বিমূর্ত
:
এক্সট্রিম লার্নিং মেশিন (ইএলএম) একটি একক স্তর ফিডফর্ডার নিউরাল নেটওয়ার্ক ভিত্তিক শ্রেণিবদ্ধকারী যা তার দ্রুত শেখার গতি এবং শক্তিশালী জেনারালাইজেশনের কারণে কম্পিউটার দৃষ্টি এবং প্যাটার্ন স্বীকৃতিতে উল্লেখযোগ্য মনোযোগ আকর্ষণ করেছে। এই কাগজে, আমরা হাইপারস্পেকট্রাল ইমেজ শ্রেণিবিন্যাসের জন্য বর্ণালী-স্থানীয় তথ্য সংহত করার এবং কর্নেল ভিত্তিক ইএলএম (কেএলএম) শ্রেণিবদ্ধের জন্য স্থানিক বৈশিষ্ট্যগুলি ব্যবহারের সুবিধাগুলি কাজে লাগানোর প্রস্তাব দিই। বিশেষত, গ্যাবরের ফিল্টারিং এবং মাল্টিহোপোথিসিস (এমএইচ) পূর্বাভাস প্রিপ্রোসেসিং হল স্থানিক বৈশিষ্ট্য নিষ্কাশনের জন্য নিযুক্ত দুটি পন্থা। দরকারী স্থানিক তথ্য উপস্থাপনের দক্ষতার কারণে গ্যাবার বৈশিষ্ট্যগুলি বর্তমানে হাইপারস্পেকট্রাল চিত্র বিশ্লেষণের জন্য সফলভাবে প্রয়োগ করা হয়েছে। এমএইচ পূর্বাভাস প্রিপ্রোসেসিং বর্ণালী এবং স্থানিক তথ্য সংহত করতে হাইপারস্পেকট্রাল চিত্রের স্থানিক টুকরা-ধারাবাহিক প্রকৃতির ব্যবহার করে। প্রস্তাবিত গ্যাবোর-ফিল্টারিং-ভিত্তিক কেএলএম শ্রেণিবদ্ধ এবং এমএইচ-প্রেডিকশন-ভিত্তিক কেএলএম শ্রেণিবদ্ধ দুটি দুটি রিয়েল হাইপারস্পেকট্রাল ডেটাসেটে বৈধ হয়েছে। শ্রেণিবিন্যাসের ফলাফলগুলি প্রমাণ করে যে প্রস্তাবিত পদ্ধতিগুলি প্রচলিত পিক্সেল-ভিত্তিক শ্রেণিবদ্ধের পাশাপাশি গ্যাবার-ফিল্টারিং-ভিত্তিক সমর্থন ভেক্টর মেশিন (এসভিএম) এবং এমএইচ-পূর্বাভাস-ভিত্তিক এসভিএমকে ছোট প্রশিক্ষণের নমুনার আকারের শর্তগুলিকে চ্যালেঞ্জ জানায় out
মূলশব্দ:
Gabor filter; hyperspectral image classification; spectral-spatial analysis; kernel extreme learning machine; multihypothesis (MH) prediction1। পরিচিতি
হাইপারস্পেকট্রাল চিত্র (এইচএসআই) চিত্রের প্রতিটি পিক্সেলের জন্য বৈদ্যুতিন চৌম্বকীয় বর্ণমালার বিস্তৃত আকারের প্রতিবিম্বের মানগুলি ক্যাপচার করে। এই সমৃদ্ধ বর্ণালী তথ্য তাদের প্রতিবিম্ব স্বাক্ষরে সূক্ষ্ম পার্থক্য সহ উপকরণগুলি আলাদা বা শ্রেণিবদ্ধকরণের অনুমতি দেয়। পরিবেশগত মানচিত্র, শস্য বিশ্লেষণ, উদ্ভিদ এবং খনিজ অন্বেষণ এবং জৈবিক এবং রাসায়নিক সনাক্তকরণের ক্ষেত্রে অন্যান্যদের মধ্যে এইচএসআই শ্রেণিবিন্যাস অনেকগুলি রিমোট-সেন্সিং অ্যাপ্লিকেশনগুলিতে গুরুত্বপূর্ণ ভূমিকা পালন করে [ 1 ]।
