টিপ:
এই টিউটোরিয়ালটির বেশিরভাগ অংশ পেতে, আমরা এই Colab Version. কলাব সংস্করণটি ব্যবহার করার পরামর্শ দিই। এটি আপনাকে নীচে উপস্থাপিত তথ্যগুলির সাথে পরীক্ষার অনুমতি দেবে।
এই টিউটোরিয়ালটির জন্য, আমরা পথচারী সনাক্তকরণ এবং বিভাগকরণের জন্য পেন-ফুদান ডেটাবেসে একটি প্রাক প্রশিক্ষিত মাস্ক আর-সিএনএন মডেলটি ফাইনেনটুন করব । এতে পথচারীদের 345 দৃষ্টান্ত সহ 170 টি চিত্র রয়েছে এবং আমরা কাস্টম ডেটাসেটে উদাহরণ বিভাগে মডেলটি প্রশিক্ষণের জন্য টর্চভিশনে নতুন বৈশিষ্ট্যগুলি কীভাবে ব্যবহার করতে পারি তা বোঝাতে এটি ব্যবহার করব।
ডেটাসেটের সংজ্ঞা দেওয়া হচ্ছে
প্রশিক্ষণ অবজেক্ট সনাক্তকরণ, উদাহরণ বিভাগকরণ এবং ব্যক্তি কীপয়েন্ট সনাক্তকরণের জন্য রেফারেন্স স্ক্রিপ্টগুলি সহজেই নতুন কাস্টম ডেটাসেট যুক্ত করার পক্ষে সমর্থন করে। ডেটাসেটটি স্ট্যান্ডার্ড
torch.utils.data.Datasetক্লাস থেকে উত্তরাধিকারী হওয়া উচিত , এবং প্রয়োগ করা __len__এবং __getitem__।
আমাদের কেবলমাত্র যা প্রয়োজন তা হ'ল ডেটাসেটটি
__getitem__ ফিরে আসা উচিত:- চিত্র: একটি পিআইএল আকারের চিত্র
(H, W) - লক্ষ্য: একটি ক্ষেত্র যা নিম্নলিখিত ক্ষেত্রগুলি সহ
boxes (FloatTensor[N, 4]): এর স্থানাঙ্কNমধ্যে সীমান্ত বাক্সে ফরম্যাট, ছোটো থেকে থেকে এবং থেকে[x0, y0, x1, y1]0W0Hlabels (Int64Tensor[N]): প্রতিটি বাউন্ডিং বাক্সের জন্য লেবেলimage_id (Int64Tensor[1]): একটি চিত্র শনাক্তকারী এটি ডেটাসেটের সমস্ত চিত্রের মধ্যে স্বতন্ত্র হওয়া উচিত এবং মূল্যায়নের সময় এটি ব্যবহৃত হয়area (Tensor[N]): সীমানা বাক্সের ক্ষেত্রফল। এটি কোকো মেট্রিকের সাথে মূল্যায়নের সময় ব্যবহৃত হয়, ছোট, মাঝারি এবং বড় বাক্সগুলির মধ্যে মেট্রিক স্কোর আলাদা করতে।iscrowd (UInt8Tensor[N]): ইস্ক্রোড সহ উদাহরণগুলি = সত্যায়ণ মূল্যায়নের সময় অগ্রাহ্য করা হবে।- ( allyচ্ছিকভাবে ) : অবজেক্টগুলির প্রত্যেকের জন্য সেগমেন্টেশন মাস্ক
masks (UInt8Tensor[N, H, W]) - ( allyচ্ছিকভাবে ) : এন প্রতিটি বস্তুর জন্য এটিতে বিন্যাসে কে কীপয়েন্ট রয়েছে । দৃশ্যমানতা = 0 এর অর্থ কী কীপয়েন্টটি দৃশ্যমান নয়। নোট করুন যে ডেটা বর্ধনের জন্য, কী-পয়েন্টকে উল্টানোর ধারণাটি ডেটা উপস্থাপনার উপর নির্ভর করে এবং আপনার নতুন কীপয়েন্ট উপস্থাপনার জন্য সম্ভবত আপনার মানিয়ে নেওয়া উচিত
