Convolutional স্নায়ু নেটওয়ার্ক চাক্ষুষ স্বীকৃতি কর্মের জন্য চমত্কার।
ভাল ConvNets লক্ষ লক্ষ পরামিতি এবং অনেক লুকানো স্তর সঙ্গে পশু। প্রকৃতপক্ষে, থাম্বের একটি খারাপ নিয়ম হল: 'লুকানো স্তরগুলির সংখ্যা বেশি, নেটওয়ার্কটি ভাল'। AlexNet, VGG, Inception, ResNetটি জনপ্রিয় নেটওয়ার্কগুলির মধ্যে কয়েকটি। কেন এই নেটওয়ার্ক এত ভাল কাজ করে? তারা কিভাবে ডিজাইন করা হয়? তারা তাদের কাঠামো আছে কেন? এক বিস্ময়কর। এই প্রশ্নের উত্তর তুচ্ছ এবং অবশ্যই না, একটি ব্লগ পোস্টে আচ্ছাদিত করা যাবে না। যাইহোক, এই ব্লগে, আমি এই প্রশ্নের কিছু আলোচনা করার চেষ্টা করব। নেটওয়ার্ক আর্কিটেকচার ডিজাইনটি জটিল প্রক্রিয়া এবং আপনার নিজের ডিজাইনার পরীক্ষা করার জন্য আরও কিছু সময় লাগবে। কিন্তু প্রথম, আসুন দৃষ্টিকোণ মধ্যে জিনিস রাখুন:
কেন ConvNets প্রথাগত কম্পিউটার দৃষ্টি বীট হয়?
চিত্র শ্রেণীবিভাগ একটি পূর্বনির্ধারিত বিভাগের মধ্যে একটি প্রদত্ত ইমেজ শ্রেণীবদ্ধ করার কাজ। চিত্র শ্রেণীবদ্ধকরণের জন্য ঐতিহ্যগত পাইপলাইন দুটি মডিউল যুক্ত করে: যেমন। বৈশিষ্ট্য নিষ্কাশন এবং শ্রেণীবিভাগ।
বৈশিষ্ট্য নিষ্কাশন অন্তর্ভুক্ত কাঁচা পিক্সেল মান থেকে উচ্চতর স্তরের তথ্য আহরণ জড়িত যা জড়িত বিভাগের মধ্যে পার্থক্য ক্যাপচার করতে পারেন। এই বৈশিষ্ট্য নিষ্কাশনটি একটি অপ্রয়োজনীয় পদ্ধতিতে সম্পন্ন করা হয় যেখানে চিত্রের ক্লাসগুলিতে পিক্সেল থেকে প্রাপ্ত তথ্যের সাথে কিছু করার নেই। GIST, HOG, SIFT, LBP etc. প্রথাগত ও ব্যাপকভাবে ব্যবহৃত বৈশিষ্ট্যগুলির মধ্যে কয়েকটি বৈশিষ্ট্য রয়েছে। বৈশিষ্ট্যটি বের করার পরে, একটি শ্রেণীবদ্ধকরণ মডিউল চিত্র এবং তাদের সংশ্লিষ্ট লেবেলগুলির সাথে প্রশিক্ষিত হয়। এই মডিউলের কয়েকটি উদাহরণ হলো SVM, Logistic Regression, Random Forest, decision trees etc.
