ডিপ লার্নিং কেন? নন-লিনিয়ার সমস্যা, ফিচার ক্রস
গিটবুকে জুপিটার নোটবুক এখনো ঠিকমতো রেন্ডার হয়না। সরাসরি পড়ুন নিচের লিংক থেকে;
এই প্রশ্নটা প্রায় অনেকেই করেন, মেশিন লার্নিং থাকতে ডিপ লার্নিং কেন দরকার পড়লো? এর উত্তর সবার জানা, তবে যে জন্য আমি ডিপ লার্নিংয়ে এসেছি সেটা আলাপ করি বরং। আমার একটা সমস্যা হচ্ছে, যে কোন ডাটা পেলেই সেটাকে আগে কাগজে প্লট করে ফেলি। তাহলে সেটা বুঝতে সুবিধা হয়।
মনে আছে আমাদের আইরিশ ডাটা সেটের কথা? সেখানে সবগুলো প্রজাতির ডাটাকে প্লট করলে কিছুটা এরকম দেখা যেত। তিন প্রজাতিকে ছবির মধ্যে আলাদা করা খুব একটা সমস্যা ছিল না। কারণ তিনটা ছবির মধ্যে দুটো লাইন বা সরলরেখা টানলেই কিন্তু তিনটা প্রজাতিকে আলাদা করে ফেলা যেত। এক পিকচার থেকে আরেক পিকচারের ডিসিশন সারফেস এবং ডিসিশন বাউন্ডারি সরলরেখার।
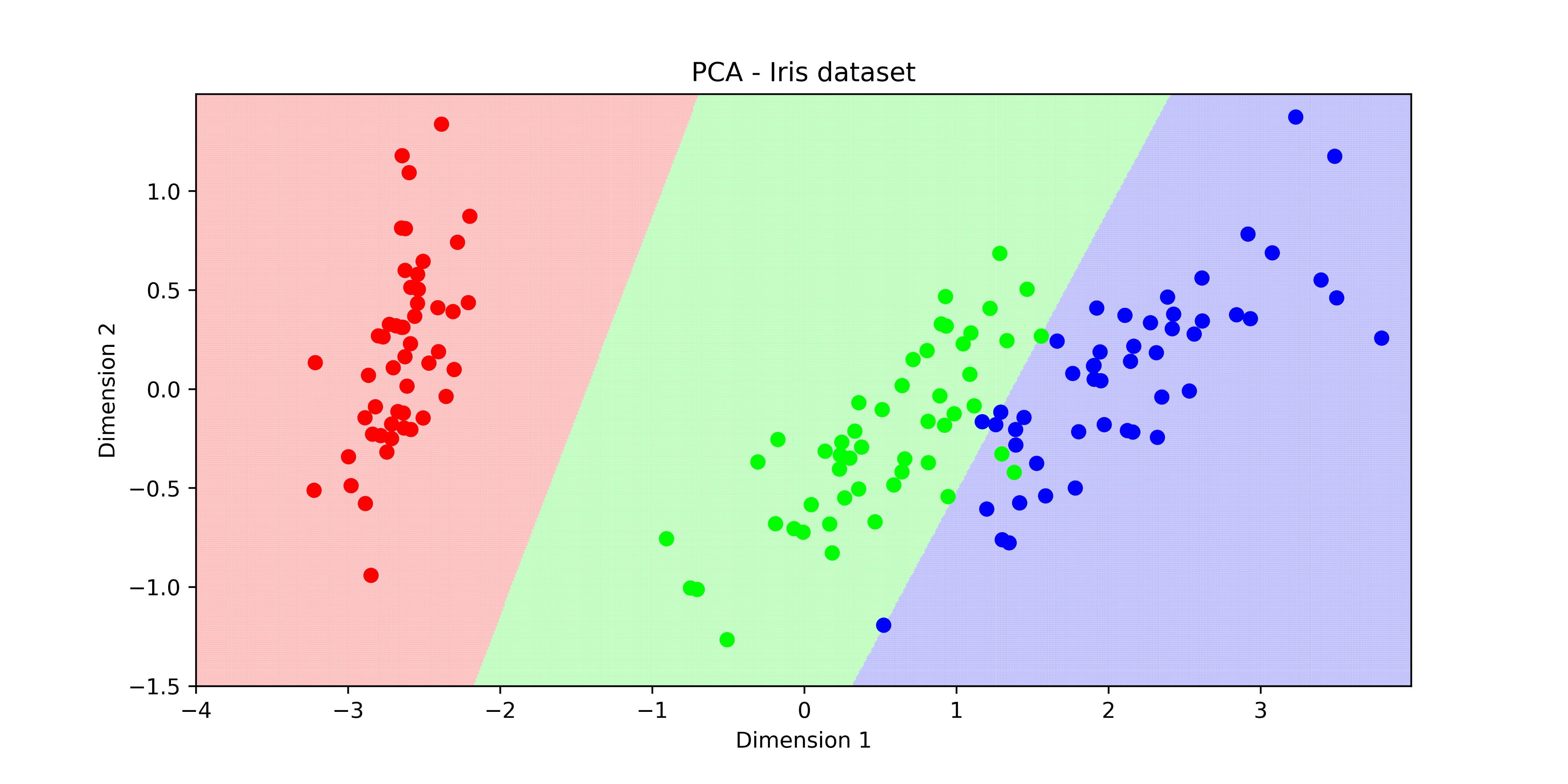 চিত্রঃ আইরিশ ডেটাসেটের ডিসিশন বাউন্ডারি
চিত্রঃ আইরিশ ডেটাসেটের ডিসিশন বাউন্ডারি
চিত্রঃ আইরিশ ডেটাসেটের ডিসিশন বাউন্ডারি
এখানে ইচ্ছেমতো সাইকিট-লার্ন এবং টেন্সর-ফ্লো ব্যবহার করছি কাজের সুবিধার্থে। কখন কোনটা কাজে লাগে সেটা জানবেন নিজে নিজে।
সরল রেখায় ডিসিশন সারফেস/বাউন্ডারি বানানো যায় সহজে। কোড কমানোর জন্য 'plot_decision_regions' নামের একটা হেলপার ফাংশন ব্যবহার করি।
from sklearn import datasetsfrom sklearn.svm import SVCfrom mlxtend.plotting import plot_decision_regionsimport matplotlib.pyplot as plt%matplotlib inline# দুটো ফিচার নিচ্ছিiris = datasets.load_iris()X = iris.data[:, [0, 2]]y = iris.target# ক্লাসিফায়ার ট্রেনিং করছিsvm = SVC(C=0.5, kernel='linear')svm.fit(X, y)# প্লট করছি নতুন লাইব্রেরি দিয়েplot_decision_regions(X, y, clf=svm, legend=2)# দু পাশের লেখাগুলো সেট করছিplt.xlabel('sepal length [cm]')plt.ylabel('petal length [cm]')plt.title('SVM on Iris')plt.show()

বয়সের সাথে ওজন বাড়বে, বাড়ি স্কয়ার ফিট এর সাথে দাম বাড়বে, এধরনের লিনিয়ার সম্পর্কগুলোতে ডাটাকে প্লট করলে সেগুলোকে সোজা লাইন দিয়ে আলাদা করে দেখা যায় সহজে। কিন্তু ডাটা যদি এমন হয়? কিভাবে একটা লাইন দিয়ে দুটো ফিচারকে ভাগ করবেন?
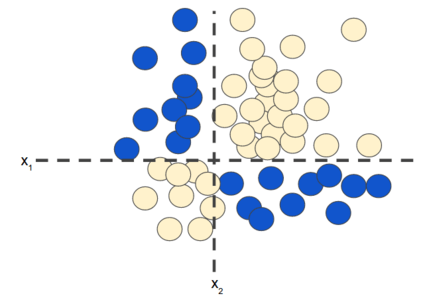
চিত্রঃ নন-লিনিয়ার ক্লাসিফিকেশন সমস্যা
এটা নন-লিনিয়ার ক্লাসিফিকেশন সমস্যা। নন-লিনিয়ার এর সমস্যা হচ্ছে তাদের 'ডিসিশন সারফেস' সরলরেখা নয়। এই ছবিতে যদি দুটো ফিচার থাকে তাহলে সেটা দিয়ে এই সমস্যার সমাধান করা সম্ভব নয়। সেটার জন্য প্রয়োজন ফিচার ক্রস। মানে এই নতুন ফিচার কয়েকটা ফিচার স্পেসের গুণফলের আউটকাম নন-লিনিয়ারিটিকে এনকোড করে মানে আরেকটা সিনথেটিক ফিচার তৈরি করে সেটার মাধ্যমে এই নন-লিনিয়ারিটিকে কিছুটা ডিল করা যায়। ক্রস এসেছে ক্রস প্রোডাক্ট থেকে। এখানে x1 = x2x3 (সাবস্ক্রিপ্ট হবে)
import pandas as pdimport numpy as npimport sklearnfrom sklearn.model_selection import train_test_split
sklearn.__version__
'0.21.3'
try:# %tensorflow_version only exists in Colab.# শুধুমাত্র জুপিটার নোটবুক/কোলাবে চেষ্টা করবো টেন্সর-ফ্লো ২.০ এর জন্য%tensorflow_version 2.xexcept Exception:pass
TensorFlow 2.x selected.
