গত দশক ধরে মেশিন লার্নিংয়ের আগ্রহ আগ্রহের মধ্যে পড়েছে। আপনি কম্পিউটার বিজ্ঞান প্রোগ্রাম, শিল্প সম্মেলন, এবং ওয়াল স্ট্রিট জার্নাল প্রায় প্রতিদিন দৈনিক মেশিন লার্নিং দেখতে। মেশিন লার্নিং সম্পর্কে সমস্ত কথাবার্তার জন্য, অনেকেই যা করতে পারে তা নিয়ে এটি কী করতে পারে তা স্বীকার করে। মূলত, মেশিন লার্নিং কাঁচা তথ্য থেকে তথ্য আহরণের এবং কিছু ধরণের মডেলের প্রতিনিধিত্ব করার জন্য অ্যালগরিদমগুলি ব্যবহার করছে। আমরা এখনও মডেল করা না যে অন্যান্য তথ্য সম্পর্কে জিনিস নির্ণয় করার জন্য আমরা এই মডেল ব্যবহার। স্নায়ু নেটওয়ার্ক মেশিন লার্নিং জন্য মডেল এক ধরনের; তারা অন্তত 50 বছর ধরে প্রায় হয়েছে। একটি নিউরাল নেটওয়ার্ক মৌলিক ইউনিট একটি নোড, যা ধীরে ধীরে স্তন্যপায়ী মস্তিষ্কের জৈব নিউরন উপর ভিত্তি করে। নিউরনের সংযোগগুলিও জৈবিক মস্তিষ্কের উপর ভিত্তি করে তৈরি করা হয়, যেমনভাবে এই সংযোগগুলি সময়ের সাথে সাথে বিকশিত হয় ("প্রশিক্ষণ" সহ)। 1980 এর দশকের মাঝামাঝি এবং 1990 এর দশকের প্রথম দিকে, নিউরোল নেটওয়ার্কের মধ্যে অনেক গুরুত্বপূর্ণ স্থাপত্যের উন্নতি ঘটে। যাইহোক, ভাল ফলাফল পেতে সময় এবং ডেটা পরিমাণ পরিমাণ গ্রহণ হ্রাস, এবং এইভাবে সুদ ঠান্ডা। 2000 এর দশকের প্রথম দিকে, কম্পিউটেশাল শক্তি দ্রুতগতিতে বিস্তৃত হয়েছিল এবং শিল্পটি কম্পিউটেশনাল কৌশলগুলির একটি "ক্যামব্রিয়ান বিস্ফোরণ" দেখেছিল যা পূর্বে এটি সম্ভব ছিল না। গভীর দশকটি সেই দশকের বিস্ফোরক কম্পিউটেশনাল বৃদ্ধি থেকে মাঠে গুরুতর প্রতিযোগী হিসাবে আবির্ভূত হয়েছিল, অনেক গুরুত্বপূর্ণ মেশিন লার্নিং প্রতিযোগিতা জিতেছিল। ২017 সাল হিসাবে সুদ কমেছে না; আজ, আমরা মেশিন লার্নিং এর প্রতিটি কোণে উল্লেখ গভীর শিক্ষা শেখা।
