
You only look once, or YOLO
সেখানে দ্রুত বস্তুর সনাক্তকরণ আলগোরিদিম এক। যদিও এটি আর সঠিক বস্তু সনাক্তকরণ অ্যালগরিদম নয় তবে এটি খুব ভাল পছন্দ, যখন আপনি রিয়েল-টাইম সনাক্তকরণের প্রয়োজন হয়, অত্যধিক নির্ভুলতার সমায়ের ক্ষতি ছাড়াই।
কয়েক সপ্তাহ আগে, YOLO এর তৃতীয় সংস্করণটি বেরিয়ে এসেছে এবং এই পোস্টটি হল YOLO v3 এ উপস্থাপিত পরিবর্তনগুলি ব্যাখ্যা করার লক্ষ্য। YOLO স্থল থেকে কি হয় তা ব্যাখ্যা করে একটি পোস্ট হতে যাচ্ছে না। আমি আপনি YOLO v2 কাজ কিভাবে কাজ করে জানতে চান, তাহলে Joseph Redmon et all /জোসেফ রেডমোন, আলী ফারহাদিদ্বারা এবং নিম্নলিখিত সমস্ত কাগজপত্র পরীক্ষা করে দেখেন YOLO কীভাবে কাজ করে ।
YOLO v1
YOLO v2
A nice blog post on YOLO
YOLO v3: Better, not Faster, Stronger
YOLO v2 কাগজটির আনুষ্ঠানিক শিরোনামটি যদি মনে হয় YOLO একটি বস্তুর সনাক্তকরণ অ্যালগরিদমের পরিবর্তে বাচ্চাদের জন্য দুধ ভিত্তিক স্বাস্থ্য পানীয় ছিল। এটি "YOLO9000: Better, Fast, Stronger" নামকরণ করা হয়েছে।
YOLO 9000 এটি সময় জন্য দ্রুততম ছিল এবং সবচেয়ে সঠিক অ্যালগরি্মের মধ্য এক। যাইহোক, কয়েক বছর ধরে লাইনটি নিচে এবং এটি RetinaNet এর মতো অ্যালগরিদমগুলির এবং SSD এর নির্ভুলতার পরিপ্রেক্ষিতে চেয়েও বেশি। এটা এখনও, দ্রুততম ছিল।
কিন্তু YOLO v3 এর নির্ভুলতায়র গতি boosts করা হয়েছে। পূর্বের বৈকল্পিক টি একটি ঘড়ি Titan X এ 45 টি FPS এ দৌড়েছিল, বর্তমান সংস্করণটি প্রায় 30 টি FPS দৌড়েছিল । complexity of underlying architecture called Darknet সাথে এটির সম্পর্ক আছে।
Darknet-53
YOLO v2 একটি কাস্টম ডীপ আর্কিটেকচার darkact-19 ব্যবহৃত, অবজেক্ট সনাক্তকরণের জন্য আরও 11 টি স্তর সহ একটি 19-স্তর নেটওয়ার্ক সম্পূরক। 30-লেয়ার আর্কিটেকচারের সাথে, YOLO v2 প্রায়ই ছোট বস্তুগুলির সাথে small object detections করে।এই স্তরগুলি ইনপুটটিকে নিম্নমানের হিসাবে সূক্ষ্মাতিসূক্ষ্ম দাগযুক্ত বৈশিষ্ট্যগুলির loss এর জন্য দায়ী করা হয়েছিল। এটি সমাধান করার জন্য, YOLO v2 নিম্ন স্তরের বৈশিষ্ট্যগুলি ক্যাপচার করতে পূর্ববর্তী স্তর থেকে একটি পরিচয় ম্যাপিং, কনক্যাটেনটিং বৈশিষ্ট্য ব্যবহার করে।