ধরুন আপনি ডাটা প্লট করে দেখলেন এই অবস্থা। কি করবেন? নিচের ছবি দেখুন। এই ডাটাসেটে অক্ষাংশ, দ্রাঘিমাংশ, ভূমির উচ্চতা ইত্যাদি আছে। আমরা সবগুলোর মধ্যে শুধুমাত্র অক্ষাংশ, দ্রাঘিমাংশ প্লট করছি। দেখুন কি অবস্থা। একটা ফিচার ভেতরে আরেকটা ঘিরে রয়েছে সেটাকে চারপাশ দিয়ে। এখন কিভাবে এদুটোকে আলাদা করবেন? সোজা লাইন টেনে সম্ভব না। শুরুতে চেষ্টা করি সাপোর্ট ভেক্টর মেশিন, এরপর নিউরাল নেটওয়ার্ক দিয়ে।
# df = pd.read_csv('geoloc_elev.csv')df = pd.read_csv('https://raw.githubusercontent.com/raqueeb/TensorFlow2/master/datasets/geoloc_elev.csv')# আমাদের দুটো ফিচার হলেই যথেষ্টX = df[['lat', 'lon']].valuesy = df['target'].values
df.plot(kind='scatter',x='lat',y='lon',c='target',cmap='bwr');

# এখানে সাপোর্ট ভেক্টর মেশিন ব্যবহার করছিfrom sklearn.svm import SVCclf = SVC(gamma='auto')clf.fit(X, y)
SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,decision_function_shape='ovr', degree=3, gamma='auto', kernel='rbf',max_iter=-1, probability=False, random_state=None, shrinking=True,tol=0.001, verbose=False)
# প্লটিং এর কিছু লাইব্রেরি ব্যবহার করছি, plot_decision_regions লাইব্রেরিটা বেশ ভালোimport matplotlib.pyplot as pltfrom mlxtend.plotting import plot_decision_regions
plot_decision_regions(X=X, y=y, clf=clf, legend=2)plt.xlabel("x", size=5)plt.ylabel("y", size=5)plt.title('SVM Decision Region Boundary', size=6)plt.show()