নিজেকে উন্মাদ করার জন্য, আমি উদাসিটির "গভীর শিক্ষার" কোর্সটি গ্রহণ করি, যা গভীর শিক্ষার প্রেরণা এবং বুদ্ধিমান সিস্টেমগুলির ডিজাইনের একটি দুর্দান্ত ভূমিকা যা টেন্সরফ্লোতে জটিল এবং / অথবা বড় আকারের ডেটাসেট থেকে শিখতে পারে। ক্লাস প্রোজেক্টগুলির জন্য, আমি ক্রভোলিউশনের সাথে ছবির স্বীকৃতির জন্য স্নায়ু নেটওয়ার্কগুলি ব্যবহার করেছি এবং রিক্রুेंट নিউরাল নেটওয়ার্ক / লং শর্ট-টার্ম মেমরির সাথে এম্বেডিং এবং চরিত্র ভিত্তিক পাঠ্য প্রজন্মের সাথে প্রাকৃতিক ভাষা প্রক্রিয়াকরণের জন্য উন্নত করেছি। বুধবার নোটবুকের সমস্ত কোড এই গিটহাব রেপোজিটরিতে পাওয়া যাবে।
এখানে অ্যাসাইনমেন্টগুলির একটি ফলাফল, শব্দ ভেক্টরগুলির একটি টি-এসএনই অভিক্ষেপ, অনুরূপতা দ্বারা ক্লাস্টার।

এখানে এমন অনেক প্রকাশনা রয়েছে যা ক্ষেত্রের বিকাশে অতিশয় প্রভাবশালী হয়েছে:
- Gradient-Based Learning Applied to Document Recognition এনওয়াইইউর গ্রেডিয়েন্ট-ভিত্তিক লার্নিং অ্যাপলড টু ডকুমেন্ট রিকোনিশন (1998), যা কনভোলিউশনাল নিউরাল নেটওয়ার্ককে মেশিন লার্নিং ওয়ার্ল্ডের সাথে উপস্থাপন করে।
- Deep Boltzmann Machines (2009),টরন্টো এর ডিপ বোল্টজমান মেশিন (২009), যা বল্টজমান মেশিনগুলির জন্য একটি নতুন লার্নিং অ্যালগরিদম উপস্থাপন করে যা লুকানো ভেরিয়েবলের অনেক স্তর ধারণ করে।
- স্ট্যানফোর্ড এবং গুগল এর Building High-Level Features Using Large-Scale Unsupervised Learning (2012),বিল্ডিং উচ্চ-স্তরীয় বৈশিষ্ট্যগুলি লার্জ-স্কেলে অ-সুপারভাইজড লার্নিং (2012) ব্যবহার করে, যা কেবলমাত্র ল্যাবলেটেড ডেটা থেকে উচ্চ-স্তর, শ্রেণি-নির্দিষ্ট বৈশিষ্ট্য ডিটেক্টর নির্মাণের সমস্যাটি মোকাবেলা করে।
- DeCAF — A Deep Convolutional Activation Feature for Generic Visual Recognition (2013)বার্কলে এর ডিসিএএফ - জেনেরিক ভিজুয়াল রেকগনিশন (2013) এর একটি ডিপ কনভোলিউশনাল অ্যাক্টিভেশন ফিচার, যা ডিসিসিএএফকে প্রকাশ করে, যা গভীর সংশ্লেষিক অ্যাক্টিভেশন বৈশিষ্ট্যগুলির একটি মুক্ত-উত্স বাস্তবায়ন প্রকাশ করে, সমস্ত সংশ্লিষ্ট নেটওয়ার্ক পরামিতি সহ দৃষ্টি গবেষকরা গভীরভাবে পরীক্ষা পরিচালনা করতে সক্ষম হবেন চাক্ষুষ ধারণা শেখার paradigms একটি পরিসীমা জুড়ে উপস্থাপনা।
