আমি মেশিন লার্নিং এবং ডিপ লার্নিংয়ের ধারণা ব্যাখ্যা করে একটি ব্লগের সিরিজ শুরু করছি বা বলতে পারি যে নীচের বইগুলি থেকে সংক্ষিপ্ত নোট সরবরাহ করবে। এই উদ্দেশ্যে আমি কয়েকটি বই অনুসরণ করব:
1. Deep Learning By — Ian Good fellow and Yoshua Bengio and Aaron Courville (Link)
2. Machine Learning Probabilistic Perspective: By — Kevin Murphy
3. The Elements of Statistical Learning: By — Trevor Hastie, Robert Tibshirani and Jerome Fried।
সূচনা
আজ, আর্টিচিয়াল ইন্টেলিজেন্স (এআই) একটি সমৃদ্ধ অনেকগুলি ব্যবহারিক প্রয়োগ এবং সক্রিয় গবেষণার বিষয় রয়েছে। আর্টিয়াল বুদ্ধিমত্তার কাছে আসল চ্যালেঞ্জ হ'ল মানুষের সমস্যাগুলি স্বজ্ঞাতভাবে সমাধান করা এবং একটি চিত্রের মধ্যে কথ্য উচ্চারণ এবং মুখের মতো বিষয়গুলি পর্যবেক্ষণ করে
উপরোক্ত সমস্যার সমাধান হ'ল কম্পিউটারগুলি অভিজ্ঞতা থেকে শিক্ষা নিতে এবং ধারণাটিকে একটি শ্রেণিবিন্যাসের দিক দিয়ে বিশ্বকে বোঝার অনুমতি দেওয়া, প্রতিটি ধারণাকে সহজ ধারণার সাথে সম্পর্কিত হিসাবে বিবেচনা করে। অভিজ্ঞতা থেকে জ্ঞান সংগ্রহের মাধ্যমে, এই পদ্ধতিটি মানব অপারেটরদের কম্পিউটারের প্রয়োজনীয় সমস্ত জ্ঞানকে আনুষ্ঠানিকভাবে নির্দিষ্ট করার প্রয়োজনীয়তা এড়িয়ে চলে। ধারণাগুলির শ্রেণিবিন্যাস কম্পিউটারকে সহজ ধারণার বাইরে তৈরি করে জটিল ধারণাগুলি শিখতে দেয়। আমরা যদি এই ধারণাগুলি একে অপরের উপরে নির্মিত হয় তা দেখানোর জন্য যদি একটি গ্রাফ আঁকি, তবে অনেক স্তর সহ গ্রাফটি গভীর। এই কারণে, আমরা এআই গভীর শিক্ষার এই পদ্ধতিকে কল করি।
বেশ কয়েকটি আর্টিয়াল গোয়েন্দা প্রকল্প আনুষ্ঠানিক ভাষায় বিশ্ব সম্পর্কে হার্ড-কোড জ্ঞান চেয়েছিল। একটি কম্পিউটার লজিক্যাল ইনফারেন্স বিধি ব্যবহার করে স্বয়ংক্রিয়ভাবে এই আনুষ্ঠানিক ভাষাগুলিতে বিবৃতি সম্পর্কে যুক্তি দেখাতে পারে। এটি আর্টিয়াল বুদ্ধিমত্তার জ্ঞান বেস পদ্ধতির নামে পরিচিত। এই প্রকল্পগুলির কোনওটিই বড় সাফল্যের দিকে যায় নি। সেরক (Lenat and Guha, 1989) এর মধ্যে সর্বাধিক বিখ্যাত প্রকল্পগুলির মধ্যে একটি 198