মেশিন লার্নিং এ ফিচার ক্রসের সুবিধা থাকলেও আমার পছন্দের ব্যাপার হচ্ছে মডেলে নন লিনিয়ারিটি ঢুকানো। মডেলে নন লিনিয়ারিটি ঢুকাতে গেলে নিউরাল নেটওয়ার্ক ভালো একটা উপায়। আমরা একটা ছবি আঁকি লিনিয়ার মডেলের। তিনটে ইনপুট ফিচার। ইনপুট ফিচারের সাথে ওয়েটকে যোগ করে নিয়ে এলাম আউটপুটে। আপনার কি মনে হয় এভাবে মডেলে নন-লিনিয়ারিটি ঢুকানোর সম্ভব? আপনি বলুন।
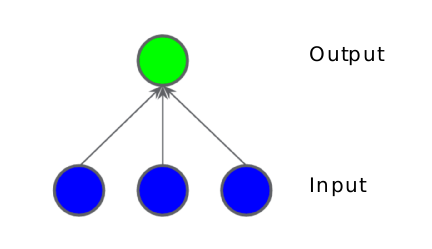
চিত্রঃ তিনটা ইনপুট যাচ্ছে একটা নিউরাল নেটওয়ার্কে
পরের ছবিতে আমরা একটা হিডেন লেয়ার যোগ করি। হিডেন লেয়ারের অর্থ হচ্ছে এর মধ্যে কিছু মাঝামাঝি ভ্যালু যোগ করা। আগের ইনপুট লেয়ার থেকে এই লেয়ারে তাদের ওয়েটগুলোর যোগফল পাঠিয়ে দিচ্ছে সামনের লেয়ারে। এখানে সামনে লেয়ার হচ্ছে আউটপুট। ইনপুট থেকে ওয়েট যোগ করে সেগুলোকে পাঠিয়ে দিচ্ছে আউটপুট লেয়ারে। ইংরেজিতে আমরা বলি 'ওয়েটেড সাম অফ প্রিভিয়াস নোডস'। এখনো কি মডেলটা লিনিয়ার? মডেল অবশ্যই লিনিয়ার হবে কারণ আমরা এ পর্যন্ত যা করেছি তা সব লিনিয়ার ইনপুটগুলোকেই একসাথে করেছি। নন-লিনিয়ারিটি যোগ করার মতো এখনো কিছু করিনি।
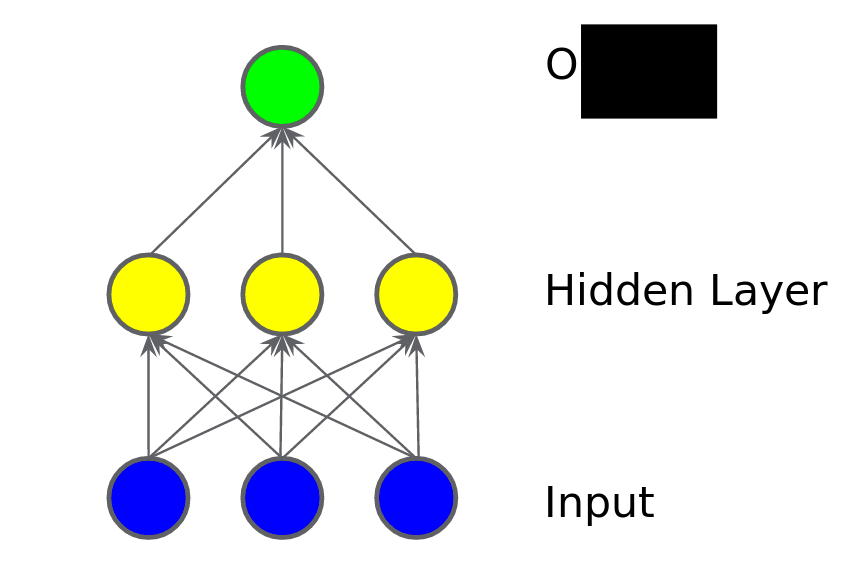 চিত্রঃ যোগ করলাম প্রথম হিডেন লেয়ার, লিনিয়ারিটি বজায় থাকবে?
চিত্রঃ যোগ করলাম প্রথম হিডেন লেয়ার, লিনিয়ারিটি বজায় থাকবে?
চিত্রঃ যোগ করলাম প্রথম হিডেন লেয়ার, লিনিয়ারিটি বজায় থাকবে?
এরকম করে আমরা যদি আরেকটা হিডেন লেয়ার যোগ করি তাহলে কি হবে? নন লিনিয়ার কিছু হতে পারে? না। আমরা যতই লেয়ার বাড়াই না কেন এই আউটপুট হচ্ছে আসলে ইনপুটের একটা ফাংশন। মানে হচ্ছে ইনপুটের ওয়েট গুলোর একটা যোগফল। যাই যোগফল হোকনা কেন সবই লিনিয়ার। এই যোগফল আসলে আমাদের নন লিনিয়ার সমস্যা মেটাবে না।
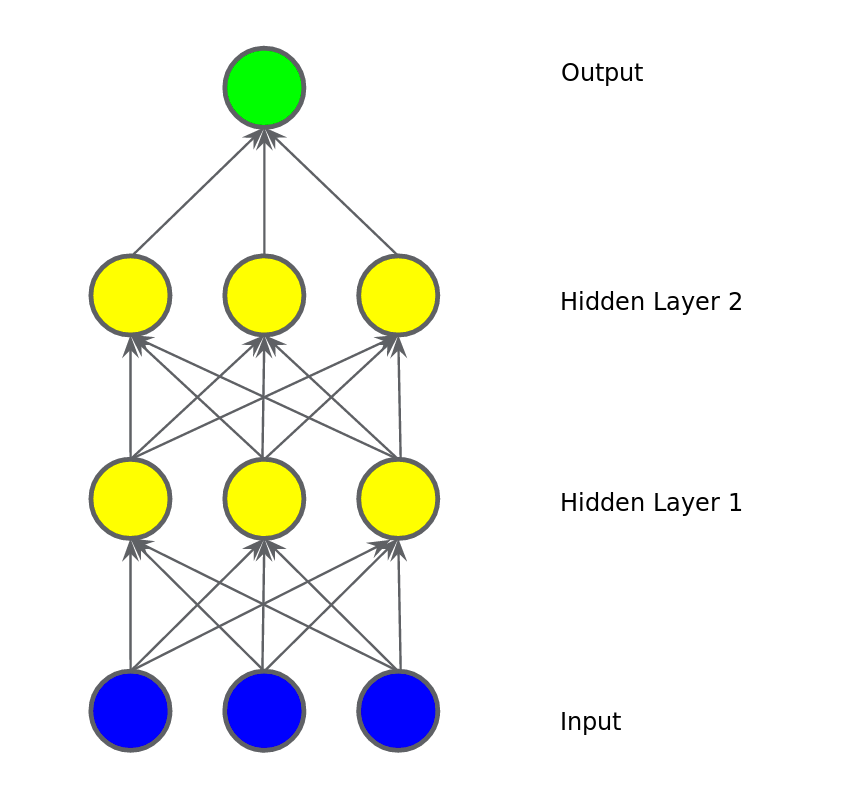 চিত্রঃ যোগ করলাম দ্বিতীয় হিডেন লেয়ার, লিনিয়ারিটি বজায় থাকবে?