যাইহোক, YOLO v2 এর আর্কিটেকচারটি এখনও বেশিরভাগ গুরুত্বপূর্ণ উপাদানগুলির আনুপুস্তিত রয়েছে যা বর্তমানে state-of-the art algorithms গুলিতে প্রধান। No residual blocks, no skip connections and no upsampling এই সব YOLO v3 জড়িত নেই।
প্রথমত, YOLO v3 ডার্কনেটের একটি বৈকল্পিক ব্যবহার করে যা মূলত 53 স্তর নেটওয়ার্ককে ইম্যাগনেটে প্রশিক্ষিত করে।
সনাক্তকরণের কাজটির জন্য, 53 টি স্তর তার উপরে স্ট্যাক করা হয়েছে, যা আমাদের YOLO v3 এর জন্য 106 স্তর সম্পূর্ণরূপে সংশ্লেষিক অন্তর্নিহিত আর্কিটেকচার সরবরাহ করে।
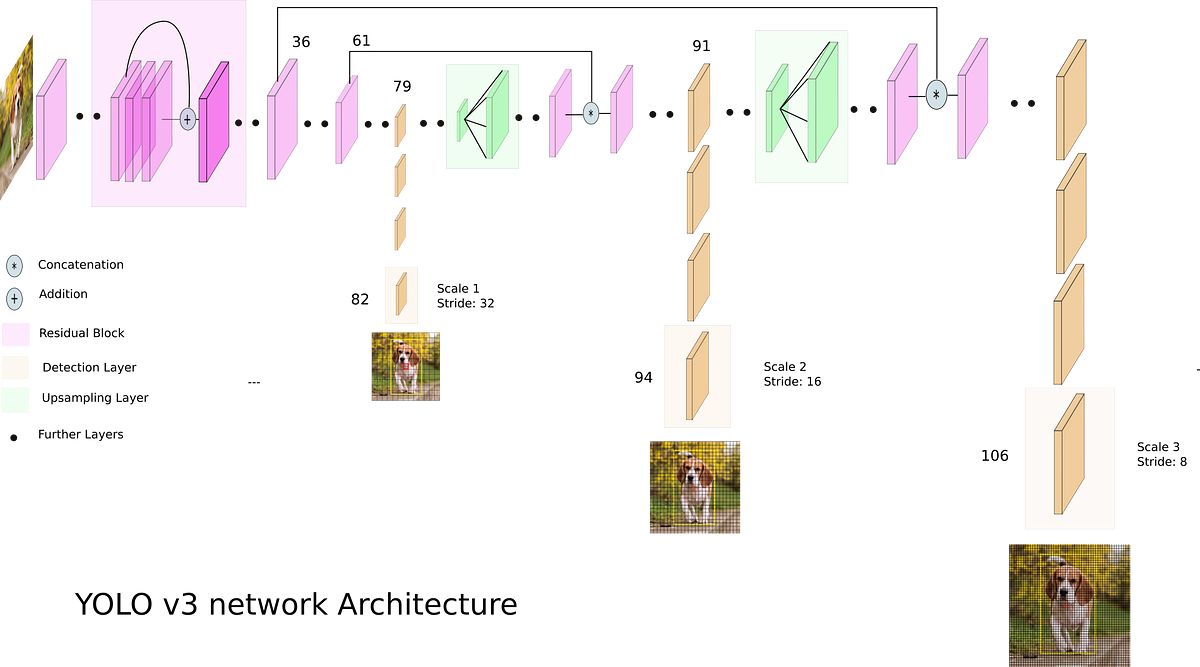
Detection at three Scales
অবশিষ্ট নতুন স্থাপত্য সংযোগ, এবং upsampling boasts V3 এর সবচেয়ে উল্লেখযোগ্য বৈশিষ্ট্য হল এটি তিনটি ভিন্ন স্কেলে ডিটেকশন তৈরি করে। YOLO একটি সম্পূর্ণ রূপান্তরমূলক নেটওয়ার্ক এবং এর শেষ আউটপুট একটি বৈশিষ্ট্য মানচিত্রে একটি 1 x 1 কার্নেল প্রয়োগ করে উত্পন্ন হয়। YOLO v3-এ, সনাক্তকরণটি নেটওয়ার্কগুলির তিনটি ভিন্ন স্থানে তিনটি আলাদা আকারের বৈশিষ্ট্য মানচিত্রগুলিতে 1 x 1 সনাক্তকরণ কার্নেল প্রয়োগ করে সম্পন্ন করা হয়।
সনাক্তকরণ কার্নেলের আকার 1 x 1 x (বি x (5 + C))। এখানে B বদ্ধ বাক্সগুলির সংখ্যা যা বৈশিষ্ট্যের মানচিত্রে একটি কক্ষ ভবিষ্যদ্বাণী করতে পারে, "5" 4 সীমানা বাক্সের গুণাবলীর জন্য এবং এক বস্তুর আস্থা এবং C হল শ্রেণী সংখ্যা। COLO, B = 3 এবং C = 80 তে প্রশিক্ষিত YOLO v3 তে, তাই কার্নেলের আকার 1 x 1 x 255। এই কার্নেল দ্বারা উত্পাদিত বৈশিষ্ট্য মানচিত্রটি পূর্ববর্তী বৈশিষ্ট্য মানচিত্রের সমান উচ্চতা এবং প্রস্থে রয়েছে এবং এর সাথে সনাক্তকরণ বৈশিষ্ট্য রয়েছে উপরে বর্ণনা হিসাবে।