এখন, আমাদের মেশিনে প্রতিটি বৈশিষ্ট্য হার্ড-কোর করা সর্বদা সম্ভব নয়। সুতরাং তাদের নিজস্ব জ্ঞান অর্জনের ক্ষমতা প্রয়োজনীয়, কাঁচা ডেটা থেকে নিদর্শনগুলি আহরণের মাধ্যমে অর্জন করা যেতে পারে। এই ক্ষমতাটি মেশিন লার্নিং হিসাবে পরিচিত। সাধারণ মেশিন লার্নিং অ্যালগরিদমগুলির কার্য সম্পাদন তাদের দেওয়া ডেটার উপস্থাপনের উপর নির্ভর করে। আমাদের কাঙ্ক্ষিত সমস্যার উপস্থাপনে অন্তর্ভুক্ত তথ্যের প্রতিটি টুকরো বৈশিষ্ট্য হিসাবে চিহ্নিত (চিত্র 1)।
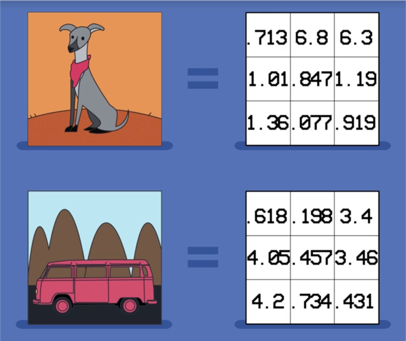
বৈশিষ্ট্যগুলির গুরুত্ব অত্যন্ত গুরুত্বপূর্ণ, উদাহরণস্বরূপ মানুষের একটি উদাহরণ নেওয়া যাক, আমরা সহজেই আরবি সংখ্যায় গাণিতিক সম্পাদন করতে পারি, তবে রোমান সংখ্যায় গাণিতিক করা অনেক বেশি সময়সাপেক্ষ। এটি অবাক হওয়ার মতো নয় যে উপস্থাপনের পছন্দটিতে মেশিন লার্নিং অ্যালগরিদমগুলির কার্য সম্পাদনের উপর একটি বিরাট পরিমাণ রয়েছে।
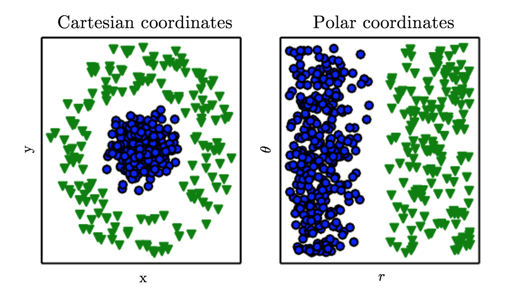
Fig 2. Importance of data representation: In first plot we have represented data in Cartesian coordinate and in second data has been represented in Polar coordinate. In second the task becomes simple to solve with a vertical line. (photo courtesy: Deep Learning Book)
এখন এই সমস্যাটির সমাধানের জন্য আমরা মেশিন লার্নিংটি কেবল প্রতিনিধিত্ব থেকে আউটপুট পর্যন্ত ম্যাপিং আবিষ্কার করতে পারি না তবে নিজে প্রতিনিধিত্বও করতে পারি। এটিকে representation learning /প্রতিনিধিত্ব শেখা বলা হয়। representation learning/উপস্থাপনা শেখা, অর্থাত, শ্রেণিবদ্ধ বা অন্যান্য predictors/ভবিষ্যদ্বাণীকারী তৈরি করার সময় দরকারী তথ্য আহরণ করা সহজ করে এমন ডেটার উপস্থাপনা শেখা। probabilistic models/সম্ভাব্য মডেলগুলির ক্ষেত্রে, একটি ভাল প্রতিনিধিত্ব প্রায়শই এমন হয় যা পর্যবেক্ষিত ইনপুটটির অন্তর্নিহিত ব্যাখ্যামূলক কারণগুলির উত্তরোত্তর বিতরণকে ক্যাপচার করে (আমরা আরও পরে আরও বিশদে এই বিষয়টিতে আবার দেখা করব)। representation learning/প্রতিনিধিত্বমূলক শেখার বিষয়ে কথা বলা autoencoder/অটোরকোডার টি ভাল উদাহরণ। একটি autoencoder/অটেনকোডার হ'ল একটি encoder /এনকোডার ফাংশনের সংমিশ্রণ যা ইনপুট ডেটাটিকে different representation রূপান্তর করে এবং একটি decoder function/ডিকোডার ফাংশন যা নতুন representation/উপস্থাপনাটিকে original format/মূল বিন্যাসে ফিরিয়ে দেয়।