চিত্রঃ যোগ করলাম দ্বিতীয় হিডেন লেয়ার, লিনিয়ারিটি বজায় থাকবে?
চিত্রঃ যোগ করলাম দ্বিতীয় হিডেন লেয়ার, লিনিয়ারিটি বজায় থাকবে?
একটা নন লিনিয়ার সমস্যাকে মডেল করতে গেলে আমাদের মডেলে যোগ করতে হবে নন লিনিয়ার কিছু ফাংশন। ব্যাপারটা আমাদেরকে নিজেদেরকেই ঢোকাতে হবে। সবচেয়ে মজার কথা হচ্ছে আমরা এই ইনপুটগুলোকে পাইপ করে হিডেন লেয়ারের শেষে একটা করে নন লিনিয়ার ফাংশন যোগ করে দিতে পারি। এই ছবিটা দেখুন। আমরা এক নাম্বার হিডেন লেয়ার এর পর একটা করে নন লিনিয়ার ফাংশন যোগ করে দিয়েছি যাতে সেটার আউটপুট সে পাঠাতে পারে দ্বিতীয় হিডেন লেয়ারে। এই ধরনের নন লিনিয়ার ফাংশনকে আমরা এর আগেও বলেছি অ্যাক্টিভেশন ফাংশন।
আমাদের পছন্দের অ্যাক্টিভেশন ফাংশন হচ্ছে রেল্যু, রেকটিফাইড লিনিয়ার ইউনিট অ্যাক্টিভেশন ফাংশন। কাজে এটা স্মার্ট, অনেকের থেকে ভালো আর সে কারণে এর ব্যবহার অনেক বেশি। ভুল হবার চান্স কম। ডায়াগ্রাম দেখলেই বুঝতে পারবেন - যদি ইনপুট শূন্য হয় তাহলে আউটপুট ০ আর ইনপুটের মান ০ থেকে বেশি হয় তাহলে সেটার আউটপুটে যাবে পরের লেয়ারে যাওয়ার জন্য। 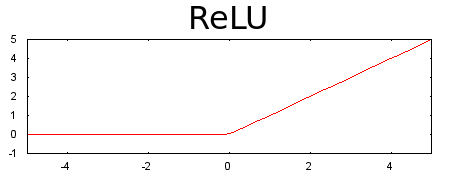 চিত্রঃ ইনপুটের সবকিছুর 'ওয়েটেড সাম' থেকে ০ আসলে সেটাই থাকবে বেশি হলে ১, মানে পরের লেয়ারে পার
চিত্রঃ ইনপুটের সবকিছুর 'ওয়েটেড সাম' থেকে ০ আসলে সেটাই থাকবে বেশি হলে ১, মানে পরের লেয়ারে পার
চিত্রঃ ইনপুটের সবকিছুর 'ওয়েটেড সাম' থেকে ০ আসলে সেটাই থাকবে বেশি হলে ১, মানে পরের লেয়ারে পার
আমরা যখন অ্যাক্টিভেশন ফাংশন যোগ করব তার সঙ্গে বেশি বেশি লেয়ার মডেলে ভালো কাজ করে। একটা নন লিনিয়ারিটি আরেকটা নন লিনিয়ারিটির উপর থাকাতে মডেল অনেক কমপ্লেক্স সম্পর্ক ধরতে পারে ইনপুট থেকে আউটপুট পর্যন্ত। মডেলের প্রতিটা লেয়ার তার অংশে কমপ্লেক্স জিনিসগুলো এক্সট্রাক্ট করতে পারে সেই কারণেই। অ্যাক্টিভেশন ফাংশন ছাড়া একটা নিউরাল নেটওয়াক আসলে আরেকটা লিনিয়ার রিগ্রেশন মডেল। এদিকে অ্যাক্টিভেশন ফাংশনে ব্যাক-প্রপাগেশন সম্ভব করে কারণ এর গ্রেডিয়েন্ট, তার এরর, ওয়েট এবং বায়াসকে আপডেট পাঠায়। শুরুর দিকের অ্যাক্টিভেশন ফাংশন হচ্ছে সিগময়েড। যার কাজ হচ্ছে যাই পাক না কেন সেটাকে ০ অথবা ১ এ পাঠিয়ে দেবে।
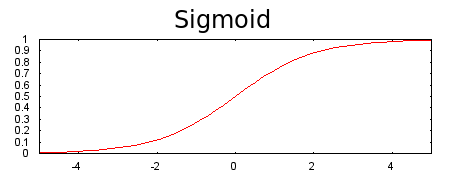 চিত্রঃ ইনপুটের সবকিছুর 'ওয়েটেড সাম' পাল্টে দেবে ০ থেকে ১ এর মধ্যে এই সিগময়েড
চিত্রঃ ইনপুটের সবকিছুর 'ওয়েটেড সাম' পাল্টে দেবে ০ থেকে ১ এর মধ্যে এই সিগময়েড
আবারো বলছি - সিগময়েড অ্যাক্টিভেশন ফাংশন লেয়ারগুলোর ইনপুটের/আউটপুটের যোগফলকে ০ অথবা ১ এর মধ্যে ফেলে দেয়। হয় এসপার না হলে ওসপার। লিনিয়ারিটির কোন স্কোপ থাকবে না। একটা ছবি দেখুন। ইকুয়েশন সহ।
আমার আরেকটা পছন্দের অ্যাক্টিভেশন ফাংশন হচ্ছে সফটম্যাক্স। এটা সাধারণত আমরা ব্যবহার করি দুইয়ের বেশি ক্লাসিফিকেশন সমস্যা হ্যান্ডেল করতে। সিগময়েড ভালো যখন আমরা দুটো ক্লাসিফিকেশন করি, তবে মাল্টিপল ক্লাসিফিকেশন এর জন্য সফটম্যাক্স অসাধারণ। যখন আউটপুট লেয়ার একটার সাথে আরেকটা 'মিউচুয়ালি এক্সক্লুসিভ' হয়, মানে কোন আউটপুট একটার বেশী আরেকটার ঘরে পড়বে না তাহলে সেটা 'সফটম্যাক্'স হ্যান্ডেল করবে। আমাদের যেকোনো শার্ট অথবা হাতে লেখা MNIST ইমেজগুলো যেকোন একটা ক্লাসেই পড়বে তার বাইরে নয়।
X_train, X_test, y_train, y_test = train_test_split(X, y,test_size = 0.3, random_state=0)
আপনার মনে হচ্ছে কি হবে?
from sklearn.linear_model import LogisticRegressionlr = LogisticRegression()lr.fit(X_train, y_train)