Image credits: https://blog.paperspace.com/how-to-implement-a-yolo-object-detector-in-pytorch/
নেটওয়ার্কটির গতিবেগ বা লেয়ারকে অনুপাত হিসাবে সংজ্ঞায়িত করতে চাই, যার দ্বারা এটি ইনপুটকে কমিয়ে দেয়। নিচের উদাহরণগুলিতে, আমি অনুমান চিত্র রয়েছে আমাদের আকার 416 x 416 এর একটি ইনপুট ।
YOLO v3 তিনটি স্কেলে ভবিষ্যদ্বাণী করে, যা যথাক্রমে 32, 16 এবং 8 দ্বারা ইনপুট চিত্রের মাত্রাগুলিকে কমিয়ে দেয়।
প্রথম সনাক্তকরণ 82nd স্তর দ্বারা তৈরি করা হয়। প্রথম 81 টি স্তরগুলির জন্য, চিত্রটিকে নেটওয়ার্ক দ্বারা স্যাম্পল করা হয়েছে, যেমন 81 তম স্তরটি 32 এর একটি স্তর। যদি আমাদের 416 x 416 এর একটি চিত্র থাকে, তাহলে ফলাফল বৈশিষ্ট্য মানচিত্র 13 x 13 হবে। একটি সনাক্তকরণ এখানে 1 x 1 সনাক্তকরণ কার্নেল ব্যবহার করে তৈরি করা হয়েছে, যা আমাদের সনাক্তকরণ বৈশিষ্ট্য মানচিত্র 13 x 13 x 255 দেয়।
তারপরে, লেয়ার 79 এর বৈশিষ্ট্য মানচিত্রটি 2x দ্বারা ২6 x 26 এর মাত্রা দ্বারা স্যাম্পল হওয়ার আগে কয়েকটি সংশ্লেষিক স্তরের আওতায় পড়ে। এই বৈশিষ্ট্য মানচিত্রটিকে স্তর 61 থেকে বৈশিষ্ট্য মানচিত্রের সাথে গভীরভাবে সংযুক্ত করা হয়। তারপরে সংযুক্ত বৈশিষ্ট্য মানচিত্রটি আবার পূর্ববর্তী স্তর (61) থেকে বৈশিষ্ট্যগুলিকে ফিউজ করার জন্য কয়েকটি 1 x 1 সংশ্লেষিক স্তর স্তরযুক্ত। তারপর, দ্বিতীয় সনাক্তকরণটি 94 তম স্তর দ্বারা তৈরি করা হয়, এটি সনাক্তকরণ বৈশিষ্ট্য মানচিত্র 26 x 26 x 255 প্রদান করে
একই পদ্ধতিটি আবার অনুসরণ করা হয়, যেখানে লেয়ার 91 থেকে বৈশিষ্ট্য মানচিত্র স্তর 36 থেকে একটি বৈশিষ্ট্য মানচিত্রের সাথে গভীরভাবে সংযুক্ত হওয়ার আগে কয়েকটি সংশ্লেষিক স্তরের আওতায় পড়ে। আগের মত, কয়েকটি 1 x 1 সংশ্লেষ স্তরগুলি পূর্ববর্তী তথ্যটি ফিউজ করার জন্য অনুসরণ করে স্তর (36)। আমরা 106 তম স্তর 3 এ চূড়ান্ত করতে, আকার 52 x 52 x 255 আকার মানচিত্র প্রদান।
Better at detecting smaller objectsছোট বস্তু সনাক্ত করার ভাল
বিভিন্ন স্তরের ডিটেকশনগুলি ছোট বস্তুর সনাক্তকরণের সমস্যা, YOLO v2 এর সাথে ঘন ঘন সনাক্ত করতে সহায়তা করে। পূর্ববর্তী স্তরগুলির সাথে সংযুক্ত আপসপ্লাইড স্তরের ছোট বস্তুগুলি সনাক্ত করতে সহায়তা করে এমন সূক্ষ্ম দাগযুক্ত বৈশিষ্ট্যগুলি সংরক্ষণ করতে সহায়তা করে।
13 x 13 লেয়ার বড় বস্তু সনাক্ত করার জন্য দায়ী, যখন 52 x 52 স্তরটি ছোট বস্তু সনাক্ত করে, 26 x 26 লেয়ার সনাক্তকরণ মাঝারি বস্তুগুলির সাথে। এখানে বিভিন্ন স্তর দ্বারা একই বস্তুর বিভিন্ন তুলনামূলক বিশ্লেষণ।
Choice of anchor (অ্যাংকার)boxes/ পছন্দর বাক্সের আশ্রয়স্থল
YOLO v3, মোটামুটি 9 আশ্রয়স্থল বাক্স ব্যবহার করে। প্রতিটি স্কেল জন্য তিন। আপনি যদি আপনার নিজের ডেটাসেটে YOLO প্রশিক্ষণ দিচ্ছেন তবে আপনার 9 এনকোজ তৈরির জন্য K-Means ক্লাস্টারিং ব্যবহার করা উচিত।
তারপরে, আশ্রয়স্থলগুলি একটি মাত্রার নিম্নমানের ক্রম ব্যবস্থা করে। প্রথম স্কেলের জন্য তিনটি বড় আশ্রয়স্থল, দ্বিতীয় স্কেলের জন্য পরবর্তী তিনটি এবং তৃতীয়টির জন্য শেষ তিনটি আশ্রয়স্থল।
More bounding boxes per image/প্রতিটি ইমেজ আরো এর bounding বক্স
একই আকারের একটি ইনপুট চিত্রের জন্য, YOLO v3 YOLO v2 এর চেয়ে আরও বেশি আবদ্ধ বাক্সগুলির পূর্বাভাস দেয়। উদাহরণস্বরূপ, এটি 416 x 416 এর স্থানীয় রেজোলিউশনে, YOLO v2 13 x 13 x 5 = 845 বক্স পূর্বাভাস দিয়েছে। প্রতিটি গ্রিড সেলে 5 টি অ্যাঙ্কার ব্যবহার করে 5 টি বাক্স সনাক্ত করা হয়।
অন্যদিকে YOLO v3 3 টি ভিন্ন ধাপে বাক্সগুলি পূর্বাভাস দেয়। 416 x 416 এর একই চিত্রের জন্য পূর্বাভাস বাক্সগুলির সংখ্যা 10,647। এর অর্থ হল YOLO V3 YOLO v2 দ্বারা পূর্বাভাস বাক্সগুলির সংখ্যা 10x ভবিষ্যদ্বাণী করে। আপনি সহজেই কল্পনা করতে পারেন কেন এটি YOLO v2 এর চেয়ে ধীর গতির। প্রতিটি স্কেলে, প্রতিটি গ্রিড 3 নোঙ্গর ব্যবহার করে 3 বাক্সের পূর্বাভাস দিতে পারে। যেহেতু তিনটি স্কেল রয়েছে তাই মোট স্নাতকের বাক্সে সংখ্যা 9, 3 হয়।
Changes in Loss Function /ক্ষতি ফাংশন এর পরিবর্তন
এর আগে, YOLO v2 এর ক্ষতি ফাংশন এটির মতো লাগছিল।