এই পাইপলাইনে সমস্যাটি ক্লাস এবং চিত্র অনুসারে বৈশিষ্ট্য নিষ্কাশনকে tweaked করা যাবে না। সুতরাং যদি নির্বাচিত বৈশিষ্ট্য বিভাগগুলিকে আলাদা করতে প্রতিনিধিত্বের অভাব থাকে তবে শ্রেণীবদ্ধকরণ মডেলের সঠিকতাটি অনেকগুলি ভোগ করে, নির্বিশেষে শ্রেণীবদ্ধ শ্রেণিবিন্যাসের কৌশল প্রয়োগ করা হয়। ঐতিহ্যগত পাইপলাইন অনুসরণ শিল্পের মধ্যে একটি সাধারণ থিম একাধিক বৈশিষ্ট্য extractors বাছাই এবং একটি ভাল বৈশিষ্ট্য পেতে inventively তাদের ক্লাব হয়েছে। কিন্তু এতে সঠিকতা একটি শালীন পর্যায়ে পৌঁছানোর জন্য ডোমেন অনুযায়ী পরামিতি tweak অনেক ম্যানুয়ালিক্স পাশাপাশি ম্যানুয়াল শ্রম জড়িত। শালীন দ্বারা আমি মানে, মানুষের স্তরের সঠিকতা কাছাকাছি পৌঁছেছেন। এটি একটি ভাল কম্পিউটার ভিজ্যুয়াল সিস্টেম (যেমন ওসিআর, মুখ যাচাইকরণ, চিত্র শ্রেণিবদ্ধ, বস্তু সনাক্তকারী ইত্যাদি) নির্মাণের জন্য কয়েক বছর সময় লেগেছে, যা ঐতিহ্যগত কম্পিউটার দৃষ্টিভঙ্গি ব্যবহার করে ব্যবহারিক প্রয়োগের সময় বিভিন্ন ধরণের ডেটা সহকারে কাজ করতে পারে। আমরা একবার 6 সপ্তাহের মধ্যে একটি কোম্পানির (আমার স্টার্ট-আপের একটি ক্লায়েন্ট) জন্য কনভনেটস ব্যবহার করে আরও ভাল ফলাফল উত্পাদিত, যা ঐতিহ্যগত কম্পিউটার দৃষ্টিভঙ্গি ব্যবহার করতে তাদের প্রায় এক বছরের কাছাকাছি লেগেছিল।
এই পদ্ধতির সাথে আরেকটি সমস্যা হল যে আমরা কীভাবে মানুষকে চিনতে শিখি তা থেকে সম্পূর্ণ ভিন্ন। জন্মের পরেই, একটি শিশু তার আশেপাশের অনুভূতি অনুধাবন করতে অসমর্থ, কিন্তু যখন সে ডেটা অগ্রগতি এবং প্রক্রিয়া করে, তখন সেগুলি শনাক্ত করতে শিখতে পারে। এটি গভীর শিক্ষার পিছনে দর্শন, যেখানে কোনও হার্ড কোডেড বৈশিষ্ট্য বিশিষ্টতা তৈরি করা হয় না। এটি একটি সমন্বিত সিস্টেমের মধ্যে নিষ্কাশন এবং শ্রেণীবদ্ধকরণ মডিউলগুলিকে একত্রিত করে এবং এটি চিত্রগুলি থেকে উপস্থাপনাগুলি বৈষম্য দ্বারা বের করে এবং তত্ত্বাবধানে থাকা ডেটা ভিত্তিক শ্রেণিবদ্ধ করে তা শিখতে শিখায়।
এই ধরনের একটি সিস্টেম মাল্টিলেয়ার পেরেকট্রোনস উকান স্নায়ু নেটওয়ার্ক যা একে অপরের সাথে ঘন ঘন সংযুক্ত নিউরনের একাধিক স্তর। একটি গভীর ভ্যানিলা নিউরোল নেটওয়ার্কের মধ্যে এত বড় সংখ্যক পরামিতি রয়েছে যা যথেষ্ট সংখ্যক প্রশিক্ষণ উদাহরণের অভাবের কারণে মডেলটিকে অতিরিক্ততর করে তুললে এমন কোনও সিস্টেমকে প্রশিক্ষণ দেওয়া অসম্ভব। কিন্তু Convolutional নিউরাল নেটওয়ার্ক (ConvNets) সঙ্গে, গোড়া থেকে পুরো নেটওয়ার্ক প্রশিক্ষণ কাজটি মত বৃহৎ ডেটাসেটের ব্যবহার করা যেতে পারে ImageNet। এর পিছনে কারণ হল, সংশ্লেষীয় স্তরগুলিতে নিউরন এবং স্পারস সংযোগগুলির মধ্যে পরামিতি ভাগ করা। এই চিত্রটিতে এটি দেখা যায় 2. কনভোলিউশন ক্রিয়াকলাপে, এক স্তরতে নিউরন কেবল স্থানীয়ভাবে ইনপুট নিউরনগুলির সাথে সংযুক্ত থাকে এবং প্যারামিটার সেটটি 2-ডি বৈশিষ্ট্য মানচিত্র জুড়ে ভাগ করা হয়।
ConvNets এর নকশা দর্শন বুঝতে, একটি জিজ্ঞাসা করা আবশ্যক: এখানে উদ্দেশ্য কি?