- Deepmind's Playing Atari with Deep Enforcement Learning (2016), যা শক্তিশালীকরণ নীতি শেখার মাধ্যমে সরাসরি উচ্চ-মাত্রিক সংজ্ঞাবহ ইনপুট থেকে সরাসরি নিয়ন্ত্রণ নীতিগুলি শিখতে 1 ম গভীর শিক্ষণ মডেল উপস্থাপন করে।
গভীর শিক্ষা সম্পর্কে প্রচুর জ্ঞানের প্রচুর পরিমাণে আমি গবেষণা এবং শেখার মাধ্যমে শিখেছি। এখানে আমি 10 শক্তিশালী গভীর শিক্ষার পদ্ধতি শেয়ার করতে চাই, এআই ইঞ্জিনিয়াররা তাদের মেশিন লার্নিং সমস্যার জন্য আবেদন করতে পারেন। কিন্তু সর্বোপরি, আসুন গভীর শিক্ষার সংজ্ঞা দিন। গভীর শেখার অনেকের জন্য সংজ্ঞা দেওয়ার একটি চ্যালেঞ্জ হয়েছে কারণ এটি গত দশকে ধীরে ধীরে রূপগুলিকে পরিবর্তিত করেছে। দৃষ্টিকোণ থেকে গভীরভাবে শেখার জন্য, নীচের চিত্রটি এআই, মেশিন লার্নিং এবং গভীর শিক্ষার সম্পর্কের ধারণা ধারণ করে।
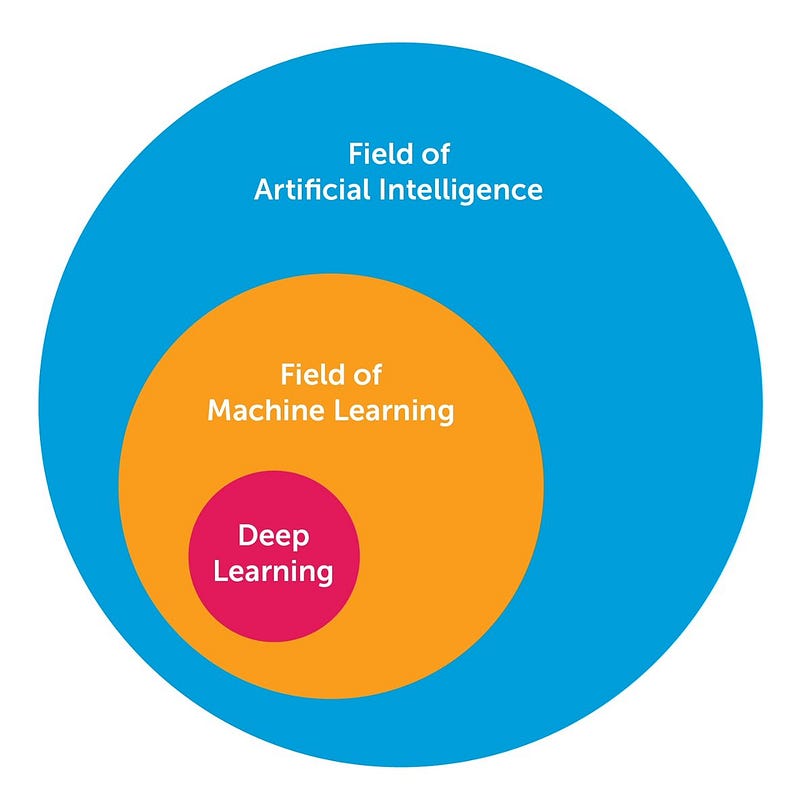
AI এর ক্ষেত্র বিস্তৃত এবং দীর্ঘ সময়ের জন্য প্রায় হয়েছে। গভীর শেখার মেশিন শেখার ক্ষেত্রের একটি উপসেট, যা এআই এর একটি উপপরিচালক। "“canonical”আনুশাসনিকক্যানোনিকাল" ফিড ফরওয়ার্ড মাল্টিলেয়ার নেটওয়ার্কগুলি থেকে সাধারণভাবে গভীর শিক্ষার নেটওয়ার্কগুলিকে আলাদা করে এমন দিকগুলি নিম্নরূপ:
- More neurons than previous networks
- More complex ways of connecting layers
- “Cambrian explosion” of computing power to train
- Automatic feature extraction
ডিপ লার্নিং তারপর চার মৌলিক নেটওয়ার্ক আর্কিটেকচারে একাধিক পরামিতি এবং স্তর সহ নিউরাল নেটওয়ার্ক হিসাবে সংজ্ঞায়িত করা যেতে পারে:
- Unsupervised Pre-trained Networks