keypoints (FloatTensor[N, K, 3])[x, y, visibility]references/detection/transforms.py
যদি আপনার মডেল উপরের পদ্ধতিগুলি ফেরত দেয় তবে তারা এগুলি প্রশিক্ষণ এবং মূল্যায়ণ উভয়ের জন্যই কাজ করবে এবং এখান থেকে মূল্যায়ন স্ক্রিপ্টগুলি ব্যবহার করবে
pycocotools।
অধিকন্তু, আপনি যদি প্রশিক্ষণের সময় অ্যাসপেক্ট রেশিও গোষ্ঠীকরণ ব্যবহার করতে চান (যাতে প্রতিটি ব্যাচে কেবল একই ধরণের অনুপাত সহ চিত্র থাকে) তবে এটি এমন একটি
get_height_and_width পদ্ধতিও প্রয়োগ করার পরামর্শ দেওয়া হয় যা চিত্রের উচ্চতা এবং প্রস্থকে ফিরিয়ে দেয়। যদি এই পদ্ধতিটি সরবরাহ না করা হয়, তবে আমরা ডেটাসেটের মাধ্যমে সমস্ত উপাদানকে জিজ্ঞাসা করি __getitem__, যা মেমরিটিতে চিত্রটি লোড করে এবং একটি কাস্টম পদ্ধতি সরবরাহ করা হলে তার চেয়ে ধীর হয়।Penn Fudan এর জন্য একটি কাস্টম ডেটাসেট রচনা
পেনফুডান ডেটাসেটের জন্য একটি ডেটাসেট লিখি। জিপ ফাইলটি ডাউনলোড এবং বের করার পরে , আমাদের নীচের ফোল্ডারটির কাঠামো রয়েছে:
PennFudanPed/PedMasks/FudanPed00001_mask.pngFudanPed00002_mask.pngFudanPed00003_mask.pngFudanPed00004_mask.png...PNGImages/FudanPed00001.pngFudanPed00002.pngFudanPed00003.pngFudanPed00004.png
Here is one example of a pair of images and segmentation masks
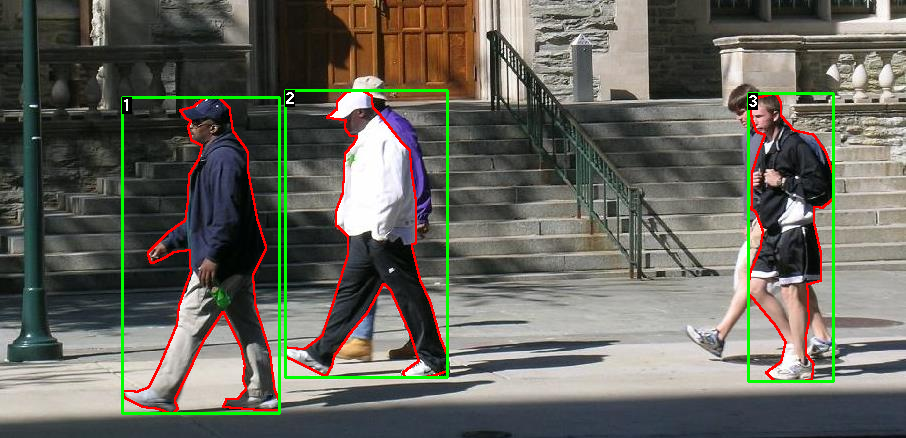
সুতরাং প্রতিটি চিত্রের একটি পৃথক বিভাগের মুখোশ রয়েছে, যেখানে প্রতিটি রঙের একটি ভিন্ন উদাহরণের সাথে মিল রয়েছে।
torch.utils.data.Datasetএই ডেটাসেটের জন্য একটি ক্লাস লিখি ।import os
import numpy as np
import torch
from PIL import Image
class PennFudanDataset(object):
def __init__(self, root, transforms):
self.root = root
self.transforms = transforms
# load all image files, sorting them to
# ensure that they are aligned
self.imgs = list(sorted(os.listdir(os.path.join(root, "PNGImages"))))
self.masks = list(sorted(os.listdir(os.path.join(root, "PedMasks"))))
def __getitem__(self, idx):
# load images ad masks
img_path = os.path.join(self.root, "PNGImages", self.imgs[idx])
mask_path = os.path.join(self.root, "PedMasks", self.masks[idx])
img = Image.open(img_path).convert("RGB")