ক। সঠিকতা :
আপনি যদি একটি বুদ্ধিমান মেশিন তৈরি করেন তবে এটি সম্পূর্ণরূপে সমালোচনামূলক যে এটি যতটা সম্ভব সঠিক হতে হবে। এখানে জিজ্ঞাসা করা একটি ন্যায্য প্রশ্ন হল, 'নির্ভুলতা কেবল নেটওয়ার্কে নির্ভর করে না বরং প্রশিক্ষণের জন্য উপলব্ধ তথ্যের পরিমাণেও'। অতএব, এই নেটওয়ার্কে ইমেজনেট নামে একটি আদর্শ ডেটাসেটে তুলনা করা হয়।
ImageNet প্রকল্প একটি চলমান প্রচেষ্টা এবং বর্তমানে 21841 বিভিন্ন বিভাগ থেকে 14,197,122 ছবি আছে । ২010 সাল থেকে, ইমেজনেটটি দৃশ্যমান স্বীকৃতিতে বার্ষিক প্রতিযোগিতা চালায় যেখানে অংশগ্রহণকারীরা ইম্যাগনেট ডাটা-সেট থেকে 1000 টি ভিন্ন শ্রেণীর 1.2 মিলিয়ন ছবি সরবরাহ করে। সুতরাং, প্রতিটি নেটওয়ার্ক আর্কিটেকচার 1000 শ্রেণীর এই 1.2 মিলিয়ন চিত্রগুলি ব্যবহার করে নির্ভুলতার প্রতিবেদন করে।
খ। গণনা:
সর্বাধিক ConvNets বিশাল মেমরি এবং গণনা প্রয়োজনীয়তা আছে, বিশেষ করে যখন প্রশিক্ষণ। অতএব, এটি একটি গুরুত্বপূর্ণ উদ্বেগ হয়ে ওঠে। একইভাবে, চূড়ান্ত প্রশিক্ষিত মডেলের আকারটি বিবেচনা করা গুরুত্বপূর্ণ যে আপনি যদি মোবাইলে স্থানীয়ভাবে চালানোর জন্য কোনও মডেল স্থাপন করতে চান। আপনি অনুমান করতে পারেন, আরো সঠিকতা তৈরির জন্য এটি আরও কম্পিউটেশালিটি সন্নিবেশিক নেটওয়ার্ক গ্রহণ করে। সুতরাং, সঠিকতা এবং গণনার মধ্যে সর্বদা একটি বাণিজ্য বন্ধ আছে।
এর পাশাপাশি প্রশিক্ষণের সহজতা, ভালভাবে সাধারণীকরণের জন্য একটি নেটওয়ার্ক এর ক্ষমতা ইত্যাদি অনেকগুলি বিষয় রয়েছে। নীচের বর্ণিত নেটওয়ার্কগুলি সর্বাধিক জনপ্রিয় এবং এটি প্রকাশ করা হয় যাতে তারা প্রকাশিত হয় এবং এর থেকে ক্রমশ আরও ভাল সঠিকতাও পাওয়া যায়। আগের বেশী।
AlexNet
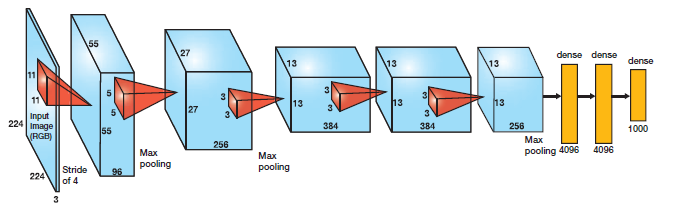
ঐতিহ্যগত পদ্ধতির তুলনায় একটি গুরুত্বপূর্ণ পদক্ষেপ দ্বারা ImageNet শ্রেণীবিভাগ নির্ভুলতা ধাক্কা দেওয়ার জন্য এই আর্কিটেকচারটি প্রথম গভীর নেটওয়ার্কগুলির মধ্যে একটি। চিত্র 1 এ বর্ণিত 5 কনভোলনাল স্তরের সাথে এটি 3 সম্পূর্ণরূপে সংযুক্ত স্তর দ্বারা গঠিত।
অ্যালেক্স ক্রিজেভস্কির প্রস্তাবিত অ্যালেক্সনেট, ঐতিহ্যগত নিউরাল নেটওয়ার্কগুলির পূর্বের মান যা তানহ বা সিগোময়েড ফাংশনের পরিবর্তে অ-রৈখিক অংশের জন্য রেলে (রেখাযুক্ত লিনিয়ার ইউনিট) ব্যবহার করে । ReLu দ্বারা দেওয়া হয়