- Convolutional Neural Networks
- Recurrent Neural Networks
- Recursive Neural Networks
1 — Back-Propagation
1 - ব্যাক-প্রচার ব্যাক-প্রপ কেবল একটি ফাংশনের আংশিক ডেরাইভেটিভস (বা গ্রেডিয়েন্ট) গণনা করার একটি পদ্ধতি যা একটি ফাংশন রচনা (যেমন নিউরাল নেটগুলিতে) হিসাবে ফর্ম রয়েছে। যখন আপনি একটি গ্রেডিয়েন্ট-ভিত্তিক পদ্ধতি ব্যবহার করে একটি অপ্টিমাইজেশান সমস্যা সমাধান করেন (গ্রেডিয়েন্ট বংশবৃদ্ধি কেবল তাদের মধ্যে একটি), আপনি প্রতিটি পুনরাবৃত্তি এ ফাংশন গ্রেডিয়েন্ট গণনা করতে চান।
একটি নিউরাল নেট জন্য, উদ্দেশ্য ফাংশন একটি গঠন ফর্ম আছে। আপনি কিভাবে গ্রেডিয়েন্ট গণনা করবেন? এটি করার 2 টি সাধারণ উপায় রয়েছে: (i) বিশ্লেষণাত্মক বৈষম্য। আপনি ফাংশন ফর্ম জানেন। আপনি শুধু শৃঙ্খল নিয়ম (মৌলিক ক্যালকুলাস) ব্যবহার করে ডেরিভেটিভ গণনা। (ii) সীমাবদ্ধ পার্থক্য ব্যবহার করে আনুমানিক পার্থক্য। এই পদ্ধতিটি তুলনামূলকভাবে ব্যয়বহুল কারণ ফাংশন মূল্যায়ন সংখ্যা O (N), যেখানে N পরামিতির সংখ্যা। এটি বিশ্লেষণমূলক বৈষম্যের তুলনায় ব্যয়বহুল। ডিজিগিংয়ের সময় ফিনিট পার্থক্য, তবে, সাধারণত একটি ব্যাক-প্রোট বাস্তবায়ন যাচাই করতে ব্যবহৃত হয়।
2 — Stochastic Gradient DescentStochastic গ্রেডিয়েন্ট বংশবৃদ্ধি
গ্রেডিয়েন্ট বংশের কথা মনে করার একটি স্বজ্ঞাত উপায় হল পাহাড়ের উপরে থেকে উৎপন্ন একটি নদীর পথ কল্পনা করা। গ্রেডিয়েন্ট বংশের লক্ষ্যটি ঠিক যেটি নদীটি অর্জনের চেষ্টা করে - অর্থাত্, পর্বত থেকে নিচে আরোহণ করে নিচের দিকে (পাদদেশে) নীচে পৌঁছান। এখন, যদি পাহাড়ের ভূখণ্ডটি এমনভাবে আকার ধারণ করা হয় যে তার চূড়ান্ত গন্তব্যে পৌঁছানোর আগে নদীটি সম্পূর্ণরূপে কোথাও থামাতে হবে না (যা পাদদেশে সর্বনিম্ন পয়েন্ট, তবে এটি আদর্শ আদর্শ যা আমরা চাই)। মেশিন লার্নিং এ, এই পরিমাণে বলার