Tensorflow Tutorial 2: image classifier using convolutional neural network
Tensorflow টিউটোরিয়াল 2: স্নায়ু নেটওয়ার্ক ব্যবহার করে ইমেজ ক্লাসিফায়ার
এই টেনসফ্লো টিউটোরিয়ালে, আমরা টেনসফ্লো ব্যবহার করে একটি কনভোলিউশনাল স্নায়ু নেটওয়ার্ক ভিত্তিক চিত্র শ্রেণীবদ্ধকারী তৈরি করব। আপনি যদি কেবল Tensorflow এর সাথে শুরু করা শুরু করেন, তাহলে এখানে একটি মৌলিক Tensorflow টিউটোরিয়ালটি পড়ার একটি ভাল ধারণা হবে।
একটি কনভোলিউশনাল স্নায়ু নেটওয়ার্ক ভিত্তিক চিত্র শ্রেণীবদ্ধকারী কীভাবে তৈরি করবেন তা প্রদর্শনের জন্য, আমরা একটি 6 স্তর স্নায়ু নেটওয়ার্ক তৈরি করব যা বিড়ালদের কুকুরগুলির চিত্র সনাক্ত এবং আলাদা করবে। আমরা যে নেটওয়ার্কটি তৈরি করব তা হল একটি ছোট নেটওয়ার্ক যা আপনি CPU এ চালাতে পারেন। ঐতিহ্যগত নিউরাল নেটওয়ার্ক যা ইমেজ শ্রেণিবদ্ধকরণে খুব ভাল থাকে তার অনেক বেশি প্যারামিটার রয়েছে এবং CPU এ প্রশিক্ষিত হলে অনেক সময় নেয়। যাইহোক, এই পোস্টে, আমার লক্ষ্য হল ILSVRC.-তে অংশগ্রহণের পরিবর্তে টেনসফ্লো ব্যবহার করে একটি বাস্তব-বিশ্ব সংশ্লেষিক নিউরাল নেটওয়ার্ক কীভাবে তৈরি করা যায় তা আপনাকে দেখানো। আমরা Tensorflow টিউটোরিয়াল দিয়ে শুরু করার আগে, আসুন কনভোলিউশনাল নিউরাল নেটওয়ার্ক বুনিয়াদি আবরণ। যদি আপনি ইতিমধ্যে কনভেট নেটগুলির সাথে পরিচিত হন (এবং তাদের কনফারনেটগুলি কল করুন), আপনি অংশ -২ তে যেতে পারেন যেমন তেনসফ্লোও টিউটোরিয়াল।
Basics of Convolutional Neural network (CNN):
নিউরাল নেটওয়ার্ক একটি অপ্টিমাইজেশান সমস্যা সমাধানের জন্য মূলত গাণিতিক মডেল। তারা নিউরনের তৈরি, স্নায়ু নেটওয়ার্কগুলির মৌলিক গণনা ইউনিট। একটি নিউরন একটি ইনপুট নেয় (x বলুন), তার উপর কিছু গণনা করুন (বলুন: একটি পরিবর্তনশীল ডাব্লু দিয়ে এটি বাড়ান এবং একটি ভেরিয়েবল b যোগ করে) একটি মান তৈরি করতে (বলুন; z = wx + b)। এই মান একটি নিউরনের চূড়ান্ত আউটপুট (অ্যাক্টিভেশন) তৈরি করতে অ্যাক্টিভেশন ফাংশন (চ) নামে একটি অ-রৈখিক ফাংশনে প্রেরণ করা হয়। সক্রিয়করণ ফাংশন অনেক ধরণের আছে। জনপ্রিয় অ্যাক্টিভেশন ফাংশনটি হল সিগোময়েড, যা:

সিগময়েড ফাংশনটি অ্যাক্টিভেশন ফাংশন হিসাবে ব্যবহার করে নিউরনকে সিগোময়েড নিউরন বলা হবে। অ্যাক্টিভেশন ফাংশনের উপর নির্ভর করে, নিউরনগুলি নামকরণ করা হয় এবং RELU, TanH ইত্যাদি এর মতো অনেকগুলি ধরণের রয়েছে (মনে রাখবেন)। এক নিউরন একাধিক নিউরনের সাথে সংযুক্ত হতে পারে, এটির মতো:

এই উদাহরণে, আপনি দেখতে পারেন যে ওজনগুলি সংযোগের সম্পত্তি, যেমন প্রতিটি সংযোগের একটি ভিন্ন ওজন মূল্য আছে এবং পক্ষপাত নিউরনের সম্পত্তি। এটি একটি সিগময়েড নিউরনের সম্পূর্ণ চিত্র যা আউটপুট Y তৈরি করে:

layers
স্তরসমূহ: যদি আপনি একটি লাইনের নিউরনগুলি স্ট্যাক করেন, এটি একটি স্তর বলা হয়; যা স্নায়ু নেটওয়ার্কের পরবর্তী বিল্ডিং ব্লক।