f (x) = সর্বোচ্চ (0, x)
সিগময়েডের উপর রেলু সুবিধাটি হ'ল এটি পরবর্তীতে তুলনায় অনেক দ্রুত ট্রেন করে কারণ সিজোময়েডের ডেরিভেটিভটি সম্পৃক্ত অঞ্চলে খুব ছোট হয়ে যায় এবং সেই কারণে ওজনগুলির আপডেট প্রায় শেষ হয়ে যায় (চিত্র 4)। এই নির্গমন গ্রেডিয়েন্ট সমস্যা বলা হয় ।
নেটওয়ার্কে, প্রতিটি কনভোলিউশনাল এবং সম্পূর্ণরূপে সংযুক্ত স্তর (FC) পরে রেলে স্তরটি স্থাপন করা হয়।
এই আর্কিটেকচারটি সমাধান করার আরেকটি সমস্যা প্রতিটি FC লেয়ারের পরে একটি ড্রপআউট স্তর ব্যবহার করে ওভার-ফিটিং হ্রাস করা হচ্ছিল । ড্রপআউট লেয়ারটির একটি সম্ভাবনা রয়েছে, (পি) , এটি যুক্ত এবং প্রতিক্রিয়া মানচিত্রের প্রতিটি নিউরনটিতে আলাদাভাবে প্রয়োগ করা হয়। এটি এলোমেলোভাবে সম্ভাব্যতা পিসক্রিয়করণ বন্ধ সুইচ , যেমন চিত্র 5 দেখা যেতে পারে।
DropOut কেন কাজ করে?
ড্রপআউট পিছনে ধারণা মডেল ensembles অনুরূপ। ড্রপআউট লেয়ারের কারণে, নিউরনগুলির বিভিন্ন সেটগুলি বন্ধ করে দেওয়া হয়, এটি একটি ভিন্ন স্থাপত্যের প্রতিনিধিত্ব করে এবং এই সমস্ত বিভিন্ন আর্কিটেকচারগুলি প্রতিটি উপসেটকে ওজন সংক্ষেপে ওজনের সমান্তরালভাবে প্রশিক্ষণ দেওয়া হয়। DropOut যুক্ত এন নিউরনের জন্য, গঠিত উপসেট আর্কিটেকচারগুলির সংখ্যা 2 ^ n। সুতরাং মডেলের এই ensembles উপর গড়ার পূর্বাভাস পরিমাণ। এটি একটি কাঠামোগত মডেল নিয়মিতকরণ সরবরাহ করে যা অতিরিক্ত-ফিটিং এড়িয়ে চলতে সহায়তা করে। DropOut এর আরেকটি দৃশ্য সহায়ক হচ্ছে যেহেতু নিউরনগুলি এলোমেলোভাবে নির্বাচিত হয়, তাই তারা নিজেদের মধ্যে সহ-অভিযোজনগুলি বিকাশ এড়াতে প্রবণ হয় এবং এভাবে তাদের অন্যদের থেকে স্বাধীন অর্থপূর্ণ বৈশিষ্ট্যগুলি বিকাশ করতে সক্ষম হয়।
VGG16
এই স্থাপত্যটি অক্সফোর্ডের ভিজিজি গ্রুপ থেকে এসেছে। এটি একাধিক 3X3 কার্নেল-আকারের ফিল্টারগুলির সাথে একের পর এক বৃহৎ কার্নেল-আকারযুক্ত ফিল্টারগুলি (যথাক্রমে প্রথম এবং দ্বিতীয় ক্রভোল্লিয়াল লেয়ারে 11 এবং 5) প্রতিস্থাপন করে AlexNet এ উন্নতি করে। প্রদত্ত গ্রহনযোগ্য ক্ষেত্র (ইনপুট চিত্রটির কার্যকরী এলাকা আকার যা আউটপুট নির্ভর করে) দিয়ে, একাধিক স্ট্যাক করা ছোট আকারের কার্নেল বৃহত্তর আকারের কার্নেলের তুলনায় ভাল হয় কারণ একাধিক অ-রৈখিক স্তর নেটওয়ার্কটির গভীরতা বাড়ায় যা এটি সক্ষম করে আরো জটিল বৈশিষ্ট্য শিখুন, এবং যে খুব কম খরচে।