গত দুই দশক ধরে, কৃত্রিম নিউরাল নেটওয়ার্কগুলি (এএনএন) এবং সমর্থন ভেক্টর মেশিনগুলি (এসভিএম) সহ অনেকগুলি মেশিন লার্নিং কৌশলগুলি হাইপারস্পেকট্রাল চিত্রের শ্রেণিবদ্ধকরণে (যেমন, [ 2 - 5 ]) সফলভাবে প্রয়োগ করা হয়েছে । বিশেষত, নিউরাল আর্কিটেকচারগুলি মিক্সড পিক্সেল মডেল করার দুর্দান্ত সম্ভাবনা প্রদর্শন করেছে যা হাইপারস্পেকট্রাল ক্যামেরাগুলির স্বল্প স্থানিক রেজোলিউশন এবং একাধিক স্ক্র্যাটারিংয়ের ফলস্বরূপ [ 3]। তবে, এএনএনগুলির সাথে জড়িত বেশ কয়েকটি সীমাবদ্ধতা রয়েছে যা শিখার অ্যালগরিদম হিসাবে ব্যাক-প্রসারণ অ্যালগরিদম, সর্বাধিক জনপ্রিয় কৌশল ব্যবহার করে। Hyperspectral ডেটার জন্য নিউরাল নেটওয়ার্কের মডেল উন্নয়ন একটি গণনা ব্যয়বহুল পদ্ধতি যেহেতু hyperspectral ইমেজ সাধারণত ভুতুড়ে চ্যানেল [শত শত ত্রিমাত্রিক কিউব হিসাবে প্রতিনিধিত্ব করা হয় 6 ]। এছাড়াও, এএনএনগুলির হাইপারপ্যারামিটার ঘুরিয়ে দেওয়ার জন্য একটি ভাল চুক্তির প্রয়োজন যেমন লুকানো স্তরগুলির সংখ্যা, প্রতিটি স্তরের নোডের সংখ্যা, শেখার হার ইত্যাদি requireসাম্প্রতিক বছরগুলিতে, এসভিএম-ভিত্তিক পদ্ধতিগুলি হাইপারস্পেকট্রাল ইমেজ শ্রেণিবিন্যাসের জন্য ব্যাপকভাবে ব্যবহৃত হয়েছে যেহেতু এসভিএমগুলি প্রায়শই সর্বাধিক সম্ভাবনা এবং মাল্টিলেয়ার পারসেপ্ট্রন নিউরাল নেটওয়ার্ক শ্রেণিবদ্ধ [ 5 ] এর মতো traditionalতিহ্যগত পরিসংখ্যান এবং স্নায়বিক পদ্ধতিগুলিকে ছাড়িয়ে যায় । তদুপরি, এসভিএমগুলি হাইপারস্পেকট্রাল ডেটা শ্রেণিবদ্ধ করার জন্য দুর্দান্ত পারফরম্যান্স প্রদর্শন করেছে যখন তুলনামূলকভাবে কম সংখ্যক লেবেলযুক্ত প্রশিক্ষণের নমুনা পাওয়া যায় [ 4 , 5 , 7 ]। তবে, সর্বোত্তম শ্রেণিবিন্যাসের পারফরম্যান্সের জন্য এসভিএম প্যারামিটারগুলি ( যেমন , নিয়মিতকরণ এবং কর্নেল প্যারামিটার) টিউন করতে হবে।
