটি টাইম সিরিজ আরএনএন নিউরাল নেটওয়ার্ক এবং এটি থেকে প্রাপ্ত ভেরিয়েন্ট অ্যালগরিদম এলএসটিএম এবং জিআরইয়ের পরিচয় দেয় t এটি আরএনএন অ্যালগরিদমের ব্যবহারের পরিস্থিতিও প্রবর্তন করে।
অবশ্যই স্থান সীমাবদ্ধতার কারণে দ্বি-মুখী আরএনএন এবং মাল্টি-লেয়ার আরএনএন এখানে চালু করা হয়নি। এছাড়াও, এলএসটিএম প্যারামিটার আপডেট অ্যালগরিদম এখানে প্রবর্তিত হয়নি, এবং এটি পরে যুক্ত করা হবে!
শেষ অবধি, যদি আপনার কোনও সমস্যা মনে হয় তবে একসাথে আলোচনা করতে এবং একসাথে অগ্রগতি করতে স্বাগতম!
0 comments:
Post a Comment