TEXT CLASSIFICATION WITH TORCHTEXT
এই টিউটোরিয়ালটি কিভাবে টেক্সট শ্রেণীবিন্যাস ডেটাসেট ব্যবহার করতে দেখায়
torchtextসহ- AG_NEWS,
- SogouNews,
- DBpedia,
- YelpReviewPolarity,
- YelpReviewFull,
- YahooAnswers,
- AmazonReviewPolarity,
- AmazonReviewFull
এই উদাহরণটি দেখায় যে কীভাবে এই
TextClassificationডেটাসেটগুলির মধ্যে একটি ব্যবহার করে শ্রেণিবদ্ধকরণের জন্য তত্ত্বাবধানে থাকা শিক্ষার অ্যালগরিদমকে প্রশিক্ষণ দেওয়া যায় ।এনজিগ্রাম সহ ডেটা লোড করুন
স্থানীয় শব্দের ক্রম সম্পর্কে কিছু আংশিক তথ্য ক্যাপচারের জন্য এনগ্রাম বৈশিষ্ট্যের একটি ব্যাগ প্রয়োগ করা হয়। অনুশীলনে, দ্বি-গ্রাম বা ত্রি-গ্রাম প্রয়োগ করা হয় কেবলমাত্র একটি শব্দের চেয়ে শব্দের গোষ্ঠী হিসাবে বেশি সুবিধা। একটি উদাহরণ:
"load data with ngrams"
Bi-grams results: "load data", "data with", "with ngrams"
Tri-grams results: "load data with", "data with ngrams"
TextClassificationডেটাসেট এনজিআরএস পদ্ধতি সমর্থন করে। 2 কে এনগ্রগ্রাম সেট করে, ডেটাসেটে উদাহরণ পাঠ্যটি একক শব্দের সাথে দ্বি-গ্রাম স্ট্রিংয়ের তালিকা হবে।import torch
import torchtext
from torchtext.datasets import text_classification
NGRAMS = 2
import os
if not os.path.isdir('./.data'):
os.mkdir('./.data')
train_dataset, test_dataset = text_classification.DATASETS['AG_NEWS'](
root='./.data', ngrams=NGRAMS, vocab=None)
BATCH_SIZE = 16
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
মডেল সংজ্ঞায়িত করুন
মডেলটি এম্বেডিংবাগ স্তর এবং লিনিয়ার স্তর (নীচের চিত্রটি দেখুন) নিয়ে গঠিত।
nn.EmbeddingBag এমবেডিংয়ের একটি "ব্যাগ" এর গড় মান গণনা করে। এখানে পাঠ্য এন্ট্রিগুলির পৃথক দৈর্ঘ্য রয়েছে। nn.EmbeddingBagপাঠ্যের দৈর্ঘ্য অফসেটগুলিতে সংরক্ষিত হওয়ায় এখানে কোনও প্যাডিংয়ের প্রয়োজন নেই।
অতিরিক্তভাবে, যেহেতু
nn.EmbeddingBagফ্লাইয়ের এম্বেডিংগুলি জুড়ে গড়ে গড় জমা হয় , তাই nn.EmbeddingBagটেনারগুলির ক্রম প্রক্রিয়া করার জন্য কর্মক্ষমতা এবং মেমরির দক্ষতা বাড়িয়ে তুলতে পারে।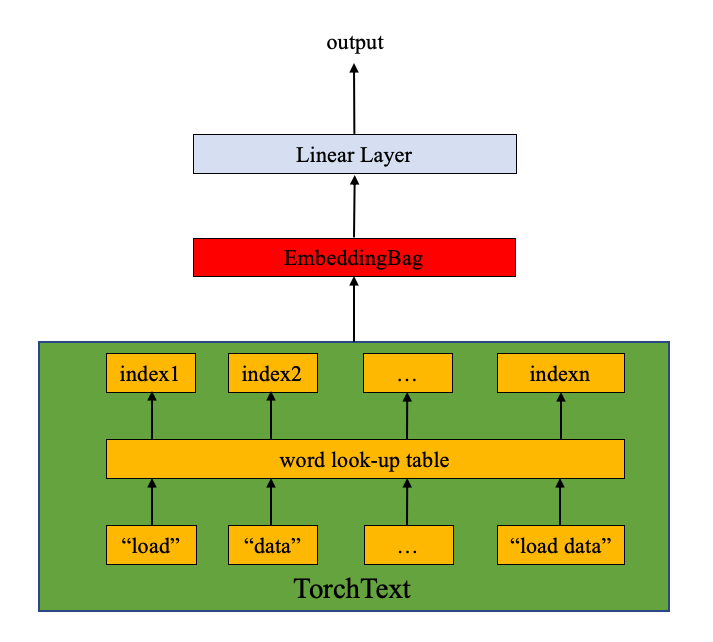
import torch.nn as nn
import torch.nn.functional as F