কিন্তু শেষ তিনটি পদ লক্ষ্য নিয় । তাদের মধ্যে, প্রথমটি বস্তুর পূর্বাভাসের জন্য দায়ী বাক্সগুলিকে আবদ্ধ করার জন্য বস্তুর স্কোর পূর্বাভাসকে শাস্তি দেয় (এইগুলির জন্য স্কোরগুলি আদর্শভাবে 1 হওয়া উচিত), দ্বিতীয় কোনও বস্তু না থাকা বাক্সগুলিকে আবদ্ধ করার জন্য (স্কোরগুলি আদর্শভাবে শূন্য হওয়া উচিত), এবং শেষ এক বস্তুর ভবিষ্যদ্বাণী যা সীমানা বাক্স জন্য বর্গ পূর্বাভাস penalizes।
YOLO v2 এর শেষ তিনটি পদ স্কোয়ার ত্রুটিগুলির মধ্যে রয়েছে, যখন YOLO v3 এ, তারা ক্রস-এনট্রপি ত্রুটি পদ দ্বারা প্রতিস্থাপিত হয়েছে। অন্য কথায়, YOLO v3 এ বস্তুর আস্থা এবং বর্গ পূর্বাভাসগুলি এখন লজিস্টিক প্রতিক্রিয়া মাধ্যমে পূর্বাভাস দেওয়া হয়
আমরা প্রতিটি স্থল সত্য বক্সের জন্য ডিটেক্টরকে প্রশিক্ষণ দিচ্ছি, আমরা একটি আবদ্ধ বাক্স বরাদ্দ করি, যার নোঙ্গরটি স্থল সত্য বক্সের সর্বাধিক ওভারল্যাপ আছে।
No more softmaxing the classesক্লাসের জন্য আরনা softmaxing
Yolo V3 এখন ইমেজ সনাক্ত বস্তুর জন্য multilabel শ্রেণীবিভাগ performs।আগে YOLO তে, লেখক বর্গক্ষেত্রের স্কোরকে নরম করে তুলতে এবং বর্গক্ষেত্রের বাক্সে থাকা বস্তুর বর্গ হতে সর্বাধিক স্কোর সহ ক্লাস গ্রহণ করে। এই YOLO v3 মধ্যে সংশোধন করা হয়েছে।
সফটম্যাক্সিং ক্লাসগুলি অনুমানের উপর নির্ভর করে যে ক্লাস পারস্পরিক একচেটিয়া, বা সহজ ভাষায়, যদি কোনও বস্তুটি এক বর্গের অন্তর্গত থাকে, তবে এটি অন্যের অন্তর্গত নয়। এই COCO ডেটাসেট জরিমানা কাজ করে।
যাইহোক, যখন আমাদের একটি ডেটাসেটে ব্যক্তি ও মহিলাদের মতো ক্লাস থাকে, তখন উপরের অনুমানটি ব্যর্থ হয়। এই কারণেই YOLO এর লেখক শ্রেণীগুলি softmaxing থেকে বিরত আছে। পরিবর্তে, প্রতিটি বর্গ স্কোরটি লজিস্টিক রিগ্রেশন ব্যবহার করে পূর্বাভাস দেওয়া হয় এবং একটি থ্রেশহোল্ড একটি বস্তুর জন্য একাধিক লেবেল পূর্বাভাস দেওয়ার জন্য ব্যবহার করা হয়। এই থ্রেশহোল্ড তুলনায় উচ্চ স্কোর সঙ্গে ক্লাস বাক্সে নিযুক্ত করা হয়।
Benchmarking (স্থির করা মাপকাঠি)
COCO 50 বেঞ্চমার্কে, বেশিরভাগ দ্রুত, যখন YETO V3 RetinaNet টের মতো অন্যান্য state of art detectors গুলির সাথে সমানভাবে performs হয়। এটি এসএসডি এবং এর বৈকল্পিকগুলির চেয়েও ভাল। এখানে কাগজ থেকে পারফরমেন্স একটি তুলনা।