চরম শেখার মেশিন (ELM) [ 8 ] উদীয়মান শেখার কৌশল হিসাবে একক-লুকানো স্তর ফিড-ফরোয়ার্ড নিউরাল নেটওয়ার্কগুলির (এসএলএফএন) শ্রেণীর অন্তর্ভুক্ত। Ditionতিহ্যগতভাবে, ব্যাক-প্রসারণ অ্যালগরিদমের মতো গ্রেডিয়েন্ট-ভিত্তিক পদ্ধতি এ জাতীয় নেটওয়ার্কগুলি প্রশিক্ষণের জন্য ব্যবহৃত হয়। ইএলএম এলোমেলোভাবে লুকানো নোড প্যারামিটার উত্পন্ন করে এবং বিশ্লেষণাত্মকভাবে পুনরাবৃত্তি টিউনিংয়ের পরিবর্তে আউটপুট ওজন নির্ধারণ করে, যা শিক্ষাকে অত্যন্ত দ্রুত করে তোলে। ইএলএম কেবল গণনামূলকভাবে দক্ষ নয়, এসভিএমগুলির তুলনায় অনুরূপ বা আরও উন্নত সাধারণীকরণের কর্মক্ষমতা অর্জন করতে ঝোঁক। যাইহোক, ইএলএম এলোমেলোভাবে নির্ধারিত ইনপুট ওজন এবং পক্ষপাতিত্বের কারণে একই সংখ্যক লুকানো নোডের সাথে শ্রেণিবিন্যাসের নির্ভুলতার মধ্যে একটি বৃহত প্রকরণ আনতে পারে। ইন [ 9], কার্নেল এক্সট্রিম লার্নিং মেশিন (কেএলএম) যা ইএলএমের লুকানো স্তরটির পরিবর্তে একটি কার্নেল ফাংশন দিয়ে এই সমস্যাটি সমাধান করার প্রস্তাব দেওয়া হয়েছিল। এটি লক্ষণীয় যে কেএলএম-তে ব্যবহৃত কার্নেল ফাংশনটির জন্য মার্সারের উপপাদ্যকে সন্তুষ্ট করার প্রয়োজন হয় না এবং কেইএলএম মাল্টিক্লাস শ্রেণিবদ্ধকরণ সমস্যার জন্য একীভূত সমাধান সরবরাহ করে।
হাইপারস্পেকট্রাল ইমেজ শ্রেণিবিন্যাসের জন্য ইএলএমের ব্যবহার সাহিত্যে মোটামুটি সীমাবদ্ধ। [ 10 ] এ, হাইপারস্পেকট্রাল ইমেজগুলিতে সয়াবিনের বিভিন্ন শ্রেণিবিন্যাসে ELM এবং সর্বোত্তমভাবে ছাঁটাই করা ELM (ওপি-ELM) প্রয়োগ করা হয়েছিল। [ ১১ ] সালে, এলএলটি জমি আচ্ছাদন শ্রেণিবিন্যাসের জন্য ব্যবহৃত হয়েছিল, যা বিবেচিত দুটি ডাটাবেসে ব্যাক-প্রসারণ নিউরাল নেটওয়ার্কের তুলনামূলক শ্রেণিবিন্যাসের যথার্থতা অর্জন করেছিল। KELM ব্যবহার করা হয়েছিল [ 12] মাল্টি- এবং হাইপারস্পেকট্রাল রিমোট-সেন্সিং চিত্রগুলির শ্রেণিবদ্ধকরণের জন্য। ফলাফলগুলি নির্দেশ করে যে শ্রেণিবদ্ধতার নির্ভুলতার ক্ষেত্রে কেএলএম এসভিএমগুলির সাথে সমান বা আরও নির্ভুল এবং উল্লেখযোগ্যভাবে