উদাহরণস্বরূপ, 3 টি 3 এক্স 3 ফিল্টার একে অপরের উপরে স্ট্রাইড 1 হেক্টর একটি গ্রহণযোগ্য আকারের সাথে 7 টি, তবে জড়িত প্যারামিটারগুলির সংখ্যাটি 7 * আকারের কার্নেলগুলির 49C ^ 2 পরামিতির তুলনায় 3 * (9 সি ^ 2)। এখানে, এটি ধারণ করা হয়েছে যে স্তরগুলির ইনপুট এবং আউটপুট চ্যানেলের সংখ্যা সি। এছাড়াও, 3X3 কার্নেল চিত্রের উন্নততর স্তরগুলির বৈশিষ্ট্যগুলি বজায় রাখতে সহায়তা করে। নেটওয়ার্ক আর্কিটেকচার টেবিলে দেওয়া হয়।
আপনি দেখতে পারেন যে ভিজিজি-ডি-তে, একই জটিল আকারের ব্লক রয়েছে যা আরো জটিল এবং প্রতিনিধিত্বকারী বৈশিষ্ট্যগুলি বের করতে একাধিক বার প্রয়োগ করে। VGG এর পরে নেটওয়ার্কগুলির মধ্যে ব্লক / মডিউলগুলির এই ধারণাটি একটি সাধারণ থিম হয়ে উঠেছে।
ভিজিজি কনভোলিউশন লেয়ার অনুসরণ করে 3 সম্পূর্ণরূপে সংযুক্ত স্তর। নেটওয়ার্কের প্রস্থ 64 এর একটি ছোট মানের দিকে শুরু হয় এবং প্রতিটি উপ-নমুনা / পুলিং লেয়ারের পরে 2 এর একটি ফ্যাক্টর দ্বারা বৃদ্ধি করে। এটি ইমেজনেটে 92.3% এর শীর্ষ -5 নির্ভুলতা অর্জন করেছে।
GoogLeNet / ইনসেপশন:
ভিজিজি ইমেজনেট ডেটাসেটে একটি অসাধারণ নির্ভুলতা অর্জন করেছে, যদিও মেমরি এবং সময় উভয় ক্ষেত্রেই বিশাল কম্পিউটেশনাল প্রয়োজনীয়তাগুলির কারণে এটি সবচেয়ে সাধারণ আকারের জিপিইউগুলিতেও স্থাপন করা একটি সমস্যা। এটি সংকীর্ণ স্তর বৃহৎ প্রস্থ কারণে অক্ষম হয়ে।
উদাহরণস্বরূপ, 3X3 কার্নেল আকার সহ একটি সংশ্লেষক স্তর যা 512 টি চ্যানেলের ইনপুট এবং 512 চ্যানেলের আউটপুট হিসাবে লাগে, হিসাবের ক্রমটি 9 x512X512।
এক অবস্থানে একটি সংশ্লেষমূলক ক্রিয়াকলাপে, প্রতিটি আউটপুট চ্যানেল (উপরের উদাহরণে 512), প্রতিটি ইনপুট চ্যানেলের সাথে সংযুক্ত, এবং তাই আমরা এটি একটি ঘন সংযোগ স্থাপনা হিসাবে কল করি। গুগল লেনিট এই ধারণার উপর ভিত্তি করে তৈরি করে যে গভীর নেটওয়ার্কের মধ্যে বেশিরভাগ অ্যাক্টিভেশনগুলি অপ্রয়োজনীয় (শূন্যের মান) বা তাদের মধ্যে সম্পর্কের