/usr/local/lib/python3.6/dist-packages/sklearn/linear_model/logistic.py:432: FutureWarning: Default solver will be changed to 'lbfgs' in 0.22. Specify a solver to silence this warning.FutureWarning)LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,intercept_scaling=1, l1_ratio=None, max_iter=100,multi_class='warn', n_jobs=None, penalty='l2',random_state=None, solver='warn', tol=0.0001, verbose=0,warm_start=False)
কিছুই হয়নি।
hticks = np.linspace(-2, 2, 101)vticks = np.linspace(-2, 2, 101)aa, bb = np.meshgrid(hticks, vticks)ab = np.c_[aa.ravel(), bb.ravel()]c = lr.predict(ab)cc = c.reshape(aa.shape)ax = df.plot(kind='scatter', c='target', x='lat', y='lon', cmap='bwr')ax.contourf(aa, bb, cc, cmap='bwr', alpha=0.5)

১টা ইনপুট লেয়ার, ১টা নিউরন, ১টা আউটপুট।
import tensorflow as tfmodel = tf.keras.models.Sequential([tf.keras.layers.Dense(1, input_dim=2, activation='tanh'),tf.keras.layers.Dense(1, activation='sigmoid')])model.compile(tf.keras.optimizers.SGD(lr=0.5), 'binary_crossentropy', metrics=['accuracy'])result = model.fit(X_train, y_train, epochs=20, validation_split=0.1)
Train on 945 samples, validate on 105 samplesEpoch 1/20WARNING:tensorflow:From /tensorflow-2.0.0-rc2/python3.6/tensorflow_core/python/ops/nn_impl.py:183: where (from tensorflow.python.ops.array_ops) is deprecated and will be removed in a future version.Instructions for updating:Use tf.where in 2.0, which has the same broadcast rule as np.where945/945 [==============================] - 1s 1ms/sample - loss: 0.6526 - accuracy: 0.6444 - val_loss: 0.6558 - val_accuracy: 0.6381Epoch 2/20945/945 [==============================] - 0s 65us/sample - loss: 0.6438 - accuracy: 0.6582 - val_loss: 0.6580 - val_accuracy: 0.6381Epoch 3/20945/945 [==============================] - 0s 56us/sample - loss: 0.6445 - accuracy: 0.6582 - val_loss: 0.6543 - val_accuracy: 0.6381Epoch 4/20945/945 [==============================] - 0s 62us/sample - loss: 0.6439 - accuracy: 0.6582 - val_loss: 0.6555 - val_accuracy: 0.6381Epoch 5/20945/945 [==============================] - 0s 62us/sample - loss: 0.6441 - accuracy: 0.6582 - val_loss: 0.6562 - val_accuracy: 0.6381Epoch 6/20945/945 [==============================] - 0s 60us/sample - loss: 0.6433 - accuracy: 0.6582 - val_loss: 0.6561 - val_accuracy: 0.6381Epoch 7/20945/945 [==============================] - 0s 65us/sample - loss: 0.6439 - accuracy: 0.6582 - val_loss: 0.6541 - val_accuracy: 0.6381Epoch 8/20945/945 [==============================] - 0s 64us/sample - loss: 0.6432 - accuracy: 0.6582 - val_loss: 0.6563 - val_accuracy: 0.6381Epoch 9/20945/945 [==============================] - 0s 62us/sample - loss: 0.6422 - accuracy: 0.6582 - val_loss: 0.6611 - val_accuracy: 0.6381Epoch 10/20945/945 [==============================] - 0s 61us/sample - loss: 0.6441 - accuracy: 0.6582 - val_loss: 0.6567 - val_accuracy: 0.6381Epoch 11/20945/945 [==============================] - 0s 61us/sample - loss: 0.6433 - accuracy: 0.6582 - val_loss: 0.6556 - val_accuracy: 0.6381Epoch 12/20945/945 [==============================] - 