আপনি উপরে দেখতে পারেন, সবুজ রঙের নিউরনগুলি 1 স্তর তৈরি করে যা নেটওয়ার্কের প্রথম স্তর যা নেটওয়ার্কের মাধ্যমে ইনপুট ডেটা পাস করে। একইভাবে, লাল স্তর হিসাবে প্রদর্শিত শেষ স্তর আউটপুট স্তর বলা হয়। ইনপুট এবং আউটপুট স্তর মধ্যে স্তর লুকানো স্তর বলা হয়। এই উদাহরণে, আমরা নীল দেখানো মাত্র 1 লুকানো স্তর আছে। যেসব নেটওয়ার্কে অনেক লুকানো স্তর রয়েছে তারা আরো সঠিক বলে মনে করে এবং গভীর নেটওয়ার্ক বলে এবং এই গভীর নেটওয়ার্কগুলি ব্যবহার করে মেশিন লার্নিং অ্যালগরিদমগুলিকে গভীর শিক্ষার বলা হয়।
স্তরগুলির ধরন:
সাধারণত, এক লেয়ারের সমস্ত নিউরনগুলি একই রকম গাণিতিক ক্রিয়াকলাপ করে এবং এভাবে লেয়ারটির নামটি কীভাবে পায় (ইনপুট এবং আউটপুট লেয়ারগুলিকে ছোট্ট গাণিতিক ক্রিয়াকলাপ হিসাবে বাদ দিয়ে)। এখানে আপনার সম্পর্কে জানা উচিত এমন স্তরগুলির সর্বাধিক জনপ্রিয় প্রকার:
Convolutional Layer:রূপান্তরকারী স্তর:
কনভোলিউশন একটি গাণিতিক অপারেশন যা সিগন্যাল ফিল্টার করার জন্য সিঙ্গেল প্রক্রিয়াকরণে ব্যবহৃত হয়, সিগন্যালগুলিতে নিদর্শন খুঁজে বের করে। একটি সংশ্লেষক স্তরে, সমস্ত নিউরনগুলি ইনপুটগুলিতে কনভোলিউশন অপারেশন প্রয়োগ করে, তাই তাদেরকে কনভোলিউশনাল নিউরন বলা হয়। একটি কনভোলিউশন নিউরন মধ্যে সবচেয়ে গুরুত্বপূর্ণ প্যারামিটার ফিল্টার আকার, এর বলুন আমরা ফিল্টার আকার 5 * 5 * 3 সঙ্গে একটি স্তর আছে বলে। এছাড়াও, অনুমান করুন যে কনভোলিউশনাল নিউরনকে প্রদত্ত ইনপুটটি 3 চ্যানেলগুলির 32 * 32 এর আকারের ইনপুট চিত্র।
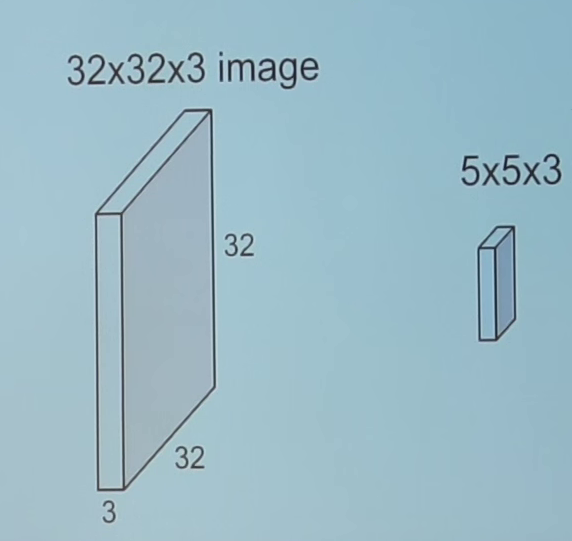
চলুন ছবির আকারের একটি অংশে একটি 5 * 5 * 3 (3 রঙ্গিন চিত্রের চ্যানেলের সংখ্যা 3) এবং আমাদের ফিল্টার (দ্রষ্টব্য) সহ কনভোলিউশন (ডট পণ্য) গণনা করি। এই এক কনভোলিউশন অপারেশন আউটপুট হিসাবে একটি একক সংখ্যা ফলে হবে। আমরা এই আউটপুট এ পক্ষপাত (বি) যোগ করা হবে।
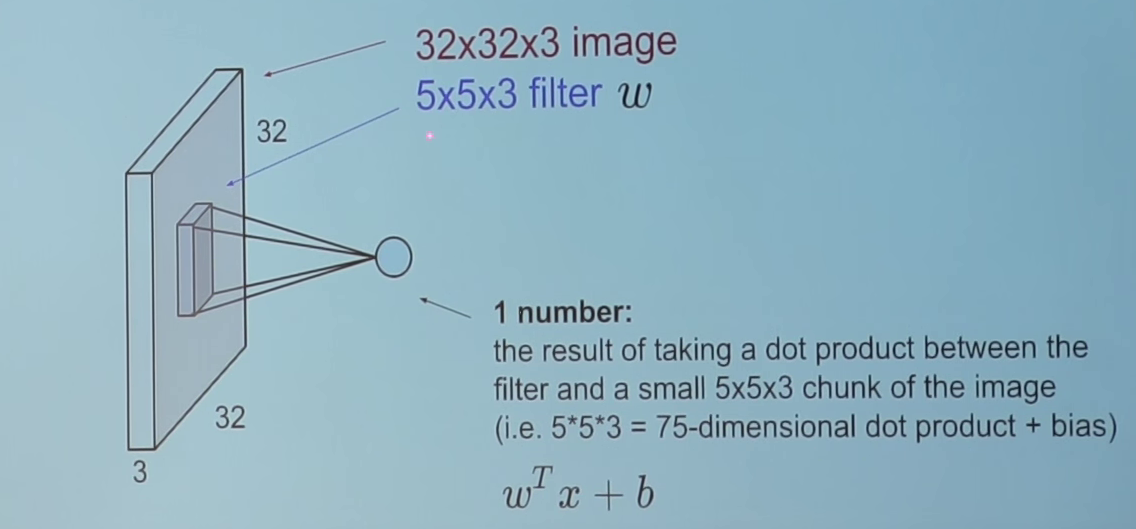
বিন্দু পণ্যের গণনা করার জন্য, ফিল্টারের তৃতীয় মাত্রাটি ইনপুটগুলিতে চ্যানেলগুলির সংখ্যা হিসাবে একই হতে বাধ্য। যেমন আমরা যখন ডট প্রোডাক্ট গণনা করি তখন এটি 5 * 5 * 3 আকারের খন্ডের 5 * 5 * 3 আকারের ফিল্টারের একটি ম্যাট্রিক্স গুণমান।
আমরা নীচের পরিকল্পিত দ্বারা দেখানো ইমেজ জুড়ে এই আউটপুট গণনা করার জন্য পুরো ইনপুট ইমেজ উপর সংশ্লেষিক ফিল্টার স্লাইড করা হবে:
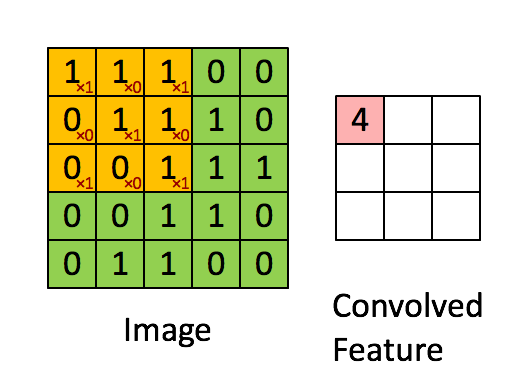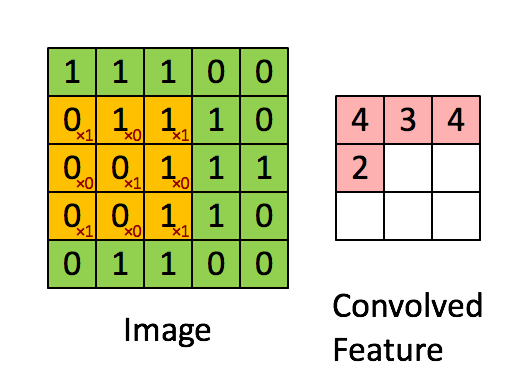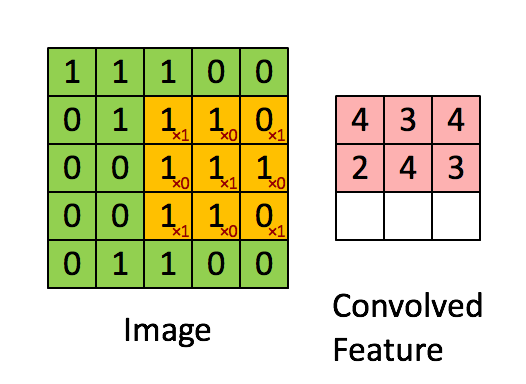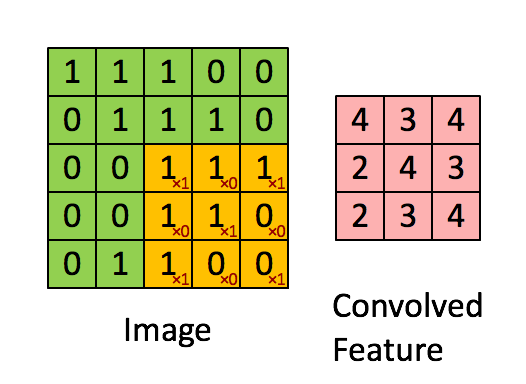
এই ক্ষেত্রে, আমরা আমাদের উইন্ডোটি একবারে 1 পিক্সেল দ্বারা স্লাইড করি। কিছু ক্ষেত্রে, লোকেরা 1 পিক্সেলের বেশি করে উইন্ডো স্লাইড করে। এই সংখ্যা stride. বলা হয়।
যদি আপনি 2 ডি তে এই সমস্ত আউটপুটগুলিকে একত্রিত করেন, তবে আমাদের 28 * 28 আকারের একটি আউটপুট activation mapঅ্যাক্টিভেশন ম্যাপ থাকবে (আপনি 5 * 5 এর ফিল্টার সহ ২8 * 28 থেকে ২8 * 28 এবং 1 এর প্রান্তে কেন তা মনে করতে পারেন)। সাধারণত, আমরা একটি কনভোলিউশন লেয়ারে 1 টি ফিল্টার ব্যবহার করি। আমাদের উদাহরণে যদি 6 ফিল্টার থাকে তবে আমাদের 28 * 28 * 6 আকারের আউটপুট থাকবে।
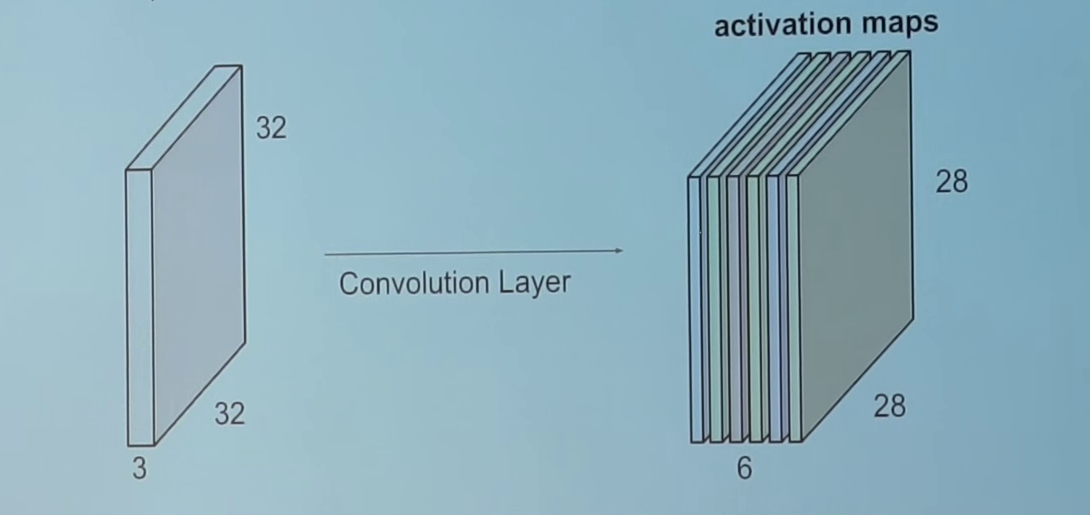