কম গণনা ব্যয় প্রস্তাব করে। তবে, এই কাজগুলিতে, ইএলএম পিক্সেল-ভিত্তিক শ্রেণিবদ্ধ হিসাবে নিয়োগ করা হয়েছিল, যা ইঙ্গিত দেয় যে প্রতিবেশী অবস্থানগুলিতে স্থানিক তথ্য উপেক্ষা করার সময় কেবল বর্ণালি স্বাক্ষর ব্যবহার করা হয়েছে। তবুও, এইচএসআইয়ের পক্ষে এটি অত্যন্ত সম্ভাব্য যে দুটি সংলগ্ন পিক্সেল একই শ্রেণীর অন্তর্ভুক্ত। বর্ণালি এবং স্থানিক উভয় তথ্যের কথা বিবেচনা করে এইচএসআই শ্রেণিবদ্ধকরণের নির্ভুলতা উল্লেখযোগ্যভাবে উন্নত করতে যাচাই করা হয়েছে [ ১৩ , ১৪]। স্থানিক বৈশিষ্ট্যগুলি ব্যবহার করে দুটি প্রধান বিভাগ রয়েছে: কিছু ধরণের স্থানিক বৈশিষ্ট্যগুলি বের করা (যেমন, অঙ্গবিন্যাস, রূপচর্চা প্রোফাইল এবং তরঙ্গপত্র বৈশিষ্ট্য) এবং যৌথ শ্রেণিবিন্যাসের জন্য ছোট্ট পাড়াতে সরাসরি পিক্সেল ব্যবহার করে ধরে নেওয়া যায় যে এই পিক্সেলগুলি একই শ্রেণি ভাগ করে সদস্য। প্রথম বিভাগে (বৈশিষ্ট্যের মাত্রা বৃদ্ধি পেয়েছে), দরকারী স্থানিক তথ্য উপস্থাপনের দক্ষতার কারণে সম্প্রতি গ্যাবার বৈশিষ্ট্যগুলি হাইপারস্পেকট্রাল চিত্রের শ্রেণিবিন্যাসের জন্য সফলভাবে ব্যবহৃত হয়েছে [ 15 - 18 ]। [ 15 , 16 ] এ, 3-ডি গ্যাবার বৈশিষ্ট্যগুলি নিষ্কাশনের জন্য হাইপারস্পেকট্রাল চিত্রগুলিতে ত্রি-মাত্রিক (3-ডি) গ্যাবার ফিল্টার প্রয়োগ করা হয়েছিল; [ 17 , 18 এ)], দ্বি-মাত্রিক (২-ডি) গাবর বৈশিষ্ট্যগুলি একটি মূল উপাদান বিশ্লেষণ (পিসিএ) -প্রজেক্টড সাবস্পেসে আহরণ করা হয়েছিল। আমাদের পূর্ববর্তী কাজ [ 19 ] এ, মাল্টিহোপোথিসিস (এমএইচ) পূর্বাভাসের উপর ভিত্তি করে একটি প্রিপ্রোসেসিং অ্যালগরিদমকে শব্দ-মজবুত হাইপারস্পেকট্রাল চিত্রের শ্রেণিবিন্যাসের বর্ণালী এবং স্থানিক তথ্য একীকরণ করার প্রস্তাব দেওয়া হয়েছিল, যা দ্বিতীয় বিভাগে আসে (বৈশিষ্ট্যের মাত্রা বৃদ্ধি হয়নি)। এছাড়াও, অবজেক্ট-ভিত্তিক-শ্রেণিবদ্ধকরণ পদ্ধতিগুলি (যেমন, [ ২০ - ২২ ]) বর্ণাল-স্থানিক শ্রেণিবদ্ধকরণের জন্যও গুরুত্বপূর্ণ পদ্ধতি। এই পদ্ধতির স্থানগতভাবে সংলগ্ন পিক্সেলগুলিকে সমজাতীয় বস্তুগুলিতে গ্রুপবদ্ধ করে এবং তারপরে ন্যূনতম প্রক্রিয়াকরণ ইউনিট হিসাবে অবজেক্টগুলিতে শ্রেণিবিন্যাস সম্পাদন করে [ 20 ]।