0s 58us/sample - loss: 0.6442 - accuracy: 0.6582 - val_loss: 0.6535 - val_accuracy: 0.6381Epoch 13/20945/945 [==============================] - 0s 64us/sample - loss: 0.6414 - accuracy: 0.6582 - val_loss: 0.6556 - val_accuracy: 0.6381Epoch 14/20945/945 [==============================] - 0s 59us/sample - loss: 0.6410 - accuracy: 0.6582 - val_loss: 0.6503 - val_accuracy: 0.6381Epoch 15/20945/945 [==============================] - 0s 59us/sample - loss: 0.6381 - accuracy: 0.6582 - val_loss: 0.6433 - val_accuracy: 0.6381Epoch 16/20945/945 [==============================] - 0s 60us/sample - loss: 0.6272 - accuracy: 0.6582 - val_loss: 0.6274 - val_accuracy: 0.6381Epoch 17/20945/945 [==============================] - 0s 62us/sample - loss: 0.6058 - accuracy: 0.6582 - val_loss: 0.6006 - val_accuracy: 0.6381Epoch 18/20945/945 [==============================] - 0s 62us/sample - loss: 0.5839 - accuracy: 0.6497 - val_loss: 0.5836 - val_accuracy: 0.6381Epoch 19/20945/945 [==============================] - 0s 60us/sample - loss: 0.5693 - accuracy: 0.6265 - val_loss: 0.5644 - val_accuracy: 0.6381Epoch 20/20945/945 [==============================] - 0s 66us/sample - loss: 0.5547 - accuracy: 0.6180 - val_loss: 0.5631 - val_accuracy: 0.6381
pd.DataFrame(result.history).plot(ylim=(-0.05, 1.05))

hticks = np.linspace(-2, 2, 101)vticks = np.linspace(-2, 2, 101)aa, bb = np.meshgrid(hticks, vticks)ab = np.c_[aa.ravel(), bb.ravel()]c = model.predict(ab)cc = c.reshape(aa.shape)ax = df.plot(kind='scatter', c='target', x='lat', y='lon', cmap='bwr')ax.contourf(aa, bb, cc, cmap='bwr', alpha=0.5)

model = tf.keras.models.Sequential([tf.keras.layers.Dense(4, input_dim=2, activation='tanh'),# এই লেয়ার পরে যোগ করে আমরা দেখবো# tf.keras.layers.Dense(4, activation='tanh'),tf.keras.layers.Dense(1, activation='sigmoid')])model.compile(tf.keras.optimizers.SGD(lr=0.5), 'binary_crossentropy', metrics=['accuracy'])h = model.fit(X_train, y_train, epochs=20, validation_split=0.1)
Train on 945 samples, validate on 105 samplesEpoch 1/20945/945 [==============================] - 0s 445us/sample - loss: 0.6506 - accuracy: 0.6254 - val_loss: 0.6501 - val_accuracy: 0.6381Epoch 2/20945/945 [==============================] - 0s 66us/sample - loss: 0.6330 - accuracy: 0.6582 - val_loss: 0.6388 - val_accuracy: 0.6381Epoch 3/20945/945 [==============================] - 0s 61us/sample - loss: 0.5987 - accuracy: 0.6582 - val_loss: 0.5745 - val_accuracy: 0.8000Epoch 4/20945/945 [==============================] - 0s 65us/sample - loss: 0.5086 - accuracy: 0.7714 - val_loss: 0.4680 - val_accuracy: 0.9429Epoch 5/20945/945 [==============================] - 0s 65us/sample - loss: 0.3835 - accuracy: 0.9693 - val_loss: 0.3352 - val_accuracy: 0.9905Epoch 6/20945/945 [==============================] - 0s 63us/sample - loss: 0.2611 - accuracy: 0.9979 - val_loss: 0.2248 - val_accuracy: 1.0000Epoch 7/20945/945 [==============================] - 0s 60us/sample - loss: 0.1792 - accuracy: 1.0000 - val_loss: 