কিন্তু, কিন্তু, YOLO একটি সনাক্তকরণ প্রত্যাখ্যান করতে ব্যবহৃত IoU এর উচ্চতর মূল্য সহ COCO মানদন্ডগুলিতে ছেড়ে দেয়। আমি ব্যাখ্যা করবো না যে সিওওও বেঞ্চমার্কটি কাজটির পরিধি অতিক্রম করে কীভাবে কাজ করে, কিন্তু 50 টি সিওওও 50 বেঞ্চমার্কের মধ্যে 50 টি পূর্বনির্ধারিত আবদ্ধ বাক্সগুলি বস্তুর স্থল সত্য বক্সগুলিকে কীভাবে ভালভাবে সাজানো যায় তা পরিমাপ করে। 50 এখানে 0.5 আইওইউ সংশ্লিষ্ট। ভবিষ্যদ্বাণী এবং স্থল সত্য বক্সের মধ্যে আইওইউ 0.5 এর কম হলে, ভবিষ্যদ্বাণীটি একটি বিভ্রান্তিকর হিসাবে শ্রেণীবদ্ধ করা হয় এবং মিথ্যা ইতিবাচক হিসাবে চিহ্নিত করা হয়।
বেঞ্চমার্কগুলিতে, যেখানে এই সংখ্যাটি বেশি (বলে, COCO 75), বাক্সগুলি মূল্যায়ন ম্যাট্রিক দ্বারা প্রত্যাখ্যাত না হওয়ার জন্য আরও পুরোপুরি সংলগ্ন করা দরকার। এখানে YOLO RetinaNet দ্বারা বহিষ্কৃত হয়, কারণ এটি আবদ্ধ বাক্সগুলি RetinaNet টের পাশাপাশি একত্রিত হয় না। এখানে একটি বিস্তৃত বিন্যাসের জন্য একটি বিস্তারিত টেবিল।