হিসাবে আপনি দেখতে পারেন, প্রতিটি convolution পরে, আউটপুট আকার হ্রাস করা হয় (এই ক্ষেত্রে আমরা 32 * 32 থেকে 28 * 28) যাচ্ছি। অনেক স্তর সহ একটি গভীর স্নায়ুতন্ত্রের মধ্যে আউটপুটটি খুব ছোট হয়ে যাবে, যা খুব ভালভাবে কাজ করে না। সুতরাং, ইনপুট লেয়ারের সীমানাতে জিরোস যোগ করার জন্য এটি একটি আদর্শ অনুশীলন, যেমন ইনপুট স্তর হিসাবে আউটপুট একই আকার। সুতরাং, এই উদাহরণে, যদি আমরা ইনপুট লেয়ারের উভয় পাশে আকার 2 এর প্যাডিং যুক্ত করি, আউটপুট লেয়ারটির আকার 32 * 32 * 6 হবে যা বাস্তবায়ন উদ্দেশ্যেও ভাল কাজ করে। ধরুন আপনার আকার N * N এর একটি ইনপুট আছে, ফিল্টারের আকার F হয়, আপনি S কে stride হিসাবে ব্যবহার করছেন এবং ইনপুটটি 0 পি আকারের P এর সাথে যুক্ত করা হয়। তারপর, আউটপুট আকারটি হবে:
(N-F+2P)/S +1
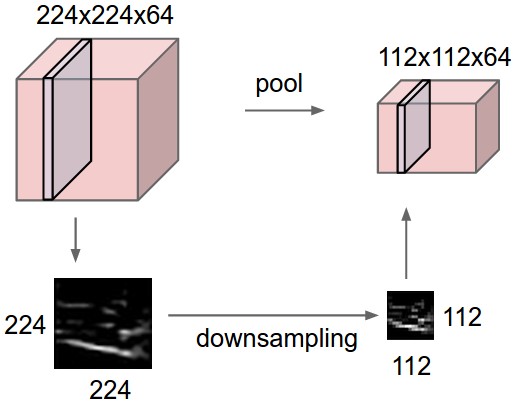
2. পুলিং স্তর:
পুলিং লেয়ারটি ক্রান্তীয় স্তরটিকে স্থানীয় আকার (শুধুমাত্র প্রস্থ এবং উচ্চতা, গভীরতা নয়) হ্রাস করার পরে অবিলম্বে ব্যবহৃত হয়। এটি পরামিতি সংখ্যা হ্রাস করে, তাই গণনা হ্রাস করা হয়। এছাড়াও, কম সংখ্যক পরামিতি অতিরিক্ত ফিরিয়ে এড়াতে পারে (এখন এটি সম্পর্কে চিন্তা করবেন না, এটি পরে একটু বর্ণনা করবে)। পুলিংয়ের সবচেয়ে সাধারণ ফর্ম হচ্ছে সর্বোচ্চ পুকুর যেখানে আমরা আকার F * F ফিল্টার গ্রহণ করি এবং ছবির F * F আকারের অংশে সর্বোচ্চ অপারেশন প্রয়োগ করি।
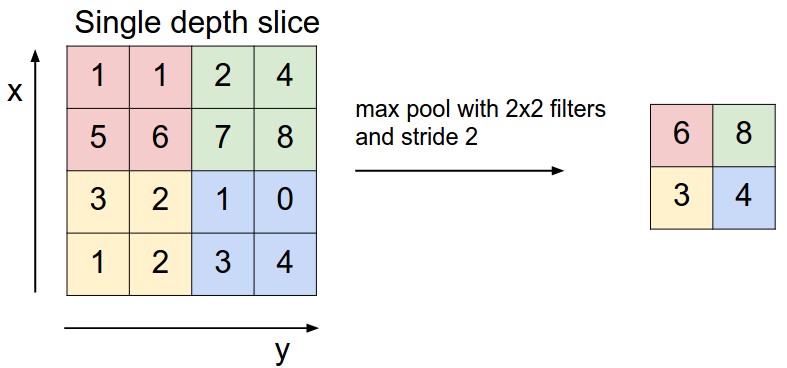
আপনি সর্বাধিক গ্রহণ করার ক্ষেত্রে গড় গ্রহণ করলে, এটি গড় পুলিং বলা হবে, তবে এটি খুব জনপ্রিয় নয়।
আপনার ইনপুট আকার W1 * h1 * d1 এবং ফিল্টারের আকার f * f stride S. এর সাথে থাকে তবে আউটপুট আকার W2 * h2 * d2 হবে:
w2 = (w1-f) / s +1
H2 = (h1-f) / S +1
D2 = D1
সর্বাধিক সাধারণ পুলিংয়ের আকার 2 * ২ এর ফিল্টারের সাথে 2 টি স্তর সহ ফিল্টার করা হয়। আপনি উপরের সূত্রটি ব্যবহার করে গণনা করতে পারেন, এটি মূলত অর্ধেকের মধ্যে ইনপুট আকারকে হ্রাস করে।
3. সম্পূর্ণ সংযুক্ত লেয়ার:
যদি একটি লেয়ারের প্রতিটি নিউরন আগের স্তরটির সমস্ত নিউরনগুলির থেকে ইনপুট পায় তবে এই স্তরটির সম্পূর্ণরূপে সংযুক্ত স্তর বলা হয়। এই স্তরটির আউটপুট বায়াস অফসেট দ্বারা অনুসরণ ম্যাট্রিক্স গুণ দ্বারা গণিত হয়।
প্রশিক্ষণ প্রক্রিয়া বোঝা :
গভীর নৈতিক নেটওয়ার্কগুলি কেবলমাত্র বুদ্ধিমত্তাগুলির গাণিতিক মডেল ছাড়া কিছুই নয় যা নির্দিষ্ট পরিমাণে মানুষের মস্তিষ্কের অনুকরণ করে। যখন আমরা একটি নিউরাল নেটওয়ার্ক ট্রেন করার চেষ্টা করছি, আমাদের দুটি মৌলিক বিষয় আছে যা আমাদের করতে হবে:
The Architecture of the network:নেটওয়ার্ক এর স্থাপত্য:
একটি স্নায়ুতন্ত্রের আর্কিটেকচার ডিজাইন করার সময় আপনাকে সিদ্ধান্ত নিতে হবে: আপনি স্তরগুলি কীভাবে পরিচালনা করবেন? কোন স্তর ব্যবহার করতে? প্রতিটি স্তর ইত্যাদি ব্যবহার করতে কত নিউরন? স্থাপত্য ডিজাইন সামান্য জটিল এবং উন্নত বিষয় এবং গবেষণা অনেক লাগে। অনেক মানক স্থাপত্য আছে যা অনেক মানসম্মত সমস্যার জন্য দুর্দান্ত কাজ করে। উদাহরণস্বরূপ AlexNet, GoogleNet, InceptionResnet, VGG ইত্যাদি উদাহরণস্বরূপ, আপনাকে কেবলমাত্র স্ট্যান্ডার্ড নেটওয়ার্ক আর্কিটেকচারগুলি ব্যবহার করতে হবে। আপনি স্নায়ু জাল সঙ্গে অনেক অভিজ্ঞতা পেতে পরে নেটওয়ার্ক ডিজাইন শুরু করতে পারে। অতএব, এখন এটি সম্পর্কে চিন্তা করবেন না।সঠিক ওজন / পরামিতি:
একবার আপনি নেটওয়ার্ক আর্কিটেকচার সিদ্ধান্ত নিয়েছে; দ্বিতীয় বৃহত্তম পরিবর্তনশীল ওজন (ডাব্লু) এবং পক্ষপাত (বি) বা নেটওয়ার্কের পরামিতি। প্রশিক্ষণের উদ্দেশ্য এই সব পরামিতি, যা নির্ভরযোগ্যভাবে সমস্যা সমাধানের শ্রেষ্ঠ সম্ভাব্য মান পেতে হয়। উদাহরণস্বরূপ, যখন আমরা কুকুর এবং বিড়ালের মধ্যে শ্রেণিবদ্ধ তৈরি করার চেষ্টা করছি, আমরা কুকুর এবং সম্ভাব্য বিড়ালের সমস্ত চিত্রগুলির জন্য আউটপুট লেয়ারটি কুকুরের সম্ভাবনা 1 (বা বিড়ালটির চেয়ে কম উচ্চতর) খুঁজে বের করতে চাই। বিড়ালের সব ছবির জন্য 1 ((বা কুকুরের চেয়ে কমপক্ষে উচ্চতর)।
আপনি পশ্চাদপসরণ প্রচার নামে একটি প্রক্রিয়া ব্যবহার করে পরামিতিগুলির সর্বোত্তম সেটটি খুঁজে পেতে পারেন , অর্থাৎ আপনি প্যারামিটারের একটি সেটের সাথে শুরু করুন এবং এই ওজনগুলি পরিবর্তন করতে থাকুন যাতে প্রতিটি প্রশিক্ষণ চিত্রের জন্য আমরা সঠিক আউটপুট পেতে পারি। সঠিক ওজনগুলি খুঁজে পেতে গণিতগতভাবে দ্রুত ওজনগুলি পরিবর্তন করার জন্য অনেকগুলি অপটিমাইজার পদ্ধতি রয়েছে। গ্রেডিয়েন্টডেসেন্ট হল এমন একটি পদ্ধতি (গ্রেডিয়েন্ট পরিবর্তন করার জন্য পিছন দিকের প্রচার এবং অপটিমাইজার পদ্ধতিগুলি খুব জটিল বিষয়। তবে টেনসফ্লোও এটির যত্ন নেওয়ার জন্য আমাদের এখন চিন্তা করার দরকার নেই)।
সুতরাং, আমরা বলি, আমরা কয়েকটি প্রাথমিক মানের মান শুরু করি এবং কুকুরের 1 টি ট্রেনিং ইমেজ ফিড করি (প্রকৃতপক্ষে একাধিক চিত্র একসঙ্গে খাওয়ানো হয়) এবং আমরা এটি কুকুর হিসাবে 0.9 এর নেটওয়ার্ক আউটপুট গণনা করে এবং এর 0.9। বিড়াল। এখন, আমরা ধীরে ধীরে পরামিতিগুলি পরিবর্তন করতে পারি যা এই চিত্রটির পরবর্তী পরবর্তী পুনরাবৃত্তিতে কুকুরের বৃদ্ধি ঘটানোর সম্ভাবনাকে পরিবর্তিত করে। একটি পরিবর্তনশীল যা প্রশিক্ষণের সময় নেটওয়ার্কটির প্যারামিটারগুলিকে আমরা কত দ্রুত পরিবর্তন করতে পারি, এটি শেখার হার বলা হয়। আপনি যদি এটি সম্পর্কে চিন্তা করেন, আমরা নেটওয়ার্কে মোট সঠিক শ্রেণীবিভাগগুলি বাড়াতে চাই, যাতে আমরা পুরো প্রশিক্ষণ সেটের যত্ন নিই; আমরা এই পরিবর্তনগুলি যেমন নেটওয়ার্ক দ্বারা সঠিক শ্রেণীবিভাগ সংখ্যা বৃদ্ধি করতে চান। সুতরাং আমরা একটি একক সংখ্যা বলা সংজ্ঞায়িত খরচ যা যদি প্রশিক্ষণ ডান দিক যাচ্ছে নির্দেশ করে। সাধারণত খরচ এমন ভাবে সংজ্ঞায়িত করা হয় যে; খরচ হ্রাস করা হয়, নেটওয়ার্কের সঠিকতা বৃদ্ধি পায়। সুতরাং, আমরা খরচ নজর রাখি এবং খরচগুলি হ্রাস না হওয়া পর্যন্ত আমরা এগিয়ে এবং পশ্চাদপসরণ প্রচারগুলির (কখনও কখনও হাজার হাজার দশক) অনেকগুলি পুনরাবৃত্তি চালিয়ে যাচ্ছি। খরচ সংজ্ঞায়িত করার অনেক উপায় আছে। এক সহজ এক মানে রুট বর্গাকার খরচ। চল বলি
সমস্ত প্রশিক্ষণ ইমেজ এবং নেটওয়ার্ক জন্য আউটপুট ধারণকারী ভেক্টর হয়
এবং