0.1615 - val_accuracy: 1.0000Epoch 8/20945/945 [==============================] - 0s 62us/sample - loss: 0.1321 - accuracy: 1.0000 - val_loss: 0.1212 - val_accuracy: 1.0000Epoch 9/20945/945 [==============================] - 0s 61us/sample - loss: 0.1028 - accuracy: 1.0000 - val_loss: 0.0966 - val_accuracy: 1.0000Epoch 10/20945/945 [==============================] - 0s 68us/sample - loss: 0.0838 - accuracy: 1.0000 - val_loss: 0.0802 - val_accuracy: 1.0000Epoch 11/20945/945 [==============================] - 0s 61us/sample - loss: 0.0705 - accuracy: 1.0000 - val_loss: 0.0678 - val_accuracy: 1.0000Epoch 12/20945/945 [==============================] - 0s 61us/sample - loss: 0.0607 - accuracy: 1.0000 - val_loss: 0.0588 - val_accuracy: 1.0000Epoch 13/20945/945 [==============================] - 0s 72us/sample - loss: 0.0533 - accuracy: 1.0000 - val_loss: 0.0519 - val_accuracy: 1.0000Epoch 14/20945/945 [==============================] - 0s 61us/sample - loss: 0.0473 - accuracy: 1.0000 - val_loss: 0.0464 - val_accuracy: 1.0000Epoch 15/20945/945 [==============================] - 0s 59us/sample - loss: 0.0426 - accuracy: 1.0000 - val_loss: 0.0419 - val_accuracy: 1.0000Epoch 16/20945/945 [==============================] - 0s 60us/sample - loss: 0.0387 - accuracy: 1.0000 - val_loss: 0.0383 - val_accuracy: 1.0000Epoch 17/20945/945 [==============================] - 0s 74us/sample - loss: 0.0355 - accuracy: 1.0000 - val_loss: 0.0352 - val_accuracy: 1.0000Epoch 18/20945/945 [==============================] - 0s 61us/sample - loss: 0.0328 - accuracy: 1.0000 - val_loss: 0.0324 - val_accuracy: 1.0000Epoch 19/20945/945 [==============================] - 0s 56us/sample - loss: 0.0303 - accuracy: 1.0000 - val_loss: 0.0301 - val_accuracy: 1.0000Epoch 20/20945/945 [==============================] - 0s 61us/sample - loss: 0.0283 - accuracy: 1.0000 - val_loss: 0.0282 - val_accuracy: 1.0000
from sklearn.metrics import confusion_matrix, classification_reporty_pred = model.predict_classes(X_test)
cm = confusion_matrix(y_test, y_pred)pd.DataFrame(cm,index=["Miss", "Hit"],columns=['pred_Miss', 'pred_Hit'])
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
vertical-align: top;
.dataframe tbody tr th {
}
.dataframe thead th {
}
|
pred_Miss
|
pred_Hit
|
Miss
|
311
|
0
|
Hit
|
0
|
139
|
train_score = model.evaluate(X_train, y_train, verbose=0)[1]test_score = model.evaluate(X_test, y_test, verbose=0)[1]print("""Accuracy scores:Train:\t{:0.3}Test:\t{:0.3}""".format(train_score, test_score))
Accuracy scores:Train: 1.0Test: 1.0
একদম পারফেক্ট হয়েছে বলতে গেলে। এতো অল্প লেয়ারে। লেয়ার বাড়িয়ে দেখুন, কমেন্ট সরিয়ে আবার চালান মডেল। আরো ভালো রেজাল্ট পাবেন।
hticks = np.linspace(-2, 2, 101)vticks = np.linspace(-2, 2, 101)aa, bb = np.meshgrid(hticks, vticks)ab = np.c_[aa.ravel(), bb.ravel()]c = model.predict(ab)cc = c.reshape(aa.shape)ax = df.plot(kind='scatter', c='target', x='lat', y='lon', cmap='bwr')ax.contourf(aa, bb, cc, cmap='bwr', alpha=0.5)

0 comments:
Post a Comment