অপেক্ষা রাখে না যে, আমরা প্রাথমিক বিন্দু (পাহাড়ের উপরে) থেকে শুরু হওয়া সমাধানটির বিশ্বব্যাপী সর্বাধিক (বা সর্বোত্তম) খুঁজে পেয়েছি। তবে, এটি হতে পারে যে ভূখণ্ডের প্রকৃতিটি পথের কয়েকটি পট নদী যা ফাঁদে আটকাতে পারে এবং স্থগিত হতে পারে। মেশিন লার্নিং পদগুলিতে, এই পটগুলিকে স্থানীয় মিনিমা সমাধান হিসাবে অভিহিত করা হয়, যা অনুকূল নয়। এর বাইরে যাওয়ার উপায়গুলি রয়েছে (যা আমি নই আলোচনা)।তাই Gradient Descentগ্র্যাডিয়েন্ট ডিসেন্ট স্থানীয় অঞ্চলে প্রকৃতির উপর নির্ভর করে (অথবা এমএল পদগুলিতে ফাংশন) নির্ভর করে। কিন্তু, যখন আপনার একটি বিশেষ ধরনের পর্বত ভূখণ্ড থাকে (যা একটি বাটি মত আকারে হয়, এমএল পদগুলিতে এটি একটি কনভেক্স ফাংশন বলা হয়), অ্যালগরিদম সর্বদা সর্বোত্তম খুঁজতে গ্যারান্টিযুক্ত। আপনি আবার একটি নদী অঙ্কন এই কল্পনা করতে পারেন। এই ধরনের বিশেষ ভূখণ্ড (A.K.A. convex ফাংশন) সবসময় এমএল অপ্টিমাইজেশান জন্য একটি আশীর্বাদ। এছাড়াও, পর্বতের শীর্ষস্থানে যেখানে আপনি প্রাথমিক সূচনা (অর্থাৎ ফাংশনের প্রাথমিক মান) থেকে শুরু করে তার উপর নির্ভর করে, আপনি একটি ভিন্ন পথ অনুসরণ করতে পারেন। একইভাবে, নদীর গতির গতির উপর নির্ভর করে (অর্থাৎ শিক্ষানবিস হার বা গ্রেডিয়েন্ট বংশের অ্যালগরিদমের ধাপের আকার), আপনি অন্যভাবে চূড়ান্ত গন্তব্যে পৌঁছাতে পারেন। এই উভয় মানদণ্ড আপনি একটি পিট (স্থানীয় minima) মধ্যে পড়ে কিনা তা প্রভাবিত করতে পারেন বা এড়াতে পারবেন।
3 — Learning Rate Decay
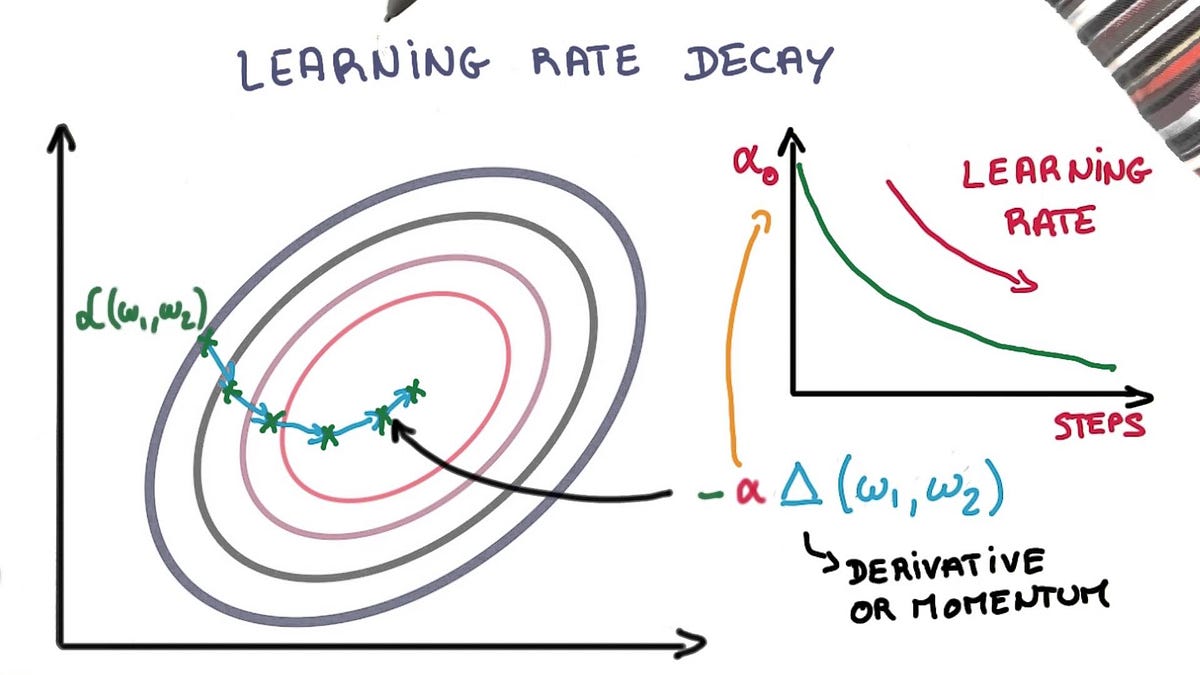
- যুগের উপর ভিত্তি করে ধীরে ধীরে শিক্ষার হার হ্রাস করুন।
- নির্দিষ্ট যুগে বিরাট বড় ড্রপ ব্যবহার করে শেখার হার হ্রাস করুন।
- Two popular and easy to use learning rate decay are as follows:
- Decrease the learning rate gradually based on the epoch.