এই লেবেলযুক্ত চিত্রগুলির প্রকৃত মান (এছাড়াও স্থল সত্যবলা হয় ) ধারণকারী ভেক্টর । সুতরাং, যদি আমরা এই দুটি ভেরিয়েবলের মধ্যে দূরত্বকে কমিয়ে আনতে পারি তবে এটি প্রশিক্ষণটির একটি ভাল সূচক হবে। সুতরাং, আমরা সব ছবির জন্য এই দূরত্বের গড় হিসাবে খরচ সংজ্ঞায়িত করি:
(
y
−
y
এটি খরচটির একটি খুব সহজ উদাহরণ, কিন্তু প্রকৃত প্রশিক্ষণে আমরা ক্রস-এনট্রপি খরচ মত আরো জটিল খরচ ব্যবস্থা ব্যবহার করি। কিন্তু টেনসফ্লোও এই ব্যয়গুলির অনেকগুলি প্রয়োগ করে তাই এই সময়ে আমাদের এই ব্যয়গুলির বিশদ সম্পর্কে চিন্তা করতে হবে না।
প্রশিক্ষণ সম্পন্ন করার পরে, এই পরামিতি এবং আর্কিটেকচার একটি বাইনারি ফাইল ( মডেল বলা ) সংরক্ষণ করা হবে। যখন আমরা কুকুর / বিড়ালকে শ্রেণীবদ্ধ করার জন্য একটি নতুন চিত্র পাই তখন উত্পাদন সেট আপে আমরা এই মডেলটি একই নেটওয়ার্ক আর্কিটেকচারে লোড করে এবং একটি নতুন বিড়ালের কুকুর / কুকুরের সম্ভাব্যতা গণনা করে। এই অনুমান বা ভবিষ্যদ্বাণী বলা হয় ।
কম্পিউটেশনাল সরলতার জন্য, সমস্ত প্রশিক্ষণের তথ্য একবারে নেটওয়ার্ককে সরবরাহ করা হয় না। এর পরিবর্তে, আমাদের বলুন যে আমাদের মোট 1600 টি চিত্র আছে, আমরা ছোট বাচ্চাদের মধ্যে 16 বা 32 নামক ব্যাচ আকারে ভাগ করে নেব । অতএব, প্রশিক্ষণের জন্য ব্যবহৃত সম্পূর্ণ তথ্যের জন্য এটি 100 বা 50 রাউন্ড ( পুনরাবৃত্তি ) গ্রহণ করবে। এটি একটি যুগ বলা হয় , অর্থাত্ এক যুগে নেটওয়ার্কগুলি সমস্ত প্রশিক্ষণ চিত্র একবার দেখে। সঠিকতা উন্নত করার জন্য আরও কিছু জিনিস আছে তবে একবারে সবকিছু সম্পর্কে চিন্তা করবেন না।
পার্ট -2: টেনসোর্ল্লো টিউটোরিয়াল-> একটি ছোট নিউরাল নেটওয়ার্ক ভিত্তিক ইমেজ ক্লাসিফায়ার তৈরি করা:
এই টিউটোরিয়ালে আমরা যে নেটওয়ার্কটি বাস্তবায়ন করব তা ছোট এবং সহজ (বাস্তব-সমস্যাগুলির সমাধান করার জন্য যেগুলি ব্যবহার করা হয় সেগুলির চেয়ে) যাতে আপনি এটিকে আপনার সিপিইউতেও প্রশিক্ষণ দিতে পারেন। প্রশিক্ষণের সময়, উভয় শ্রেণীর (কুকুর / বিড়াল) চিত্রগুলি একটি সংশ্লেষিক স্তরে খাওয়ানো হয় যা পরবর্তীতে আরো 2 টি সংশ্লেষক স্তরের দিকে। সংশ্লেষিক স্তরগুলির পরে, আমরা আউটপুটটিকে ফ্ল্যাট করে শেষ পর্যন্ত দুটি সম্পূর্ণরূপে সংযুক্ত স্তর যোগ করি। দ্বিতীয় সম্পূর্ণরূপে সংযুক্ত স্তরটিতে কেবল দুটি আউটপুট রয়েছে যা একটি বিড়াল বা কুকুরের মতো চিত্রের সম্ভাব্যতার প্রতিনিধিত্ব করে।

a) Pre-requisites:
i) ওপেনসিভি: বিড়াল / কুকুরের চিত্রগুলি পড়তে আমরা openCV ব্যবহার করি যাতে আপনাকে এটি ইনস্টল করতে হবে।
ii) আকার ফাংশন :
যদি আপনার TF- এ বহু-মাত্রিক টেন্সর থাকে তবে আপনি এটির দ্বারা এটির আকার পেতে পারেন:
আউটপুট হবে: অ্যারে ([16, 128, 128, 3], dtype = int32)
আপনি এটি একটি নতুন 2 ডি টেেন্সার আকারে পুনরায় আকার দিতে পারেন [16 128 * 128 * 3] = [16 49152]।
আউটপুট: অ্যারে ([16, 49152], dtype = int32)
iii) সফটম্যাক্স : একটি ফাংশন যা কে-মাত্রিক ভেক্টর 'x' কে প্রকৃত মান সম্বলিত প্রকৃত মানের সমান ভেক্টর (0,1) এর রেখায় (0,1) রূপে রূপান্তরিত করে, যার সমষ্টি 1. যা আমরা স্যামম্যাক্স ফাংশনটি প্রয়োগ করব প্রতিটি ক্রম জন্য সম্ভাব্য আউটপুট রূপান্তর, যাতে আমাদের convolutional স্নায়ু নেটওয়ার্ক আউটপুট।
class.