# note that we haven't converted the mask to RGB,
# because each color corresponds to a different instance
# with 0 being background
mask = Image.open(mask_path)
# convert the PIL Image into a numpy array
mask = np.array(mask)
# instances are encoded as different colors
obj_ids = np.unique(mask)
# first id is the background, so remove it
obj_ids = obj_ids[1:]
# split the color-encoded mask into a set
# of binary masks
masks = mask == obj_ids[:, None, None]
# get bounding box coordinates for each mask
num_objs = len(obj_ids)
boxes = []
for i in range(num_objs):
pos = np.where(masks[i])
xmin = np.min(pos[1])
xmax = np.max(pos[1])
ymin = np.min(pos[0])
ymax = np.max(pos[0])
boxes.append([xmin, ymin, xmax, ymax])
# convert everything into a torch.Tensor
boxes = torch.as_tensor(boxes, dtype=torch.float32)
# there is only one class
labels = torch.ones((num_objs,), dtype=torch.int64)
masks = torch.as_tensor(masks, dtype=torch.uint8)
image_id = torch.tensor([idx])
area = (boxes[:, 3] - boxes[:, 1]) * (boxes[:, 2] - boxes[:, 0])
# suppose all instances are not crowd
iscrowd = torch.zeros((num_objs,), dtype=torch.int64)
target = {}
target["boxes"] = boxes
target["labels"] = labels
target["masks"] = masks
target["image_id"] = image_id
target["area"] = area
target["iscrowd"] = iscrowd
if self.transforms is not None:
img, target = self.transforms(img, target)
return img, target
def __len__(self):
return len(self.imgs)
Now let's define a model that can perform predictions on this dataset. এটিই ডেটাসেটের জন্য। এখন আসুন এমন একটি মডেল নির্ধারণ করুন যা এই ডেটাসেটে পূর্বাভাস দিতে পারে।
আপনার মডেল সংজ্ঞায়িত
এই টিউটোরিয়ালে, আমরা মাস্ক আর-সিএনএন ব্যবহার করব যা দ্রুত আর-সিএনএন শীর্ষে ভিত্তি করে । দ্রুত আর-সিএনএন এমন একটি মডেল যা চিত্রের সম্ভাব্য বস্তুর জন্য বাউন্ডিং বাক্স এবং শ্রেণি স্কোর উভয়েরই পূর্বাভাস দেয়।
মাস্ক আর-সিএনএন দ্রুত আর-সিএনএন-তে একটি অতিরিক্ত শাখা যুক্ত করে, যা প্রতিটি উদাহরণের জন্য বিভাজন মুখোশগুলির পূর্বাভাস দেয়।
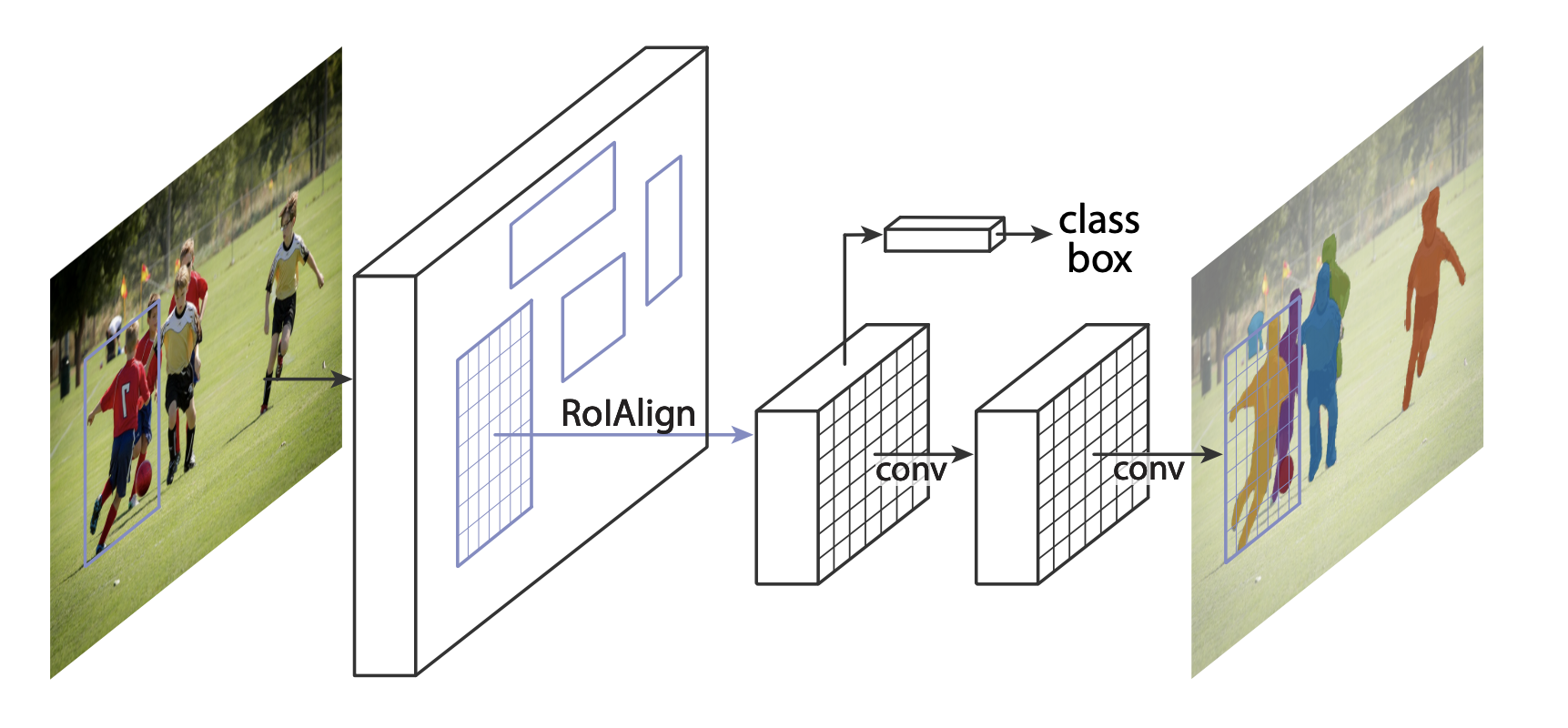