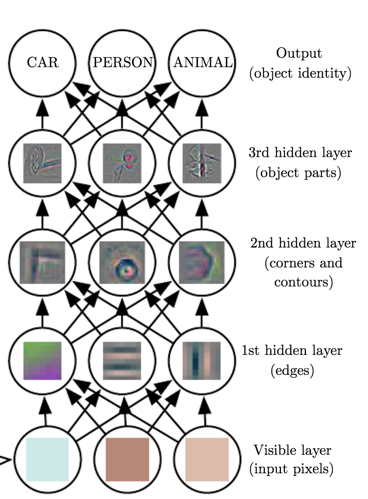
Fig 3. Illustration of a deep learning model. (Image courtesy: Deep Learning Book)
অবশ্যই, raw data থেকে এ জাতীয় high-level, abstract features গুলি সন্ধান করা খুব difficult হতে পারে।অনেকগুলি উপস্থাপনা যেমন ,শুধুমাত্র sophisticated/অত্যাধুনিক ব্যবহার করে সনাক্ত করা যায়,তথ্যটি প্রায় human-level এর বোঝার।মূল সমস্যাটি সমাধান করার জন্য একটি representation/প্রতিনিধিত্ব প্রাপ্তি প্রায় সমান,উপস্থাপনা শেখার না,প্রথম নজরে, আমাদের সাহায্য বলে মনে হচ্ছে।ডিপ লার্নিং representation মূলক শিক্ষার ক্ষেত্রে এই কেন্দ্রীয় সমস্যাটি সমাধান করে অন্যদের হিসাবে প্রকাশিত উপস্থাপনাগুলি প্রবর্তন করে,সহজ উপস্থাপনা। গভীর শিক্ষার মাধ্যমে কম্পিউটারকে সহজ ধারণার বাইরে জটিল ধারণা তৈরি করতে দেয় (চিত্র 3)।কোনও মডেলের গভীরতা পরিমাপের দুটি প্রধান উপায় রয়েছে (চিত্র 4)।
- Number of sequential instructions that must be executed to evaluate the architecture.
- Depth of the graph describing how concepts are related to each other.
আর্কিটেকচার মূল্যায়নের জন্য অবশ্যই ক্রমবর্ধমান নির্দেশাবলীর সংখ্যা।
ধারণাগুলি একে অপরের সাথে সম্পর্কিত কী তা বর্ণনা করে গ্রাফের গভীরতা।
এই দুটি মতামতের মধ্যে কোনটি সবসময় পরিষ্কার নয় computational graph/গণনামূলক গ্রাফের গভীরতা, বা probabilistic/ সম্ভাব্য মডেলিং গ্রাফের গভীরতা- সবচেয়ে প্রাসঙ্গিক,এবং যেহেতু different লোকেরা তাদের গ্রাফগুলি তৈরি করতে ছোট ছোট উপাদানের সেট choose
করে কোনও কম্পিউটার প্রোগ্রামের দৈর্ঘ্যের জন্য কোনও একক সঠিক মান যেমন নেই তেমন কোনও স্থাপত্যের গভীরতার জন্য কোনও একক সঠিক মান নেই।কোনও মডেলকে "গভীর" হিসাবে যোগ্যতা অর্জনের জন্য কত গভীরতার প্রয়োজন তা নিয়ে সর্বসম্মতি নেই।
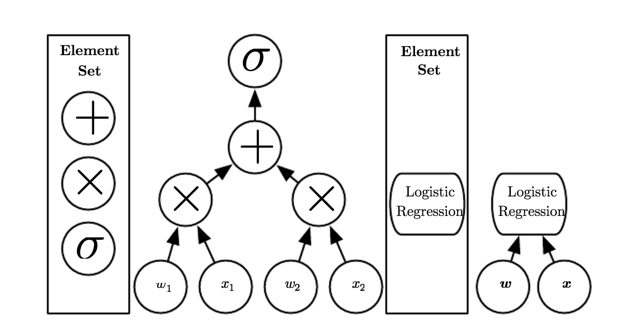
Fig 4. Illustration of computational graphs mapping an input to an output where each node performs an operation. (Image courtesy: Deep Learning Book)
চিত্র 5 বিভিন্ন ধরণের শেখার বিভাগে আসার মাধ্যমে আপনি তাদের মধ্যে পার্থক্য এবং সাদৃশ্য সম্পর্কে দুর্দান্ত ধারণা পাবেন।