এই কাগজে, আমরা ছোট নমুনা আকারের (এসএসএস) শর্তে কেএলএম শ্রেণিবদ্ধের জন্য স্থানিক বৈশিষ্ট্যগুলি ( অর্থাত গ্যাবার বৈশিষ্ট্য এবং এমএইচ পূর্বাভাস) ব্যবহারের সুবিধাগুলি অনুসন্ধান করি investigate প্রস্তাবিত শ্রেণিবদ্ধকরণ পদ্ধতিটি বৈধকরণের জন্য দুটি প্রকৃত হাইপারস্পেকট্রাল ডেটাসেট নিয়োগ করা হবে। আমরা প্রদর্শন করব যে গ্যাবার-ফিল্টারিং-ভিত্তিক কেএলএম এবং এমএইচ-পূর্বাভাস-ভিত্তিক কেএলএম প্রচলিত পিক্সেল-ভিত্তিক শ্রেণিবদ্ধ (যেমন, এসভিএম এবং কেএলএম) পাশাপাশি গ্যাবার-ফিল্টারিং-ভিত্তিক এসভিএম এবং এমএইচ-পূর্বাভাস-ভিত্তিক ছোট প্রশিক্ষণের নমুনা আকারের শর্তগুলিকে চ্যালেঞ্জ জানাতে এসভিএম। এছাড়াও, প্রস্তাবিত পদ্ধতিগুলি ( যেমন , KELM- ভিত্তিক পদ্ধতিগুলি) SVM- ভিত্তিক পদ্ধতির তুলনায় দ্রুত হয় যেহেতু KELM প্রচলিত SVM এর চেয়ে অনেক দ্রুত শেখার এবং পরীক্ষার গতিতে চালিত হয়।
এই কাগজটির বাকী অংশগুলি নিম্নরূপে সংগঠিত হয়েছে। বিভাগ 2 গ্যাবার ফিল্টার, স্থানিক বৈশিষ্ট্য নিষ্কাশন, কেএলএম শ্রেণিবদ্ধকারী এবং আমাদের প্রস্তাবিত পদ্ধতিগুলির জন্য এমএইচ পূর্বাভাস পেশ করে। বিভাগ 3 হাইপারস্পেকট্রাল ডেটা এবং পরীক্ষামূলক সেটআপের পাশাপাশি প্রস্তাবিত পদ্ধতি এবং কিছু traditionalতিহ্যগত কৌশলগুলির তুলনা উপস্থাপন করে। পরিশেষে, বিভাগ 4 বিভিন্ন উপসংহারমূলক মন্তব্য করে।
2. Spectral-Spatial Kernel Extreme Learning Machine/বর্ণালী-স্থানীয় কার্নেল এক্সট্রিম শেখার মেশিন




2.1। গ্যাবার ফিল্টার
গ্যাবার ফিল্টারগুলি ব্যান্ডপাস ফিল্টার যা বিভিন্ন ইমেজ প্রসেসিং এবং মেশিন ভিশন অ্যাপ্লিকেশনগুলির জন্য সফলভাবে প্রয়োগ করা হয়েছে [ ২৩ - 26]। একটি 2-D গ্যাবার ফাংশন একটি 2-D গাউসিয়ান খাম দ্বারা সংযুক্ত একটি ওরিয়েন্টেড জটিল সাইনোসয়েডাল গ্রেটিং। একটি 2-ডি স্থানাঙ্ক ( a,b ) সিস্টেমে, একটি বাস্তব উপাদান এবং কল্পিত একটি সহ গ্যাবার ফিল্টারটি উপস্থাপিত হতে পারে.