দুটি সাধারণ পরিস্থিতি রয়েছে যেখানে টর্চভিশন মডেলজুতে উপলব্ধ যে কোনও একটি মডেল পরিবর্তন করতে পারে one প্রথমটি হ'ল আমরা যখন প্রাক-প্রশিক্ষিত মডেলটি থেকে শুরু করতে চাই এবং কেবল শেষ স্তরটি ফিনিটিউন করি। অন্যটি হ'ল আমরা যখন মডেলের ব্যাক হোনটিকে একটি আলাদা দিয়ে প্রতিস্থাপন করতে চাই (দ্রুত ভবিষ্যদ্বাণীগুলির জন্য, উদাহরণস্বরূপ)।
আসুন দেখুন নীচের বিভাগগুলিতে আমরা কীভাবে এক বা অন্যটি করব।
1 - একটি পূর্বনির্ধারিত মডেল থেকে ফিনেটুনিং
ধরা যাক আপনি COCO- এ প্রাক প্রশিক্ষিত কোনও মডেল থেকে শুরু করতে চান এবং এটি আপনার নির্দিষ্ট ক্লাসের জন্য ফাইনেশন করতে চান। এটি করার একটি সম্ভাব্য উপায় এখানে:
import torchvision
from torchvision.models.detection.faster_rcnn import FastRCNNPredictor
# load a model pre-trained pre-trained on COCO
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=True)
# replace the classifier with a new one, that has
# num_classes which is user-defined
num_classes = 2 # 1 class (person) + background
# get number of input features for the classifier
in_features = model.roi_heads.box_predictor.cls_score.in_features
# replace the pre-trained head with a new one
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)
2 - একটি ভিন্ন ব্যাকবোন যুক্ত করতে মডেলটি সংশোধন করা
import torchvision
from torchvision.models.detection import FasterRCNN
from torchvision.models.detection.rpn import AnchorGenerator
# load a pre-trained model for classification and return
# only the features
backbone = torchvision.models.mobilenet_v2(pretrained=True).features
# FasterRCNN needs to know the number of
# output channels in a backbone. For mobilenet_v2, it's 1280
# so we need to add it here
backbone.out_channels = 1280
# let's make the RPN generate 5 x 3 anchors per spatial
# location, with 5 different sizes and 3 different aspect
# ratios. We have a Tuple[Tuple[int]] because each feature
# map could potentially have different sizes and
# aspect ratios
anchor_generator = AnchorGenerator(sizes=((32, 64, 128, 256, 512),),
aspect_ratios=((0.5, 1.0, 2.0),))