b) Reading inputs
আমি Kaggle ডেটাসেট থেকে প্রতিটি কুকুর এবং বিড়াল 2000 ইমেজ ব্যবহার করেছি কিন্তু আপনি বিভিন্ন ধরনের বস্তু ধারণকারী আপনার কম্পিউটারে যে কোন ইমেজ ফোল্ডার ব্যবহার করতে পারে। সাধারণত, আমরা আমাদের ইনপুট ডেটা 3 ভাগে বিভক্ত করি:
- প্রশিক্ষণ তথ্য : আমরা প্রশিক্ষণের জন্য 80% অর্থাৎ 0 ছবি ব্যবহার করব।
- বৈধতা তথ্য : 20% ছবি যাচাই করার জন্য ব্যবহার করা হবে। প্রশিক্ষণ চিত্রের সময় স্বাধীনভাবে নির্ভুলতা গণনা করার জন্য এই ছবিগুলি প্রশিক্ষণ ডেটা থেকে নেওয়া হয়।
- টেস্ট সেট : প্রায় 400 টি চিত্র রয়েছে যা পরীক্ষার জন্য পৃথক স্বাধীন তথ্য। কখনও কখনও Overfitting বলা কিছু কারণে ; প্রশিক্ষণের পরে, স্নায়ু নেটওয়ার্ক প্রশিক্ষণ তথ্য (এবং খুব অনুরূপ চিত্র) উপর খুব ভাল কাজ শুরু করে অর্থাত্ খরচ খুব ছোট হয়ে যায়, তবে তারা অন্যান্য ছবির জন্য ভালভাবে কাজ করতে ব্যর্থ হয়। উদাহরণস্বরূপ, যদি আপনি কুকুর এবং বিড়ালদের মধ্যে একটি শ্রেণীবদ্ধ প্রশিক্ষণ দিচ্ছেন এবং আপনি এমন কোনও ব্যক্তির কাছ থেকে প্রশিক্ষণ ডেটা পান যা সাদা ব্যাকগ্রাউন্ডগুলি সহ সমস্ত ছবি নেয়। এটি সম্ভব যে আপনার নেটওয়ার্কটি এই বৈধতা ডেটা-সেটের উপর খুব ভালভাবে কাজ করে, কিন্তু আপনি যদি এটি কোনও চিত্রের উপর ছদ্মবেশী ব্যাকগ্রাউন্ড দিয়ে চালানোর চেষ্টা করেন তবে এটি সম্ভবত ব্যর্থ হবে। সুতরাং, আমরা কেন একটি স্বাধীন উত্স থেকে আমাদের পরীক্ষা সেট পেতে চেষ্টা।
ডেটাসেট একটি ক্লাস যা আমি ইনপুট ডেটা পড়তে তৈরি করেছি। এটি একটি সহজ পাইথন কোড যা প্রদান করা প্রশিক্ষণ এবং পরীক্ষার ডেটা ফোল্ডার থেকে চিত্রগুলি পড়ে।
আমাদের প্রশিক্ষণের লক্ষ্য হল কুকুর এবং বিড়ালের মধ্যে শ্রেণিবদ্ধকরণের জন্য যে সমস্ত নেটওয়ার্কগুলির মধ্যে নিউরনগুলি কাজ করে, তার জন্য ওজন / পক্ষপাতের সঠিক মানগুলি শিখতে হয়। এই ওজনগুলির প্রাথমিক মূল্য কিছু গ্রহণ করা যেতে পারে তবে স্বাভাবিক বিতরণগুলি (শূন্য শূন্য এবং ছোট বিচ্ছিন্নতা সহ) যদি এটি ভাল হয় তবে এটি আরও ভাল কাজ করে। নেটওয়ার্ক আরম্ভ করার অন্যান্য পদ্ধতি রয়েছে কিন্তু স্বাভাবিক বিতরণ আরও প্রচলিত। চলুন শুরু করে শুধু প্রাথমিক আকৃতি তৈরি করার জন্য ফাংশন তৈরি করে আকৃতিটি উল্লেখ করে (মনে রাখবেন আমরা পূর্ববর্তী পোস্টে truncated_normal ফাংশন সম্পর্কে কথা বলি )।
C) নেটওয়ার্ক স্তর তৈরি করা:
i) টেন্সরফ্লোতে কনভোলিউশন স্তর তৈরি করা:
tf.nn.conv2d ফাংশনটি একটি কনভোলিউশনাল স্তর তৈরি করতে ব্যবহার করা যেতে পারে যা এই ইনপুটগুলি গ্রহণ করে:
ইনপুট = পূর্ববর্তী স্তর থেকে আউটপুট (অ্যাক্টিভেশন)। এটি একটি 4-ডি টেন্সর হওয়া উচিত। সাধারণত, প্রথম সংশ্লেষ স্তরতে, আপনি আকারের প্রস্থ * উচ্চতা * num_channels এর চিত্রগুলি পাস করেন, তারপরে এটি আকার [n প্রস্থ উচ্চতা num_channels]
ফিল্টার = ট্রেলার পরিবর্তনশীল ভেরিয়েবল ফিল্টার। আমরা একটি এলোমেলো স্বাভাবিক বন্টন সঙ্গে শুরু এবং এই ওজন শিখতে। এটি একটি 4 ডি টেন্সর যার নির্দিষ্ট আকৃতিটি নেটওয়ার্ক ডিজাইনের অংশ হিসাবে পূর্বনির্ধারিত। যদি আপনার ফিল্টার আকারের ফিল্টার_সাইজ এবং ইনপুটে খাওয়ানো num_input_channels থাকে এবং আপনার বর্তমান লেয়ারে num_ ফিল্টার ফিল্টার থাকে তবে ফিল্টারটির নিম্নোক্ত আকৃতি থাকবে:
[filter_size ফিল্টার_সাইজ num_input_channels num_filters]
strides = সংকোচন করছেন যখন আপনি আপনার ফিল্টার সরানো কত সংজ্ঞায়িত করে। এই ফাংশনে, এটি আকারের একটি তেন্সর হতে হবে> = 4 অর্থাৎ [batch_stride x_stride y_stride depth_stride]। batch_stride সর্বদা 1 হিসাবে আপনি আপনার ব্যাচ মধ্যে ছবি এড়িয়ে যেতে চান না। x_stride এবং y_stride বেশিরভাগই একই রকম এবং পছন্দটি নেটওয়ার্ক ডিজাইনের অংশ এবং আমরা তাদের উদাহরণে 1 হিসাবে ব্যবহার করব। depth_stride সর্বদা 1 হিসাবে সেট করা হয়েছে যেহেতু আপনি গভীরতা বরাবর এড়িয়ে যান না।
প্যাডিং = SAME মানে আমরা ইনপুটটি 0 প্যাডকে ইনপুট করব যাতে আউটপুট x, y মাত্রা ইনপুট হিসাবে একই।
কনভোলিউশন করার পরে, আমরা সেই নিউরনের পক্ষপাতগুলি যোগ করি, যা শিখতে সক্ষম / প্রশিক্ষনীয়। আবার আমরা এলোমেলো স্বাভাবিক বিতরণ সঙ্গে শুরু এবং প্রশিক্ষণ সময় এই মান শিখতে।
এখন, আমরা tf.nn.max_pool ফাংশন ব্যবহার করে সর্বোচ্চ-পুলিং প্রয়োগ করি যা conv2d ফাংশনের মতো একটি অনুরূপ স্বাক্ষর রয়েছে।
লক্ষ্য করুন যে আমরা x এবং y উভয় দিকের মধ্যে ২ * 2 হিসাবে 2 কে 2 আকার / ফিল্টার_সাইজ ব্যবহার করছি এবং ২। যদি আপনি সূত্রটি ব্যবহার করেন (w2 = (w1-f) / S +1; h2 = (h1-f) / S +1) আগে উল্লেখিত আমরা দেখতে পাই যে আউটপুট ঠিক অর্ধেক ইনপুট। এই সর্বাধিক সাধারন পুলিং জন্য মান ব্যবহার করা হয়।