যেখানে [δ] সাইনোসয়েডাল ফ্যাক্টরের তরঙ্গদৈর্ঘ্যকে উপস্থাপন করে এবং [θ] r গ্যাবার কার্নেলের ওরিয়েন্টেশন বিচ্ছিন্নকরণ কোণটি ব্যাখ্যা করেছেন (চিত্র 1)।
নোট করুন যে আমাদের কেবলমাত্র বিরতিতে [θ] বিবেচনা করতে হবে [0 °, 180 °] যেহেতু প্রতিসাম্যতা অন্য দিকগুলিকে অপ্রয়োজনীয় করে তোলে।
[ψ] হ'ল পর্যায়টি অফসেট, [σ] হ'ল গাউসিয়ান খামের মানক উত্স, এবং [γ] স্থানিক দিক অনুপাত (ডিফল্ট মান [২ 27 এর মধ্যে ০.৫]) গ্যাবার ফাংশনের সমর্থনের দীর্ঘায়ু নির্দিষ্ট করে। [ψ = 0 এবং ψ = π / 2 প্রত্যাবর্তন] যথাক্রমে গ্যাবার ফিল্টারটির আসল অংশ এবং কল্পিত অংশ। প্যারামিটার [[δ] এবং স্থানিক ফ্রিকোয়েন্সি ব্যান্ডউইথ BW দ্বারা নির্ধারিত হয়

: 0, π / 8, π / 4, 3 π / 8, π / 2, 5 π / 8, 3 π / 4, এবং 7 π / 8।

2.2। স্থানিক বৈশিষ্ট্য নিষ্কাশন জন্য এমএইচ পূর্বাভাস
আমাদের আগের কাজে [১৯], বর্ণালী-স্থানিক প্রিপ্রোসেসিং অ্যালগরিদম ভিত্তিক [এমএইচ] পূর্বাভাসের প্রস্তাব দেওয়া হয়েছিল। এটি সংক্ষেপে সংবেদনশীল চিত্র এবং ভিডিও পুনর্নির্মাণে এমএইচ পূর্বাভাস প্রয়োগ করার ক্ষেত্রে আমাদের আগের সাফল্য দ্বারা অনুপ্রাণিত হয়েছিল [২৮], একক চিত্রের সুপার-রেজোলিউশন [২৯], এবং এলোমেলো অনুমানগুলি থেকে হাইপারস্পেকট্রাল চিত্র পুনর্গঠন [30] অ্যালগোরিদম এই ধারণা দ্বারা চালিত হয় যে হাইপারস্পেকট্রাল ইমেজের প্রতিটি পিক্সেলের জন্য, এর প্রতিবেশী পিক্সেলগুলি সম্ভবত অনুরূপ বর্ণালী বৈশিষ্ট্যগুলি ভাগ করবে বা একই শ্রেণীর সদস্যতা পাবে কারণ [এইচএসআই] সাধারণত সমজাতীয় অঞ্চল ধারণ করে। সুতরাং, হাইপারস্পেকট্রাল চিত্রের প্রতিটি পিক্সেল তার প্রতিবেশী পিক্সেলের কয়েকটি লিনিয়ার সংমিশ্রণ দ্বারা উপস্থাপিত হতে পারে। বিশেষত, এক পিক্সেল আগ্রহের জন্য একাধিক পূর্বাভাস বা অনুমানগুলি স্থানিকভাবে চারপাশের পিক্সেল থেকে তৈরি করা হয়। এই পূর্বাভাসগুলি তখন যৌগিক পূর্বাভাসের সাথে সংযুক্ত করা হয় যা পিক্সেলটির আগ্রহের কাছাকাছি।
M পিক্সেল সহ একটি হাইপারস্পেকট্রাল ডেটাসেট বিবেচনা করুন [R^N তে

(N বর্ণনামূলক ব্যান্ডের মাত্রা বা সংখ্যা)। x পিক্সেল ইন্টারেস্ট x র জন্য, উদ্দেশ্যটি হ'ল x কে উপস্থাপনের জন্য সম্ভাব্য সমস্ত পূর্বাভাসের একটি অনুকূল লিনিয়ার সংমিশ্রণ সন্ধান করা। অনুকূল উপস্থাপনা হিসাবে সূত্রিত করা যেতে পারে;