# let's define what are the feature maps that we will
# use to perform the region of interest cropping, as well as
# the size of the crop after rescaling.
# if your backbone returns a Tensor, featmap_names is expected to
# be [0]. More generally, the backbone should return an
# OrderedDict[Tensor], and in featmap_names you can choose which
# feature maps to use.
roi_pooler = torchvision.ops.MultiScaleRoIAlign(featmap_names=[0],
output_size=7,
sampling_ratio=2)
# put the pieces together inside a FasterRCNN model
model = FasterRCNN(backbone,
num_classes=2,
rpn_anchor_generator=anchor_generator,
box_roi_pool=roi_pooler)
PennFudan ডেটাসেটের জন্য একটি ইনস্ট্যান্স সেগমেন্টেশন মডেল
আমাদের ক্ষেত্রে, আমরা আমাদের প্রাক-প্রশিক্ষিত মডেলটির সূক্ষ্ম-টিউন করতে চাই, আমাদের ডেটাসেটটি খুব কম, তাই আমরা ১ নম্বর পদ্ধতির অনুসরণ করব।
এখানে আমরা উদাহরণ বিভাজন মাস্কগুলিও গণনা করতে চাই, সুতরাং আমরা মাস্ক আর-সিএনএন ব্যবহার করব:
import torchvision
from torchvision.models.detection.faster_rcnn import FastRCNNPredictor
from torchvision.models.detection.mask_rcnn import MaskRCNNPredictor
def get_model_instance_segmentation(num_classes):
# load an instance segmentation model pre-trained pre-trained on COCO
model = torchvision.models.detection.maskrcnn_resnet50_fpn(pretrained=True)
# get number of input features for the classifier
in_features = model.roi_heads.box_predictor.cls_score.in_features
# replace the pre-trained head with a new one
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)
# now get the number of input features for the mask classifier
in_features_mask = model.roi_heads.mask_predictor.conv5_mask.in_channels
hidden_layer = 256
# and replace the mask predictor with a new one
model.roi_heads.mask_predictor = MaskRCNNPredictor(in_features_mask,
hidden_layer,
num_classes)
return model
এটি
modelহ'ল এটি আপনার কাস্টম ডেটাসেটে প্রশিক্ষিত এবং মূল্যায়ন করার জন্য প্রস্তুত হবে।Putting everything togetherএকসাথে সব কিছু রাখা
ইন
references/detection/, সনাক্তকরণের মডেলগুলি প্রশিক্ষণ ও মূল্যায়ন সহজ করার জন্য আমাদের কাছে বেশ কয়েকটি সহায়ক ফাংশন রয়েছে। এখানে, আমরা ব্যবহার করব references/detection/engine.py, references/detection/utils.py এবং references/detection/transforms.py। এগুলি কেবল আপনার ফোল্ডারে অনুলিপি করুন এবং সেগুলি এখানে ব্যবহার করুন।
ডেটা বৃদ্ধি / রূপান্তরকরণের জন্য কিছু সহায়ক ফাংশন লিখি:
import transforms as T
def get_transform(train):
transforms = []
transforms.append(T.ToTensor())
if train:
transforms.append(T.RandomHorizontalFlip(0.5))
return T.Compose(transforms)
আসুন এখন মূল ফাংশনটি লিখি যা প্রশিক্ষণ এবং বৈধতা সম্পাদন করে:
from engine import train_one_epoch, evaluate
import utils
def main():
# train on the GPU or on the CPU, if a GPU is not available
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
# our dataset has two classes only - background and person
num_classes = 2
# use our dataset and defined transformations
dataset = PennFudanDataset('PennFudanPed', get_transform(train=True))
dataset_test = PennFudanDataset('PennFudanPed', get_transform(train=False))
# split the dataset in train and test set
indices = torch.randperm(len(dataset)).tolist()
dataset = torch.utils.data.Subset(dataset, indices[:-50])