- Decrease the learning rate using punctuated large drops at specific epochs.
4 — Dropout
একটি বড় সংখ্যা পরামিতি সঙ্গে গভীর স্নায়ু জাল খুব শক্তিশালী মেশিন লার্নিং সিস্টেম। তবে, overfitting যেমন নেটওয়ার্কের একটি গুরুতর সমস্যা। বড় নেটওয়ার্কে ব্যবহার করা ধীর, এটি পরীক্ষার সময় অনেকগুলি বড় বড় নিউরাল নেটগুলির ভবিষ্যদ্বাণীগুলিকে সংমিশ্রণ করে ওভারফিটিংয়ের সাথে মোকাবিলা করা কঠিন করে তোলে। Dropout এই সমস্যা মোকাবেলার জন্য একটি কৌশল।
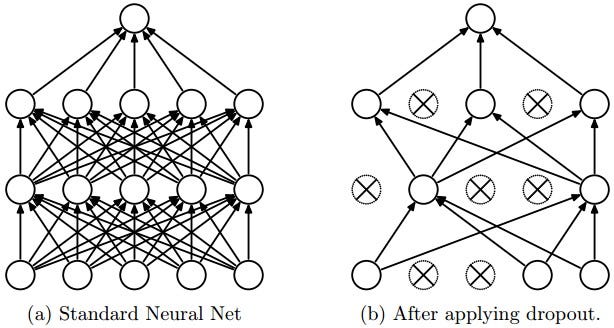
মূল ধারণা প্রশিক্ষণের সময় স্নায়ু নেটওয়ার্ক থেকে এলোমেলোভাবে তাদের সংযোগগুলি (তাদের সংযোগ সহ) হ্রাস করা হয়। এটি খুব বেশী co-adapting থেকে ইউনিট বাধা দেয়। প্রশিক্ষণ সময়, বিভিন্ন "thinned" নেটওয়ার্কের একটি সূচকীয় সংখ্যা থেকে ড্রপআউট নমুনা। পরীক্ষার সময়ে, সহজে একটি একক untwined নেটওয়ার্ক ব্যবহার করে এই সব thinned নেটওয়ার্কের পূর্বাভাস গড়ার প্রভাবটি আনুমানিক করা সহজ। এই উল্লেখযোগ্যভাবে overfitting হ্রাস এবং অন্যান্য নিয়মিতকরণ পদ্ধতির উপর বড় উন্নতি দেয়। ড্রপআউট দৃষ্টিভঙ্গি, বক্তৃতা স্বীকৃতি, ডকুমেন্ট শ্রেণীকরণ এবং কম্পিউটেশনাল জীববিজ্ঞানের তত্ত্বাবধানে শেখার কাজগুলির উপর স্নায়ুতন্ত্রের কর্মক্ষমতা উন্নত করতে দেখানো হয়েছে, অনেক বেঞ্চমার্ক ডেটাসেটগুলিতে অত্যাধুনিক ফলাফলগুলি গ্রহণ করে।
5 — Max Pooling
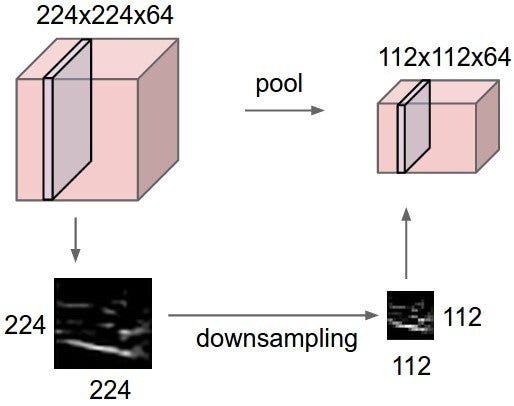
সর্বোচ্চ পুলিং একটি নমুনা ভিত্তিক discretization প্রক্রিয়া। বস্তুটি একটি ইনপুট উপস্থাপনা (চিত্র, লুকানো-স্তর আউটপুট ম্যাট্রিক্স, ইত্যাদি) নিচের-নমুনাটি হ্রাস করা, এর মাত্রা হ্রাস করা এবং উপ-অঞ্চলে বিন্যস্ত বৈশিষ্ট্যগুলি সম্পর্কে