 ..............................5
..............................5
এখানে
 এখানে, z [k] একটি অনুমান ম্যাট্রিক্স যাঁর কলামগুলি [k] একটি [d x d] স্থানীয় স্থানের অনুসন্ধান উইন্ডোর মধ্যে [x] এর সমস্ত প্রতিবেশী পিক্সেল থেকে উত্পন্ন অনুমান, এবং [Ŵ ∈ RK × 1] হ'ল ওয়েটিংয়ের একটি ভেক্টর [z] এর [k] অনুমানের সাথে সম্পর্কিত সহগগুণ। বেশিরভাগ ক্ষেত্রে হাইপোথেসির মাত্রিকতা অনুমানের সংখ্যার সমান নয়, [i.e., N ≠ K,] টিখোনভ নিয়মিতকরণ [31] (5) এর সর্বনিম্ন-স্কোয়ার সমস্যাটি নিয়মিত করতে ব্যবহৃত হয়। তারপরে, ওজন ভেক্টর [Ŵ] অনুসারে গণনা করা হয়;
এখানে, z [k] একটি অনুমান ম্যাট্রিক্স যাঁর কলামগুলি [k] একটি [d x d] স্থানীয় স্থানের অনুসন্ধান উইন্ডোর মধ্যে [x] এর সমস্ত প্রতিবেশী পিক্সেল থেকে উত্পন্ন অনুমান, এবং [Ŵ ∈ RK × 1] হ'ল ওয়েটিংয়ের একটি ভেক্টর [z] এর [k] অনুমানের সাথে সম্পর্কিত সহগগুণ। বেশিরভাগ ক্ষেত্রে হাইপোথেসির মাত্রিকতা অনুমানের সংখ্যার সমান নয়, [i.e., N ≠ K,] টিখোনভ নিয়মিতকরণ [31] (5) এর সর্বনিম্ন-স্কোয়ার সমস্যাটি নিয়মিত করতে ব্যবহৃত হয়। তারপরে, ওজন ভেক্টর [Ŵ] অনুসারে গণনা করা হয়;
 ................................6
................................6
যেখানে r হ'ল টিখোনভ ম্যাট্রিক্স এবং λ হ'ল নিয়মিতকরণ প্যারামিটার। r শব্দটি সমাধানটিতে পূর্ববর্তী জ্ঞান আরোপের অনুমতি দেয়। বিশেষত, একটি তির্যক r আকারে ব্যবহৃত হয়
 .................................7
.................................7
যেখানে z 1 ,…, z k হল [z] এর কলাম। [Γ] এর প্রতিটি তির্যক শব্দটি পিক্সেলের আগ্রহ এবং একটি অনুমানের মধ্যে মিলকে পরিমাপ করে। [Γ] এর এই কাঠামোর সাথে, হাইপোথেসিসগুলি যা পিক্সেলের আগ্রহের [x] থেকে আলাদা নয়, সেগুলির তুলনায় কম ওজন দেওয়া হয়। ওজন ভেক্টর [Ŵ] একটি বদ্ধ আকারে গণনা করা যেতে পারে;

অতএব, x , অর্থাৎ পূর্বাভাস করা পিক্সেলের একটি অনুমান হিসাবে গণনা করা হয়

প্রতিটি পিক্সেলের জন্য এক্স , একটি সংশ্লিষ্ট পূর্বাভাস পিক্সেল মাধ্যমে উত্পন্ন করা যেতে পারে ( 9 ) একটি পূর্বাভাস ডেটা সেটটি ফলে