dataset_test = torch.utils.data.Subset(dataset_test, indices[-50:])
# define training and validation data loaders
data_loader = torch.utils.data.DataLoader(
dataset, batch_size=2, shuffle=True, num_workers=4,
collate_fn=utils.collate_fn)
data_loader_test = torch.utils.data.DataLoader(
dataset_test, batch_size=1, shuffle=False, num_workers=4,
collate_fn=utils.collate_fn)
# get the model using our helper function
model = get_model_instance_segmentation(num_classes)
# move model to the right device
model.to(device)
# construct an optimizer
params = [p for p in model.parameters() if p.requires_grad]
optimizer = torch.optim.SGD(params, lr=0.005,
momentum=0.9, weight_decay=0.0005)
# and a learning rate scheduler
lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer,
step_size=3,
gamma=0.1)
# let's train it for 10 epochs
num_epochs = 10
for epoch in range(num_epochs):
# train for one epoch, printing every 10 iterations
train_one_epoch(model, optimizer, data_loader, device, epoch, print_freq=10)
# update the learning rate
lr_scheduler.step()
# evaluate on the test dataset
evaluate(model, data_loader_test, device=device)
print("That's it!")
You should get as output for the first epoch:
Epoch: [0] [ 0/60] eta: 0:01:18 lr: 0.000090 loss: 2.5213 (2.5213) loss_classifier: 0.8025 (0.8025) loss_box_reg: 0.2634 (0.2634) loss_mask: 1.4265 (1.4265) loss_objectness: 0.0190 (0.0190) loss_rpn_box_reg: 0.0099 (0.0099) time: 1.3121 data: 0.3024 max mem: 3485
Epoch: [0] [10/60] eta: 0:00:20 lr: 0.000936 loss: 1.3007 (1.5313) loss_classifier: 0.3979 (0.4719) loss_box_reg: 0.2454 (0.2272) loss_mask: 0.6089 (0.7953) loss_objectness: 0.0197 (0.0228) loss_rpn_box_reg: 0.0121 (0.0141) time: 0.4198 data: 0.0298 max mem: 5081
Epoch: [0] [20/60] eta: 0:00:15 lr: 0.001783 loss: 0.7567 (1.1056) loss_classifier: 0.2221 (0.3319) loss_box_reg: 0.2002 (0.2106) loss_mask: 0.2904 (0.5332) loss_objectness: 0.0146 (0.0176) loss_rpn_box_reg: 0.0094 (0.0123) time: 0.3293 data: 0.0035 max mem: 5081
Epoch: [0] [30/60] eta: 0:00:11 lr: 0.002629 loss: 0.4705 (0.8935) loss_classifier: 0.0991 (0.2517) loss_box_reg: 0.1578 (0.1957) loss_mask: 0.1970 (0.4204) loss_objectness: 0.0061 (0.0140) loss_rpn_box_reg: 0.0075 (0.0118) time: 0.3403 data: 0.0044 max mem: 5081
Epoch: [0] [40/60] eta: 0:00:07 lr: 0.003476 loss: 0.3901 (0.7568) loss_classifier: 0.0648 (0.2022) loss_box_reg: 0.1207 (0.1736) loss_mask: 0.1705 (0.3585) loss_objectness: 0.0018 (0.0113) loss_rpn_box_reg: 0.0075 (0.0112) time: 0.3407 data: 0.0044 max mem: 5081
Epoch: [0] [50/60] eta: 0:00:03 lr: 0.004323 loss: 0.3237 (0.6703) loss_classifier: 0.0474 (0.1731) loss_box_reg: 0.1109 (0.1561) loss_mask: 0.1658 (0.3201) loss_objectness: 0.0015 (0.0093) loss_rpn_box_reg: 0.0093 (0.0116) time: 0.3379 data: 0.0043 max mem: 5081
Epoch: [0] [59/60] eta: 0:00:00 lr: 0.005000 loss: 0.2540 (0.6082) loss_classifier: 0.0309 (0.1526) loss_box_reg: 0.0463 (0.1405) loss_mask: 0.1568 (0.2945) loss_objectness: 0.0012 (0.0083) loss_rpn_box_reg: 0.0093 (0.0123) time: 0.3489 data: 0.0042 max mem: 5081
Epoch: [0] Total time: 0:00:21 (0.3570 s / it)
creating index...