কারণে অকার্যকর। অতএব একটি গভীর নেটওয়ার্কের সবচেয়ে কার্যকরী স্থাপত্যের অ্যাক্টিভেশনগুলির মধ্যে একটি স্পারস সংযোগ থাকবে, যা ইঙ্গিত করে যে সব 512 আউটপুট চ্যানেলে 512 টি ইনপুট চ্যানেলের সাথে সংযোগ থাকবে না। এমন সংযোগগুলি ছিনতাই করার কৌশল রয়েছে যার ফলে একটি তীব্র ওজন / সংযোগ স্থাপিত হবে। কিন্তু স্পারস ম্যাট্রিক্স গুণনের জন্য কার্নেলগুলি BLAS বা CuBlas (GPU এর জন্য CUDA) প্যাকেজগুলির মধ্যে অপ্টিমাইজ করা হয় না যা তাদের ঘন প্রতিপক্ষের তুলনায় এমনকি ধীর হতে পারে।
এস ও গুগল লেনেট সেটআপ মডিউল নামক একটি মডিউল তৈরি করেছে যা স্বাভাবিক ঘন নির্মাণের (চিত্রটিতে দেখানো) একটি স্পার সিএনএনকে অনুমান করে। যেহেতু পূর্বে উল্লিখিত নিউরনগুলির একটি ছোট সংখ্যক কার্যকর কার্যকরী কারণ, বিশেষ কার্নেলের আকারের সংশ্লেষক ফিল্টারগুলির প্রস্থ / সংখ্যা ছোট রাখা হয়। এছাড়াও, এটি বিভিন্ন আকারের (5X5, 3X3, 1X1) বিশদ বিবরণ ক্যাপচার করার জন্য বিভিন্ন মাপের ব্যবহার করে।
মডিউল সম্পর্কে আরেকটি উল্লেখযোগ্য বিন্দু এটি একটি তথাকথিত বোতল স্তর (চিত্রে 1 এক্স 1 convolutions) হয়। এটি নিচে ব্যাখ্যা হিসাবে গণনা প্রয়োজনীয়তা ব্যাপক হ্রাস সাহায্য করে।
আসুন আমরা গুগল লেনিনেটের প্রথম সূচনা মডিউলটি উদাহরণ হিসাবে নিই যা 192 টি চ্যানেলকে ইনপুট হিসাবে ব্যবহার করে। এতে মাত্র 3 এক্স 3 কার্নেল আকারের 128 টি ফিল্টার এবং 5X5 আকারের 32 ফিল্টার রয়েছে। 5X5 ফিল্টারের জন্য কম্পিউটিংয়ের অর্ডার 25X32X192 যা নেটওয়ার্কটির প্রস্থ এবং 5X5 ফিল্টারের সংখ্যা বাড়ায় যখন আমরা গভীরভাবে নেটওয়ার্কের মধ্যে যেতে থাকি। এগুলি এড়ানোর জন্য ইনপুট চ্যানেলগুলি ইনপুট চ্যানেলগুলির মাত্রা হ্রাস করার আগে বড় আকারের কার্নেলগুলি প্রয়োগ করার আগে 1x1 দ্রষ্টব্য ব্যবহার করে। তাই প্রথম সূচনা মডিউলটিতে, মডিউলটিতে ইনপুটটিকে প্রথমে 5 এক্স 5 কনভোলিউশনে খাওয়ানোর আগে 16 টি ফিল্টার সহ 1 এক্স 1 কনভোলিউশনগুলিতে খাওয়ানো হয়। এটি 16X192 + 25X32X16 কম্পিউটেশন হ্রাস করে। এই সমস্ত পরিবর্তনগুলি নেটওয়ার্কটিকে একটি বৃহত প্রস্থ এবং গভীরতার অনুমতি দেয়।