class TextSentiment(nn.Module):
def __init__(self, vocab_size, embed_dim, num_class):
super().__init__()
self.embedding = nn.EmbeddingBag(vocab_size, embed_dim, sparse=True)
self.fc = nn.Linear(embed_dim, num_class)
self.init_weights()
def init_weights(self):
initrange = 0.5
self.embedding.weight.data.uniform_(-initrange, initrange)
self.fc.weight.data.uniform_(-initrange, initrange)
self.fc.bias.data.zero_()
def forward(self, text, offsets):
embedded = self.embedding(text, offsets)
return self.fc(embedded)
একটি উদাহরণ শুরু করুন
এজি_নউইউএস ডেটাসেটটিতে চারটি লেবেল রয়েছে এবং ক্লাসের সংখ্যা চারটি।
1 : World
2 : Sports
3 : Business
4 : Sci/Tec
ভোকাবের আকারটি ভোকাবের দৈর্ঘ্যের সমান (একক শব্দ এবং এনগ্রাম সহ)। শ্রেণীর সংখ্যা লেবেলের সংখ্যার সমান, যা এজি_নউইউএস ক্ষেত্রে চারটি।
VOCAB_SIZE = len(train_dataset.get_vocab())
EMBED_DIM = 32
NUN_CLASS = len(train_dataset.get_labels())
model = TextSentiment(VOCAB_SIZE, EMBED_DIM, NUN_CLASS).to(device)
ব্যাচ উত্পন্ন করতে ব্যবহৃত ফাংশন
যেহেতু পাঠ্য এন্ট্রিগুলির পৃথক দৈর্ঘ্য রয়েছে তাই একটি কাস্টম ফাংশন জেনারেট_ব্যাচ () ডেটা ব্যাচ এবং অফসেটগুলি তৈরি করতে ব্যবহৃত হয়। ফাংশনটি ভিতরে প্রবেশ করা
collate_fnহয় torch.utils.data.DataLoader। ইনপুটটি collate_fnহ'ল ব্যাচ_ সাইজের আকার সহ টেনারগুলির একটি তালিকা এবং collate_fnফাংশনটি তাদেরকে মিনি-ব্যাচে প্যাক করে। এখানে মনোযোগ দিন এবং নিশ্চিত করুন যে collate_fnএটি একটি শীর্ষ স্তরের ডিএফ হিসাবে ঘোষিত হয়েছে। এটি নিশ্চিত করে যে প্রতিটি কর্মীর মধ্যে ফাংশন উপলব্ধ।
মূল ডেটা ব্যাচের ইনপুটটিতে পাঠ্য এন্ট্রিগুলি একটি তালিকাতে প্যাক করা হয় এবং এর ইনপুট হিসাবে একক টেনসর হিসাবে কনকনেটেড হয়
nn.EmbeddingBag। অফসেটগুলি পাঠ্য সেন্সরটিতে পৃথক অনুক্রমের প্রারম্ভিক সূচকটি উপস্থাপন করার জন্য ডিলিটারগুলির একটি সেন্সর। লেবেল হ'ল একটি টেনসর যা পৃথক পাঠ্য প্রবেশের লেবেল সংরক্ষণ করে।def generate_batch(batch):
label = torch.tensor([entry[0] for entry in batch])
text = [entry[1] for entry in batch]
offsets = [0] + [len(entry) for entry in text]