index created!
Test: [ 0/50] eta: 0:00:19 model_time: 0.2152 (0.2152) evaluator_time: 0.0133 (0.0133) time: 0.4000 data: 0.1701 max mem: 5081
Test: [49/50] eta: 0:00:00 model_time: 0.0628 (0.0687) evaluator_time: 0.0039 (0.0064) time: 0.0735 data: 0.0022 max mem: 5081
Test: Total time: 0:00:04 (0.0828 s / it)
Averaged stats: model_time: 0.0628 (0.0687) evaluator_time: 0.0039 (0.0064)
Accumulating evaluation results...
DONE (t=0.01s).
Accumulating evaluation results...
DONE (t=0.01s).
IoU metric: bbox
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.606
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.984
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.780
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.313
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.582
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.612
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.270
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.672
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.672
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.650
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.755
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.664
IoU metric: segm
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.704
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.979
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.871
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.325
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.488
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.727
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.316
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.748
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.749
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.650
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.673
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.758
সুতরাং এক যুগের প্রশিক্ষণের পরে, আমরা একটি কোকো-স্টাইলের এমএপি 60০.। এবং একটি মুখোশ এমএপি 70০.৪ পাই।
10 যুগের প্রশিক্ষণের পরে, আমি নিম্নলিখিত মেট্রিকগুলি পেয়েছি
IoU metric: bbox
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.799
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.969
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.935
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.349
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.592
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.831
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.324
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.844
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.844
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.400
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.777
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.870
IoU metric: segm
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.761
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.969
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.919
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.341
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.464
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.788
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.303
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.799
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.799
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.400
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.769
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.818
তবে ভবিষ্যদ্বাণীগুলি দেখতে কেমন? ডেটাসেটে একটি চিত্র নিয়ে আসুন এবং যাচাই করি

প্রশিক্ষিত মডেল এই চিত্রটিতে 9 জন ব্যক্তির নজির পূর্বাভাস দিয়েছে, আসুন তাদের কয়েকটি দেখি:


ফলাফলগুলি বেশ ভাল দেখাচ্ছে!
Wrapping upমোড়ক উম্মচন
এই টিউটোরিয়ালে, আপনি শিখেছেন কীভাবে নিজস্ব কাস্টম ডেটাশেটে বিভাগ বিভাগগুলির মডেলগুলির জন্য নিজস্ব প্রশিক্ষণ পাইপলাইন তৈরি করতে হয়। তার জন্য, আপনি একটি
torch.utils.data.Datasetক্লাস লিখেছিলেন যা চিত্রগুলি এবং গ্রাউন্ড ট্রুথ বাক্স এবং বিভাগগুলির মুখোশগুলি দেয় returns আপনি এই নতুন ডেটাসেটে ট্রান্সফার লার্নিং সঞ্চালনের জন্য আপনি একটি মাস্ক আর-সিএনএন মডেলকে আগেও প্রশিক্ষিত COCO ট্রেন2017 তেও কাজে লাগিয়েছেন।
আরও সম্পূর্ণ উদাহরণের জন্য, যার মধ্যে মাল্টি-মেশিন / মাল্টি-জিপিইউ প্রশিক্ষণ রয়েছে, যাচাই করুন
references/detection/train.py, যা টর্চভিশন রেপোতে উপস্থিত রয়েছে।
0 comments:
Post a Comment