GoogLeNet দ্বারা তৈরি আরেকটি পরিবর্তন, সম্পূর্ণরূপে সংহত স্তরের পরিবর্তে একটি সম্পূর্ণ বিশ্বব্যাপী গড় পুলিংয়ের সাথে সম্পূর্ণরূপে সংযুক্ত স্তরগুলিকে প্রতিস্থাপন করা যা শেষ সংকোচকারী স্তর পরে 2D বৈশিষ্ট্যের মানচিত্রের চ্যানেলের মূল্যগুলি গড়ায়। এই ব্যাপকভাবে পরামিতি মোট সংখ্যা হ্রাস। এটি AlexNet থেকে বোঝা যায়, যেখানে FC লেয়ারগুলি প্রায় থাকে। 90% পরামিতি। বৃহৎ নেটওয়ার্ক প্রস্থ এবং গভীরতার ব্যবহারটি গোগেলনিটকে নির্ভুলতা প্রভাবিত না করে FC স্তরগুলি সরাতে দেয়। এটি ইমেজনেটে 93.3% শীর্ষ -5 নির্ভুলতা অর্জন করে এবং এটি VGG এর চেয়ে অনেক দ্রুত।
অবশিষ্ট নেটওয়ার্ক
আমরা যতদূর দেখেছি তার পরিপ্রেক্ষিতে, গভীরতার বৃদ্ধি নেটওয়ার্কটির সঠিকতা বাড়িয়ে তুলতে হবে যতক্ষণ না অতিরিক্ত-ফিটিং যত্ন নেওয়া হয়। কিন্তু গভীরতার সাথে সমস্যাটি হল যে ওজনগুলি পরিবর্তন করার জন্য সংকেত প্রয়োজন, যা স্থল-সত্য এবং ভবিষ্যদ্বাণী তুলনা করে নেটওয়ার্কের শেষ থেকে উদ্ভূত হয় গভীরতার কারণে পূর্বের স্তরগুলিতে খুব ছোট হয়ে যায়। এটি মূলত পূর্ববর্তী স্তর প্রায় শিখেছি শিখেছি মানে। এই অদৃশ্য গ্রেডিয়েন্ট বলা হয় ।গভীর নেটওয়ার্ক প্রশিক্ষণ সহ দ্বিতীয় সমস্যা হচ্ছে, বিশাল পরামিতি স্থানটিতে অপ্টিমাইজেশান সম্পাদন করা এবং সেইজন্য নৈরাশ্য্যে উচ্চতর প্রশিক্ষণের ত্রুটির দিকে অগ্রসর হওয়া স্তরের যোগ করা। রেসিডুয়াল নেটওয়ার্কগুলি এই গভীর নেটওয়ার্কগুলির প্রশিক্ষণকে মডিউলগুলির মাধ্যমে নেটওয়ার্ক গঠন করে চিত্রের মতো অবশিষ্ট মডেল বলা হয়। এই হ্রাস সমস্যা বলা হয় । এটি কেন কাজ করে চারপাশে অন্তর্দৃষ্টি নিম্নলিখিত হিসাবে দেখা যেতে পারে:

একটি নেটওয়ার্ক কল্পনা করুন, একটি যা প্রশিক্ষণ ত্রুটি এক্স পরিমাণ উত্পাদিত। A এর উপরে কয়েকটি স্তর যুক্ত করে একটি নেটওয়ার্ক বি গঠন করুন এবং সেগুলির মধ্যে পরামিতি মানগুলি এমনভাবে রাখুন যাতে তারা এগুলি থেকে আউটপুটগুলিতে কিছুই না করে। আসুন আমরা অতিরিক্ত স্তরকে সি হিসাবে কল করি। এর অর্থ হল প্রশিক্ষণের একই x পরিমাণ নতুন নেটওয়ার্কের জন্য ত্রুটি। সুতরাং যখন প্রশিক্ষণ নেটওয়ার্কের বি, প্রশিক্ষণ ত্রুটি উ: প্রশিক্ষণ ত্রুটি উপরে এবং এটি যেহেতু করা উচিত হবে না শুরু করেঘটবে, একমাত্র কারণ হল পরিচয় ম্যাপিং (ইনপুট