# torch.Tensor.cumsum returns the cumulative sum
# of elements in the dimension dim.
# torch.Tensor([1.0, 2.0, 3.0]).cumsum(dim=0)
offsets = torch.tensor(offsets[:-1]).cumsum(dim=0)
text = torch.cat(text)
return text, offsets, label
মডেলটিকে প্রশিক্ষণ দিতে এবং ফলাফলগুলি মূল্যায়নের জন্য কার্যাদি সংজ্ঞায়িত করুন।
torch.utils.data.DataLoader পাইটর্চ ব্যবহারকারীদের জন্য প্রস্তাবিত, এবং এটি সমান্তরালে সহজেই ডেটা লোড করে তোলে (একটি টিউটোরিয়াল এখানে রয়েছে )। আমরা
DataLoaderএজি_নউইউএস ডেটাসেটগুলি লোড করতে এবং প্রশিক্ষণ / বৈধতার জন্য মডেলটিতে এটি প্রেরণ করতে এখানে ব্যবহার করি ।from torch.utils.data import DataLoader
def train_func(sub_train_):
# Train the model
train_loss = 0
train_acc = 0
data = DataLoader(sub_train_, batch_size=BATCH_SIZE, shuffle=True,
collate_fn=generate_batch)
for i, (text, offsets, cls) in enumerate(data):
optimizer.zero_grad()
text, offsets, cls = text.to(device), offsets.to(device), cls.to(device)
output = model(text, offsets)
loss = criterion(output, cls)
train_loss += loss.item()
loss.backward()
optimizer.step()
train_acc += (output.argmax(1) == cls).sum().item()
# Adjust the learning rate
scheduler.step()
return train_loss / len(sub_train_), train_acc / len(sub_train_)
def test(data_):
loss = 0
acc = 0
data = DataLoader(data_, batch_size=BATCH_SIZE, collate_fn=generate_batch)
for text, offsets, cls in data:
text, offsets, cls = text.to(device), offsets.to(device), cls.to(device)
with torch.no_grad():
output = model(text, offsets)
loss = criterion(output, cls)
loss += loss.item()
acc += (output.argmax(1) == cls).sum().item()
return loss / len(data_), acc / len(data_)
ডেটাসেটটি বিভক্ত করুন এবং মডেলটি চালান
যেহেতু মূল এজি_নউইউজের কোনও বৈধ ডেটাসেট নেই, তাই আমরা প্রশিক্ষণ ডাটাসেটকে 0.95 (ট্রেন) এবং 0.05 (বৈধ) এর বিভাজন অনুপাত সহ ট্রেন / বৈধ সেটগুলিতে বিভক্ত করি। এখানে আমরা পাইটর্চ কোর লাইব্রেরিতে torch.utils.data.dataset.random_split ফাংশন ব্যবহার করি ।
ক্রসএন্ট্রপি লস মাপদণ্ড একটি একক শ্রেণিতে nn.LogSoftmax () এবং nn.NLLLoss () একত্রিত করে। সি ক্লাসগুলির সাথে শ্রেণিবিন্যাসের সমস্যার প্রশিক্ষণ দেওয়ার সময় এটি দরকারী। এসজিডি অপ্টিমাইজার হিসাবে স্টোকাস্টিক গ্রেডিয়েন্ট বংশদ্ভুত পদ্ধতি প্রয়োগ করে। প্রাথমিক শিক্ষার হারটি 4.0 এ সেট করা হয়েছে। EPCHs এর মাধ্যমে শিক্ষার হার সামঞ্জস্য করতে এখানে স্টেপএলআর ব্যবহার করা হয়।
import time
from torch.utils.data.dataset import random_split
N_EPOCHS = 5
min_valid_loss = float('inf')
criterion = torch.nn.CrossEntropyLoss().to(device)
optimizer = torch.optim.SGD(model.parameters(), lr=4.0)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 1, gamma=0.9)
train_len = int(len(train_dataset) * 0.95)
sub_train_, sub_valid_ = \
random_split(train_dataset, [train_len, len(train_dataset) - train_len])
for epoch in range(N_EPOCHS):
start_time = time.time()
train_loss, train_acc = train_func(sub_train_)
valid_loss, valid_acc = test(sub_valid_)
secs = int(time.time() - start_time)
mins = secs / 60
secs = secs % 60
print('Epoch: %d' %(epoch + 1), " | time in %d minutes, %d seconds" %(mins, secs))
print(f'\tLoss: {train_loss:.4f}(train)\t|\tAcc: {train_acc * 100:.1f}%(train)')