অবশেষে, আমরা আমাদের সক্রিয়করণ ফাংশন হিসাবে একটি RELU ব্যবহার করি যা কেবল max_pool এর আউটপুট নেয় এবং tf.nn.relu ব্যবহার করে RELU প্রয়োগ করে
এই সমস্ত অপারেশন একটি একক সংকোচন স্তর সম্পন্ন করা হয়। এর একটি সম্পূর্ণ convolutional স্তর সংজ্ঞায়িত করার জন্য একটি ফাংশন তৈরি করা যাক।
ii) সমতল স্তর :
একটি সংশ্লেষ স্তর এর আউটপুট একটি বহু-মাত্রিক টেন্সর। আমরা এটি একটি এক-মাত্রিক টেন্সর রূপান্তর করতে চাই। এই Flattening স্তর সম্পন্ন করা হয়। আমরা কেবল নীচে সংজ্ঞায়িত হিসাবে একটি একক মাত্রিক টেন্সর তৈরি করতে reshape অপারেশন ব্যবহার করুন:
iii) সম্পূর্ণ সংযুক্ত স্তর :
এখন, একটি সম্পূর্ণরূপে সংযুক্ত স্তর তৈরি করার জন্য একটি ফাংশন সংজ্ঞায়িত করা যাক। অন্য কোন লেয়ারের মতোই, আমরা ওজন এবং পক্ষপাতিকে র্যান্ডম স্বাভাবিক বিতরণ হিসাবে ঘোষণা করি। সম্পূর্ণরূপে সংযুক্ত স্তর, আমরা সব ইনপুট গ্রহণ, মান Z = WX + বি অপারেশন এটি উপর। এছাড়াও কখনও কখনও আপনি এটি একটি অ-রৈখিকতা ( RELU ) যোগ করতে চান । সুতরাং, আসুন এমন একটি শর্ত যোগ করি যা কলারকে লেয়ারে RELU যুক্ত করতে দেয়।
সুতরাং, আমরা নেটওয়ার্কের বিল্ডিং ব্লক সংজ্ঞায়িত সমাপ্ত হয়েছে।
iv) স্থানধারক এবং ইনপুট :
এখন, আসুন একটি স্থানধারক তৈরি করি যা ইনপুট প্রশিক্ষণ চিত্রগুলি ধরে রাখবে। সমস্ত ইনপুট চিত্রগুলি dataset.py ফাইলে পড়ানো হয় এবং 128 x 128 x 3 আকারে পুনরায় আকার করা হয়। ইনপুট স্থানধারক x [আকৃতি, 128, 128, 3] আকারে তৈরি করা হয়। প্রথম মাত্রাটি হচ্ছে কেউ না মানে আপনি এটিতে কোনও চিত্র প্রেরণ করতে পারেন। এই প্রোগ্রামের জন্য, আমরা 16 এর ব্যাচের চিত্রগুলি পাস করবো [16 128 128 3]। একইভাবে, আমরা পূর্বাভাস সংরক্ষণের জন্য একটি স্থানধারক y_true তৈরি করি। প্রতিটি চিত্রের জন্য, আমাদের প্রতিটি শ্রেণীর জন্য দুটি আউটপুট রয়েছে। তাই y_pred আকৃতির [none 2] (ব্যাচের আকার 16 এর জন্য এটি হবে [16 2]।
(v) নেটওয়ার্ক ডিজাইন :
আমরা নেটওয়ার্কের বিভিন্ন স্তরের তৈরি করতে উপরের সংজ্ঞায়িত ফাংশন ব্যবহার করি।
vi) ভবিষ্যদ্বাণী :
উপরে উল্লিখিত, আপনি সম্পূর্ণরূপে সংযুক্ত স্তর আউটপুট softmax প্রয়োগ করে প্রতিটি বর্গ সম্ভাবনা পেতে পারেন।
y_pred = tf.nn.softmax(layer_fc2,name="y_pred")
y_pred প্রতিটি ইনপুট ইমেজ জন্য প্রতিটি শ্রেণীর পূর্বাভাস সম্ভাবনা রয়েছে। উচ্চ সম্ভাবনা থাকার ক্লাস নেটওয়ার্ক এর পূর্বাভাস।
y_pred_cls = tf.argmax(y_pred, dimension=1)
এখন, মূল্যের সর্বোত্তম মান পৌঁছানোর জন্য যেটি কমিয়ে আনা হবে তা সংজ্ঞায়িত করা যাক। আমরা সেন্সরফ্লো ফাংশন softmax_cross_entropy_with_logits ব্যবহার করে গণনা করা হবে যা একটি সাধারণ খরচ ব্যবহার করবে যা শেষ পুরোপুরি সংযুক্ত স্তর এবং প্রকৃত লেবেলগুলিকে cross_entropy গণনা করার জন্য আউটপুট নেয়, যার গড় আমাদের খরচ দেবে।
VII) Optimization:
Tensorflow অপ্টিমাইজেশান ফাংশন অধিকাংশ প্রয়োগ। আমরা গ্রিডিয়েন্ট গণনা এবং ওজন অপ্টিমাইজেশনের জন্য অ্যাডমোঅক্সিমিজার ব্যবহার করব। আমরা 0.0001 এর শিক্ষার হারের সাথে খরচ কমানোর চেষ্টা করছি তা নির্দিষ্ট করব।
optimizer = tf.train.AdamOptimizer(learning_rate=1e-4).minimize(cost)
আপনি জানেন যে, আমরা যদি cost.run () এর ভিতরে অপ্টিমাইজার অপারেশন চালান, তাহলে মূল্যের মূল্য গণনা করার জন্য পুরো নেটওয়ার্কটি চালানো হবে এবং আমরা একটি ফিড_ডিক্টে প্রশিক্ষণ চিত্রগুলি প্রেরণ করবো (এটি কি মনে করে? সম্পর্কে, কি পরিবর্তনশীল আপনি খরচ গণনা করা এবং কোড চলতে রাখা প্রয়োজন হবে)।প্রশিক্ষণ প্রতিলিপি প্রতিটি পুনরাবৃত্তি মধ্যে 16 (ব্যাচ_সাইজ) একটি ব্যাচ পাস করা হয়।
next_batch একটি সহজ পাইথন ফাংশন যা dataset.py ফাইলের মধ্যে রয়েছে যা পরবর্তী 16 টি চিত্র প্রশিক্ষণ দেওয়ার জন্য প্রেরণ করে। একইভাবে, আমরা অন্য session.run () কল থেকে স্বাধীনভাবে ছবিগুলির বৈধতা ব্যাচটি পাস করি।
উল্লেখ্য, এই ক্ষেত্রে, আমরা প্রশিক্ষণ চিত্রগুলির বিপরীতে বৈধতা চিত্রগুলির একটি ব্যাচ সহ session.run () এ খরচ প্রেরণ করছি । খরচ গণনা করার জন্য, স্তর (ফন্ট_েন্ট্রপি, হিসাব করার জন্য যা প্রয়োজন) layer_fc2 উত্পাদন করতে পুরো নেটওয়ার্ক (3 কনভোলিউশন + 1 ফ্ল্যাটিন + 2 এফসি স্তর) নির্বাহ করতে হবে। যাইহোক, প্রশিক্ষণের বিরোধিতা হিসাবে, এই সময় অপ্টিমাইজেশান
optimizer = tf.train.AdamOptimizer(learning_rate=1e-4).minimize(cost) চালানো হবে না (আমরা শুধুমাত্র খরচ হিসাব করতে হবে)। এই কি gradients এবং ওজন পরিবর্তন এবং খুব computationally ব্যয়বহুল। আমরা সত্য লেবেল (y_true) এবং পূর্বাভাসযুক্ত লেবেল (y_pred) ব্যবহার করে বৈধতা সেটের সঠিকতা গণনা করতে পারি।