করার জন্য কিছুই করা এবং এটির মতো অনুলিপি করা নয়) শেখার সাথে সাথে স্তরগুলি-সি একটি ছোট সমস্যা নয়, যা দ্রাবকটি অর্জন করে না। এটি সমাধান করার জন্য, উপরে দেখানো মডিউলটি পরিচয় ম্যাপিং প্রয়োগকারী মডিউলে ইনপুট এবং আউটপুটের মধ্যে সরাসরি পথ তৈরি করে এবং যোগ করা স্তর-সিটিকে ইতিমধ্যে উপলব্ধ ইনপুট শীর্ষে বৈশিষ্ট্যগুলি শিখতে হবে। যেহেতু সি শুধুমাত্র অবশিষ্টাংশ শিখছে, পুরো মডিউল অবশিষ্ট অবশিষ্ট মডিউল বলা হয় ।
এছাড়াও, গুগল লেনিনেটের অনুরূপ, এটি বৈশ্বিক গড় পুলিং ব্যবহার করে শ্রেণিকরণ স্তর অনুসরণ করে। উল্লিখিত পরিবর্তনগুলির মাধ্যমে, রেজনেটগুলি 152 এর মতো বড় নেটওয়ার্ক গভীরতার সাথে শিখেছিল। ভিজিজিনেটের তুলনায় তুলনামূলকভাবে আরও দক্ষতার সাথে এটি VGGNet এবং GoogLeNet এর চেয়ে ভাল নির্ভুলতা অর্জন করে। ResNet-152 অর্জন করে 95.51 শীর্ষ -5 সংখ্যার।
আর্কিটেকচার VGGNet এর মতোই বেশিরভাগ 3X3 ফিল্টারের মতো। VGGNet থেকে, উপরে বর্ণিত শর্টকাট সংযোগ অবশিষ্ট অবশিষ্ট নেটওয়ার্ক তৈরি করতে সন্নিবেশ করা হয়। এটি ভিজিজি -19 থেকে পূর্বের স্তর সংশ্লেষণের একটি ছোট স্নিপেট দেখায় এমন চিত্রটিতে দেখা যেতে পারে।
অবশিষ্ট নেটওয়ার্কগুলির শক্তি 4 টি পরীক্ষার একটিতে বিচার করা যেতে পারে। প্লেইন 34 লেয়ার নেটওয়ার্কের 18 স্তরগুলির প্লেইন নেটওয়ার্কের চেয়ে বেশি যাচাইকরণ ত্রুটি ছিল। আমরা হ্রাস সমস্যা বুঝতে যেখানে এই। এবং অবশিষ্ট 34 নেটওয়ার্ক নেটওয়ার্ক যখন অবশিষ্ট নেটওয়ার্কের মধ্যে রূপান্তরিত হয় 18 টি স্তর অবশিষ্ট নেটওয়ার্ক তুলনায় অনেক কম প্রশিক্ষণ ত্রুটি।
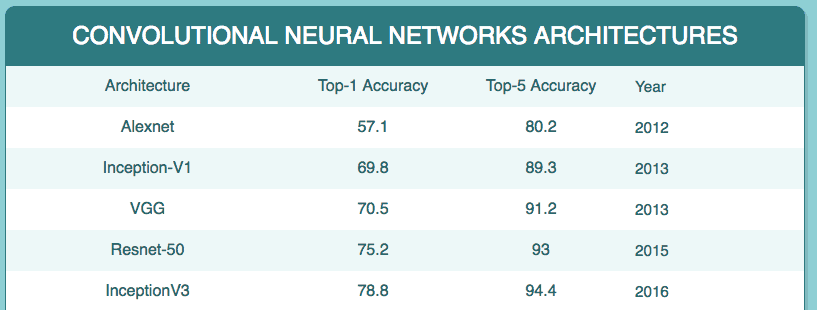
অবশেষে, এখানে একটি টেবিল যা এই নেটওয়ার্কগুলির চারপাশে কী পরিসংখ্যান দেখায়:
আমরা আরো এবং আরো অত্যাধুনিক আর্কিটেকচার ডিজাইন করি, কিছু নেটওয়ার্ক লাইনের নিচে কয়েক বছর প্রাসঙ্গিক থাকতে পারে না তবে মূল নকশাগুলি যেগুলি তাদের ডিজাইনের দিকে পরিচালিত করে তা অবশ্যই বোঝা উচিত। আশা করি, এই নিবন্ধটি আপনাকে নিউরাল নেটওয়ার্ক আর্কিটেকচারের নকশাগুলিতে একটি ভাল দৃষ্টিকোণ সরবরাহ করেছে।
আপডেট: 3 আগস্ট, 2018. একটি তুলনা টেবিল যোগ করা হয়েছে।






0 comments:
Post a Comment