print(f'\tLoss: {valid_loss:.4f}(valid)\t|\tAcc: {valid_acc * 100:.1f}%(valid)')
বাইরে:
Epoch: 1 | time in 0 minutes, 9 seconds
Loss: 0.0261(train) | Acc: 84.8%(train)
Loss: 0.0001(valid) | Acc: 90.3%(valid)
Epoch: 2 | time in 0 minutes, 9 seconds
Loss: 0.0119(train) | Acc: 93.7%(train)
Loss: 0.0002(valid) | Acc: 90.5%(valid)
Epoch: 3 | time in 0 minutes, 9 seconds
Loss: 0.0069(train) | Acc: 96.4%(train)
Loss: 0.0001(valid) | Acc: 89.8%(valid)
Epoch: 4 | time in 0 minutes, 8 seconds
Loss: 0.0039(train) | Acc: 98.1%(train)
Loss: 0.0002(valid) | Acc: 91.0%(valid)
Epoch: 5 | time in 0 minutes, 8 seconds
Loss: 0.0023(train) | Acc: 99.0%(train)
Loss: 0.0002(valid) | Acc: 90.9%(valid)
নিম্নলিখিত তথ্য সহ জিপিইউতে মডেল চালাচ্ছেন:
যুগ: 1 | সময় 0 মিনিট, 11 সেকেন্ডে
Loss: 0.0263(train) | Acc: 84.5%(train)
Loss: 0.0001(valid) | Acc: 89.0%(valid)
পর্ব: 2 | সময় 0 মিনিট, 10 সেকেন্ডে
Loss: 0.0119(train) | Acc: 93.6%(train)
Loss: 0.0000(valid) | Acc: 89.6%(valid)
পর্ব: 3 | সময় 0 মিনিট, 9 সেকেন্ডে
Loss: 0.0069(train) | Acc: 96.4%(train)
Loss: 0.0000(valid) | Acc: 90.5%(valid)
পর্ব: 4 | সময় 0 মিনিট, 11 সেকেন্ডে
Loss: 0.0038(train) | Acc: 98.2%(train)
Loss: 0.0000(valid) | Acc: 90.4%(valid)
পর্ব: 5 | সময় 0 মিনিট, 11 সেকেন্ডে
Loss: 0.0022(train) | Acc: 99.0%(train)
Loss: 0.0000(valid) | Acc: 91.0%(valid)
পরীক্ষার ডেটাসেট সহ মডেলটির মূল্যায়ন করুন
print('Checking the results of test dataset...')
test_loss, test_acc = test(test_dataset)
print(f'\tLoss: {test_loss:.4f}(test)\t|\tAcc: {test_acc * 100:.1f}%(test)')
বাইরে:
Checking the results of test dataset...
Loss: 0.0002(test) | Acc: 88.8%(test)
পরীক্ষার ডেটাসেটের ফলাফলগুলি পরীক্ষা করা হচ্ছে ...
Loss: 0.0237(test) | Acc: 90.5%(test)
একটি এলোমেলো খবরে পরীক্ষা
import re
from torchtext.data.utils import ngrams_iterator
from torchtext.data.utils import get_tokenizer
ag_news_label = {1 : "World",
2 : "Sports",
3 : "Business",
4 : "Sci/Tec"}
def predict(text, model, vocab, ngrams):
tokenizer = get_tokenizer("basic_english")
with torch.no_grad():
text = torch.tensor([vocab[token]
for token in ngrams_iterator(tokenizer(text), ngrams)])
output = model(text, torch.tensor([0]))
return output.argmax(1).item() + 1
ex_text_str = "MEMPHIS, Tenn. – Four days ago, Jon Rahm was \
enduring the season’s worst weather conditions on Sunday at The \
Open on his way to a closing 75 at Royal Portrush, which \
considering the wind and the rain was a respectable showing. \
Thursday’s first round at the WGC-FedEx St. Jude Invitational \
was another story. With temperatures in the mid-80s and hardly any \
wind, the Spaniard was 13 strokes better in a flawless round. \
Thanks to his best putting performance on the PGA Tour, Rahm \
finished with an 8-under 62 for a three-stroke lead, which \
was even more impressive considering he’d never played the \
front nine at TPC Southwind."
vocab = train_dataset.get_vocab()
model = model.to("cpu")
print("This is a %s news" %ag_news_label[predict(ex_text_str, model, vocab, 2)])
বাইরে:
This is a Sports news
এটি একটি স্পোর্টসের সংবাদ
স্ক্রিপ্টের মোট চলমান সময়: (1 মিনিট 29.876 সেকেন্ড)
0 comments:
Post a Comment