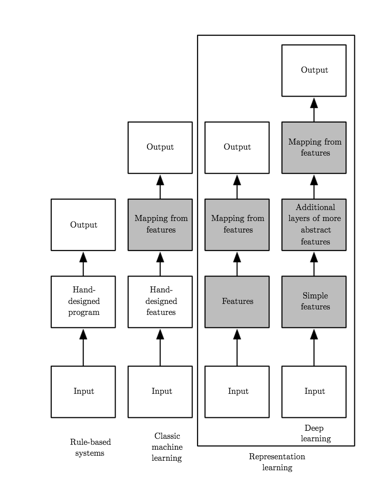
চিত্র 5. ফ্লোচার্টগুলি দেখায় যে কীভাবে একটি এআই সিস্টেমের different অংশগুলি different AI শাখাগুলির মধ্যে একে অপরের সাথে সম্পর্কিত। Shaded boxes গুলি এমন উপাদানগুলি নির্দেশ করে যা ডেটা থেকে শিখতে সক্ষম হয়। (ছবি সৌজন্যে: ডিপ লার্নিং বুক)
আধুনিক গভীর শিক্ষার প্রথম দিকের predecessors রা ছিলেন সাধারণ লিনিয়ার মডেল।এই মডেল গুলি n ইনপুট মান x1,....xn সেট করার জন্য ডিজাইন করা হয়েছিল। এবং an একটি আউটপুট y এর সাথে যুক্ত । এই মডেলগুলি weights w1, . . . , wn এর একটি সেট শিখবে, এবং তাদের আউটপুট গণনা করুন f(x, w) =x1*w1+···+xn*wn. । নিউরাল নেটওয়ার্ক গবেষণার এই প্রথম তরঙ্গ cybernetics/সাইবারনেটিক্স হিসাবে পরিচিত। 1950 এর দশকে, perceptron (Rosenblatt, 1958, 1962) প্রথম বিভাগে পরিণত হয়েছিল যা প্রতিটি বিভাগের ইনপুটগুলির উদাহরণ হিসাবে দেওয়া বিভাগগুলি ওজনগুলি শিখতে পারে। adaptive linear element(ADALINE) , যা প্রায় একই সময়ের থেকে আসে, কেবলমাত্র একটি আসল সংখ্যার ( (Widrow and Hoff, 1960)) পূর্বাভাস দেওয়ার জন্য f (x) এর মান সহজেই ফিরিয়ে দেয় এবং ডেটা থেকে এই সংখ্যাগুলির গণনা করাও শিখতে পারে।
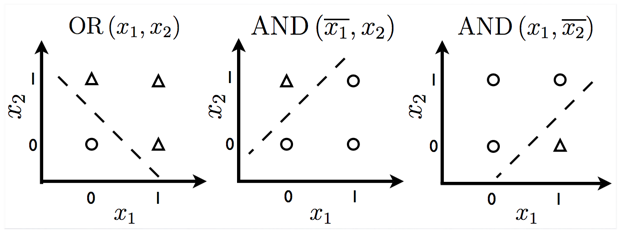
Fig 6. Functions which can be predicted by linear models.
পেরসেপ্ট্রন এবং ADALINE দ্বারা ব্যবহৃত f (x, w) ভিত্তিক মডেলগুলিকে লিনিয়ার মডেল বলা হয়।
লিনিয়ার মডেলগুলির অনেক সীমাবদ্ধতা রয়েছে। সর্বাধিক বিখ্যাত, তারা XOR ফাংশন শিখতে পারে না, যেখানে f ([0,1], w) = 1 এবং f ([1,0], w) = 1 তবে f ([1,1], w) = 0 এবং f ([0,0], ডাব্লু) = 0 (চিত্র 7)
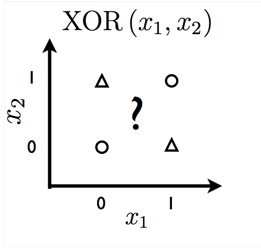
Fig 7. Cannot be solved by linear model.
লিনিয়ার মডেলের এই সীমাবদ্ধতা আরও বাস্তবধর্মী কৌশলগুলির দিকে পরিচালিত করে। নিম্নলিখিত deep learning কারণের কারণে আজ গভীর শিক্ষাগুলি আগের তুলনায় অনেক বেশি হারে বাড়ছে:
- Increasing Dataset Sizes
- Increasing Model Sizes
- Increasing Accuracy, Complexity and Real-World Impact
ডেটা সেটটি মাপ বৃদ্ধি,মডেল আকার বৃদ্ধিনির্ভুলতা, জটিলতা এবং রিয়েল-ওয়ার্ল্ড ইমপ্যাক্ট বাড়ানো
0 comments:
Post a Comment