অনুমিতি করার অনুমতি দেওয়া। এই উপস্থাপনা একটি বিমূর্ত ফর্ম প্রদান করে অতিরিক্ত ফিটিং সাহায্য করার জন্য অংশে সম্পন্ন করা হয়। পাশাপাশি, এটি অভ্যন্তরীণ প্রতিনিধিত্বের মৌলিক অনুবাদগুলি উপলব্ধ করতে এবং প্যারামিটারের সংখ্যা হ্রাস করে গণনা খরচ কমিয়ে দেয়। সর্বোচ্চ উপস্থাপনা সাধারণত প্রাথমিক প্রতিনিধির নন-ওভারল্যাপিং উপ-স্তরগুলিতে একটি সর্বোচ্চ ফিল্টার প্রয়োগ করে সম্পন্ন করা হয়।
6 — Batch Normalization
স্বাভাবিকভাবেই, গভীর নেটওয়ার্কের সহ স্নায়ু নেটওয়ার্কগুলিতে ওজন প্রারম্ভিকতা এবং শেখার প্যারামিটারগুলির সতর্কতা অবলম্বন করা প্রয়োজন। ব্যাচ স্বাভাবিকীকরণ তাদের সামান্য ঝিম সাহায্য করে।
Weights problem:
- যাই হোক না কেন ওজন আরম্ভ করা, এটা র্যান্ডম বা অভিজ্ঞভাবে নির্বাচিত, তারা শিখেছি ওজন থেকে অনেক দূরে। প্রাথমিক যুগে, একটি মিনি ব্যাচ বিবেচনা করুন, প্রয়োজনীয় বৈশিষ্ট্য অ্যাক্টিভেশনগুলির পরিপ্রেক্ষিতে অনেকগুলি আউটলায়ার থাকবে।
- গভীর স্নায়ু নেটওয়ার্ক নিজেই দুর্বল, যেমন প্রাথমিক স্তরগুলির একটি ছোট সংঘাত, পরে স্তরগুলিতে একটি বড় পরিবর্তন ঘটে।
ব্যাক-প্রপাগ্যাগনের সময়, এই ঘটনাগুলির ফলে প্রয়োজনীয় আউটপুট উত্পাদন করার জন্য ওজনগুলি শিখার আগে, গ্রেডিয়েন্টগুলিকে আউটলায়ারগুলিকে ক্ষতিপূরণ দিতে হয়, যার অর্থ হল গ্র্যাডিয়েন্টগুলির বিভ্রান্তির কারণ। এই একত্রিত করার জন্য অতিরিক্ত epochs প্রয়োজন বাড়ে।

ব্যাচ স্বাভাবিকীকরণ এই গ্রেডিয়েন্টকে ক্ষয়ক্ষতি থেকে বহির্মুখী থেকে নিয়মিত করে এবং মিনি ব্যাচের সীমার মধ্যে সাধারণ লক্ষ্য (তাদের স্বাভাবিককরণ করে) দিকে প্রবাহিত করে।