আমরা session.run () এ সঠিকতা পাস করে এবং feed_dict তে যাচাইকরণ চিত্র সরবরাহ করে যাচাইকরণ নির্ভুলতা গণনা করতে পারি।
val_acc = session.run(accuracy,feed_dict=feed_dict_validate)
একইভাবে, আমরা প্রশিক্ষণ ইমেজ জন্য সঠিকতা রিপোর্ট।
acc = session.run(accuracy, feed_dict=feed_dict_train)
হিসাবে, লেবেল সহ বরাবর প্রশিক্ষণ চিত্র প্রশিক্ষণ জন্য ব্যবহার করা হয়, তাই সাধারণ প্রশিক্ষণ সঠিকতা বৈধতা চেয়ে বেশী হবে। আমরা প্রশিক্ষণের নির্ভুলতা রিপোর্ট করতে জানি যে আমরা অন্তত সঠিক পথে এগুচ্ছি এবং অন্তত প্রশিক্ষণ ডেটাসেটের সঠিকতা উন্নত করছি। প্রতিটি ইপোকের পরে, আমরা সঠিকতা সংখ্যাগুলি রিপোর্ট করি এবং টেসফোর্লোতে সেভার অবজেক্ট ব্যবহার করে মডেলটি সংরক্ষণ করি।
সুতরাং, এইভাবে সম্পূর্ণ ট্রেন ফাংশন কেমন দেখাচ্ছে:
এটি একটি বাস্তব বিশ্ব উদাহরণ হিসাবে এই কোড সামান্য দীর্ঘ। সুতরাং, এখানে যান , কোড ক্লোন করুন এবং প্রশিক্ষণ শুরু করতে train.py ফাইলটি চালান। আউটপুট দেখতে কেমন হবে:

এটি একটি ছোট নেটওয়ার্ক এবং চিত্র শ্রেণীবদ্ধকারী তৈরির জন্য অত্যাধুনিক নয় তবে আপনি যখন শুরু করছেন তখন বিশেষভাবে শেখার জন্য এটি খুব ভাল। আমাদের প্রশিক্ষণের জন্য, আমরা যাচাই সেটের উপর 80% এর বেশি সঠিকতা পাই। আমরা প্রশিক্ষণ সময় মডেল সংরক্ষণ হিসাবে, আমরা আমাদের নিজস্ব ইমেজ চালানোর জন্য এই ব্যবহার করা হবে।
Prediction:ভবিষ্যদ্বাণী, গণনা
আপনি প্রশিক্ষণের সাথে সম্পন্ন করার পরে ফোল্ডারে অনেক নতুন ফাইল রয়েছে তা লক্ষ্য করুন:
- কুকুর-বিড়াল-model.meta
- কুকুর-বিড়াল-model.data-00000 অফ 00001
- কুকুর-বিড়াল-model.index
- চেক্পইণ্ট
ফাইল কুকুর-বিড়াল-মডেল.মেটায় সম্পূর্ণ নেটওয়ার্ক গ্রাফ রয়েছে এবং আমরা গ্রাফটি পরে আবার তৈরি করতে ব্যবহার করতে পারি। আমরা এই কাজ করতে Tensorflow দ্বারা উপলব্ধ একটি Saver বস্তু ব্যবহার করা হবে।
ফাইল কুকুর-বিড়াল-মডেল ডায়াল-00000-00001-এর মধ্যে প্রশিক্ষিত ওজন (ভেরিয়েবলের মান) নেটওয়ার্ক রয়েছে। সুতরাং, একবার আমরা গ্রাফ পুনঃনির্মিত করেছি, আমরা ওজনগুলি পুনরুদ্ধার করব।
নেটওয়ার্কে ভবিষ্যদ্বাণী পেতে, আমাদের ইনপুট ইমেজটি একইভাবে (প্রশিক্ষণ হিসাবে) পড়তে এবং প্রাক-প্রক্রিয়া করতে হবে, গ্রাফে y_pred ধরে রাখতে এবং এটি একটি নতুন ফিডের মধ্যে একটি নতুন চিত্র পাস করতে হবে। সুতরাং, আসুন এটা করি:
পরিশেষে, আমরা ভবিষ্যদ্বাণী স্ক্রিপ্ট ব্যবহার করে কুকুর / বিড়ালের একটি নতুন চিত্র চালাতে পারি।
আউটপুট একটি কুকুর বা বিড়াল হচ্ছে ইনপুট ইমেজ এর সম্ভাবনা রয়েছে। এই উদাহরণে, কুকুর হওয়ার সম্ভাবনা বিড়ালের চেয়ে অনেক বেশী।
অভিনন্দন! কনভোলিউশনাল নিউরাল নেটওয়ার্ক ব্যবহার করে আপনি কীভাবে ইমেজ ক্লাসিফায়ার তৈরি এবং প্রশিক্ষণ করবেন তা শিখেছেন।
প্রশিক্ষিত মডেল এবং তথ্য : গিট রেপোজিটরিতে, আমি প্রতিটি ক্লাসের জন্য কেবল 500 টি ছবি যুক্ত করেছি। কিন্তু এটি একটি উপযুক্ত শ্রেণীবদ্ধ প্রশিক্ষক প্রশিক্ষণের জন্য কুকুর / বিড়ালের 500 টিরও বেশি চিত্র নেয়। তাই, আমি প্রতিটি ক্লাসের 2400 ছবিতে এই মডেলটি প্রশিক্ষিত করেছি। আপনি এখানে থেকে এই ছবি ডাউনলোড করতে পারেন। এই মিনি-বিড়াল-কুকুর-ডেটাসেটটি কুকগল কুকুর-বিড়ালের ডেটাসেটের উপসেট এবং আমাদের মালিকানাধীন নয়। আপনি ভবিষ্যদ্বাণী উৎপন্ন করতে এখানে উপলব্ধ আমার প্রশিক্ষিত মডেল ব্যবহার করতে পারেন ।
সম্পূর্ণ কোড এখানে পাওয়া যায় । নীচের মন্তব্যগুলিতে আপনার প্রশ্ন এবং প্রতিক্রিয়া সম্পর্কে আমাকে দয়া করে দিন। এই মন্তব্য এবং মতামত আমার টিউটোরিয়াল তৈরি করতে প্রেরণা হয় 🙂।
অনুশীলনের ব্যায়াম: 1. এটির মজা করার জন্য, আপনি নিজের নিজের ডেটাসেটে অন্য ক্লাসিফায়ারকে প্রশিক্ষণের জন্য একই স্ক্রিপ্টটি ব্যবহার করতে পারেন (প্রতিটি শ্রেণির অন্তত 500 টি চিত্র নিন)। আপনি যে ধরনের সমস্যার চয়ন করেন তার উপর নির্ভর করে আপনি লক্ষ্য করবেন:সমস্যা উপর নির্ভর করে, নমুনা নেটওয়ার্ক ভাল বা খারাপ না। উদাহরণস্বরূপ, যদি আপনি বাইক, এ্যারোপ্লেন এবং কারগুলিতে শ্রেণীবদ্ধকারীকে প্রশিক্ষিত করেন তবে এটি কম প্রশিক্ষণের ডেটা গ্রহণ করবে এবং আপনি উচ্চ নির্ভুলতা পাবেন। কিন্তু যদি আপনি কোন সমস্যাটি কঠিন করে তুলেন তবে আপনাকে অনেক ডেটা দরকার এবং এটি এখনও যথেষ্ট নাও হতে পারে।2. কম্পিউটার দৃষ্টিভঙ্গিতে একটি খুব সাধারণ অনুশীলন তথ্য বৃদ্ধি করা হয়, অর্থাৎ আপনি সামান্য ঘোরতে পারেন, ফসল, জুম-ইন, নতুন প্রশিক্ষণ উদাহরণ তৈরি করতে আসল চিত্রটি ফ্লিপ করুন। এই সাধারণত উন্নত সঠিকতা বাড়ে। অনুশীলনের জন্য, আপনি আবার বৃদ্ধি এবং ট্রেন করতে পারেন, সঠিকতার একই স্তরের পেতে কত সংখ্যক চিত্র দরকার এবং কতটুকু সঠিকতা অর্জন করবে তা চেষ্টা করুন এবং প্রতিবেদন করুন।
0 comments:
Post a Comment