Doing some experiments
আপনি এই Github repo তে প্রদত্ত কোডটি ব্যবহার করে চিত্র বা ভিডিওতে ডিটেকটর চালাতে পারেন।কোডটি PyTorch 0.3+, ওOpenCV 3 and Python 3.5. Setup the repo, এবং আপনি এটি বিভিন্ন পরীক্ষা চালাতে পারেন।
Different Scales
Here is a look at what the different detection layers pick up
python detect.py --scales 1 --images imgs/img3.jpg

Detection at scale 1, we see somewhat large objects are picked. But we don’t detect a few cars.
python detect.py --scales 2 --images imgs/img3.jpg

No detections at scale 2.
python detect.py --scales 3 --images imgs/img3.jpg

Detection at the largest scale (3). Look how only the small objects are picked up, which weren’t detected by scale 1.
Different Input resolutionবিভিন্ন ইনপুট রেজল্যুশন

Input resolution of the image: 320 x 320
python detect.py --reso 416 --images imgs/imgs4.jpg

Input resolution of the image: 416 x 416
python detect.py --reso 608 --images imgs/imgs4.jpg

Here, we detect one less chair than before
python detect.py --reso 960 --images imgs/imgs4.jpg

Here, the detector picks up a false detection, the “Person” at the right
বড় ইনপুট রেজুলেশন আমাদের ক্ষেত্রে অনেক সাহায্য করে না, তবে তারা ছোট বস্তুর সাথে চিত্র সনাক্ত করতে সহায়তা করতে পারে। অন্য দিকে, বড় ইনপুট রেজুলেশন আনুমানিক সময় যোগ করে । এটি একটি hyper parameter যা প্রয়োগের উপর নির্ভর করে সুরক্ষিত করা প্রয়োজন।
আপনি অন্য মেট্রিকগুলির সাথে পরীক্ষা করতে পারেন যেমন batch size, objectness confidence, and NMS threshold by going to the repoতে গিয়ে। সবকিছু ReadMe ফাইল উল্লেখ করা হয়েছে।
Implementing YOLO v3 from scratchস্ক্র্যাচ থেকে YOLO v3 বাস্তবায়ন
আপনি যদি Pyotorch এ YOLO v3 ডিটেক্টরটি নিজের দ্বারা প্রয়োগ করতে চান, তবে এখানে আমি এমন একটি টিউটোরিয়ালের সিরিজ তৈরি করেছি যা একইভাবে পেপারস্পেসে একই কাজ করার জন্য লিখেছে। এখন, আমি এই টিউটোরিয়ালে যেতে চাইলে আপনি PyTorch সাথে মৌলিক পরিচিতি আশা করবেন। আপনি যদি একজন প্রারম্ভিক PyTorch ব্যবহারকারী থেকে মধ্যবর্তীতে স্থানান্তরিত হতে চান তবে এই টিউটোরিয়ালটি সঠিক।
0 comments:
Post a Comment