শিক্ষার হার সমস্যা: সাধারনত, শিক্ষার হারগুলি ছোট রাখা হয়, যেমন গ্র্যাডেন্টগুলির একটি ছোট অংশই ওজনকে সংশোধন করে, এর কারণ হল বাহ্যিক অ্যাক্টিভেশনের জন্য গ্র্যাডেন্টগুলি শিখেছি সক্রিয় ক্রিয়াকলাপগুলিকে প্রভাবিত করবে না। ব্যাচ স্বাভাবিকীকরণ দ্বারা, এই বাহ্যিক সক্রিয়তা হ্রাস করা হয় এবং তাই উচ্চতর শিক্ষার হার শেখার প্রক্রিয়া ত্বরান্বিত করতে ব্যবহার করা যেতে পারে।
7 — Long Short-Term Memory:
একটি LSTM নেটওয়ার্কের নিম্নলিখিত তিনটি দিক রয়েছে যা একটি পুনরাবৃত্ত নিউরোল নেটওয়ার্কের স্বাভাবিক নিউরন থেকে আলাদা করে:
- It has control on deciding when to let the input enter the neuron.ইনপুট নিউরন প্রবেশ করতে যখন সিদ্ধান্ত নেওয়ার উপর এটি নিয়ন্ত্রণ আছে।
- It has control on deciding when to remember what was computed in the previous time step.পূর্ববর্তী সময় ধাপে কী গণনা করা হয়েছিল তা মনে রাখার সময় এটি নিয়ন্ত্রণের উপর নিয়ন্ত্রণ করে।
- It has control on deciding when to let the output pass on to the next time stamp.পরবর্তী সময় স্ট্যাম্প আউটপুট পাস যখন সিদ্ধান্ত নেওয়ার উপর এটি নিয়ন্ত্রণ আছে।
এলএসটিএম এর সৌন্দর্য এটি বর্তমান ইনপুট নিজেই উপর ভিত্তি করে এই সব সিদ্ধান্ত নেয়। সুতরাং যদি আপনি নিম্নলিখিত চিত্রটি দেখুন:
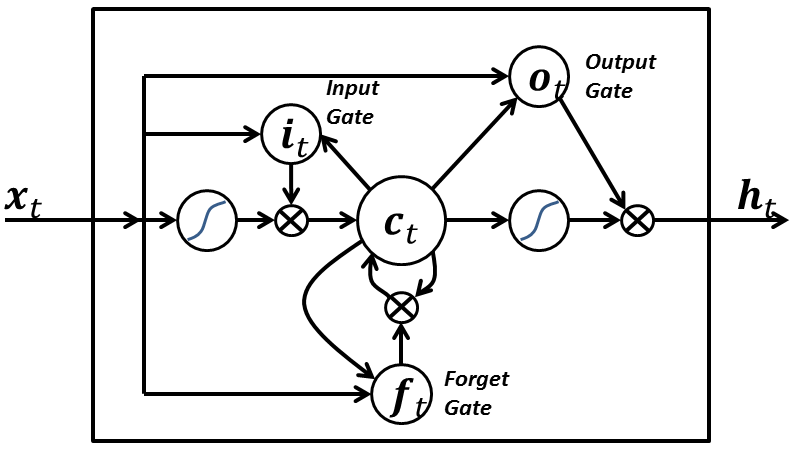
ইনপুট সংকেত এক্স (টি) বর্তমান সময়ে স্ট্যাম্প সব উপরে 3 পয়েন্ট সিদ্ধান্ত নেয়। ইনপুট গেট পয়েন্ট 1 এর সিদ্ধান্ত নেয়। ভুলে যাওয়া গেট পয়েন্ট 2 এ একটি সিদ্ধান্ত নেয় এবং আউটপুট গেট 3 পয়েন্টে সিদ্ধান্ত নেয়। কেবলমাত্র ইনপুট এই তিনটি সিদ্ধান্ত নিতে সক্ষম। এই আমাদের মস্তিষ্কের কাজ কিভাবে অনুপ্রাণিত হয় এবং ইনপুট উপর ভিত্তি করে হঠাৎ প্রেক্ষাপটে সুইচ পরিচালনা করতে পারেন।
0 comments:
Post a Comment