তদুপরি, একবার MHপূর্বাভাসের মাধ্যমে ভবিষ্যদ্বাণী করা ডেটাসেট [X̄] উত্পন্ন হয়,পুনরাবৃত্ত ফ্যাশনে [MH] পূর্বাভাস প্রক্রিয়াটির পুনরাবৃত্তি করতে এটি বর্তমান ইনপুট ডেটাসেট হিসাবে (যেমন, একটি নতুন X) হিসাবে ব্যবহার করা যেতে পারে। পূর্বাভাসযুক্ত ডেটাসেট যা বর্ণালী এবং স্থানিক তথ্যকে কার্যকরভাবে সংহত করে তারপরে শ্রেণিবিন্যাসের জন্য ব্যবহৃত হয়
2.3। Kernel Extreme Learning Machine/কার্নেল এক্সট্রিম লার্নিং মেশিন
ELM মূলত ফিড-ফরোয়ার্ড নিউরাল নেটওয়ার্কগুলি থেকে তৈরি হয়েছিল [ 8 , 32 ] সম্প্রতি, KELM স্পষ্টত অ্যাক্টিভেশন ফাংশন থেকে ইম্পিলিটি ম্যাপিং ফাংশন পর্যন্ত ELM কে সাধারণীকরণ করে, যা বেশিরভাগ অ্যাপ্লিকেশনগুলিতে আরও ভাল জেনারালাইজেশন তৈরি করতে পারে।
C ক্লাস জন্য , আমাদের সংজ্ঞায়িত করি ,Y K ∈ {0,1},1 ≤ K ≤ C । একটি সারি ভেক্টর y = [ y 1 ,…, y k …, y C ] শ্রেণিটি নির্দেশ করে যে কোনও নমুনার অন্তর্ভুক্ত। উদাহরণস্বরূপ, যদি y k = 1 এবং y এর অন্যান্য উপাদানগুলি শূন্য হয়, তবে নমুনাটি Kth শ্রেণীর অন্তর্গত । প্রদত্ত p প্রশিক্ষণের নমুনা

যেখানে x i ∈ R N এবং Y I ∈ R C , L লুকানো নিউরন রয়েছে এমন একটি ELM- র আউটপুট ফাংশন হিসাবে উপস্থাপিত হতে পারে

যেখানে h (·) একটি অরৈখিক অ্যাক্টিভেশন ফাংশন (e.g., Sigmoid function), βi ∈ RC সংযোগ ওজন ভেক্টর হয় j তম গোপন স্নায়ুর এবং আউটপুট নিউরোন, ω j ∈ R N সংযোগ ওজন ভেক্টর হয় j তম লুকানো স্নায়ুর এবং ইনপুট নিউরোন, এবং e j এর পক্ষপাত হয় j তম গোপন স্নায়ুর। ω j · x i ভেতরের পণ্যের উল্লেখ করে ω j । এবং x i । সঙ্গে p সমীকরণ,সমীকরণ (10) হিসাবে নিবিড়ভাবে লেখা যেতে পারে
যেখানে
, এবং H নিউরাল নেটওয়ার্কের লুকানো স্তর আউটপুট ম্যাট্রিক্স:
H=⎡⎣⎢⎢h(x1)⋮h(xP)⎤⎦⎥⎥=⎡⎣⎢⎢h(ω1⋅x1+e1)⋮h(ω1⋅xP+e1)⋯⋱⋯h(ωL⋅x1+eL)⋮h(ωL⋅xP+eL)⎤⎦⎥⎥P×L
H(xi) = (h(ω1 · xi + e1), …, h(ωL · xi + eL)), input xi, এর ক্ষেত্রে লুকানো নিউরনের আউটপুট , যা মানচিত্রগুলি N- মাত্রিক ইনপুট স্থান থেকে L- ডাইমেনশনাল বৈশিষ্ট্য স্পেসে ডেটা to বেশিরভাগ ক্ষেত্রে, লুকানো নিউরনের সংখ্যা প্রশিক্ষণের নমুনাগুলির সংখ্যার চেয়ে অনেক কম, যেমন, ≪ P , সমীকরণের সবচেয়ে ছোট আদর্শ ন্যূনতম-স্কোয়ার সমাধান (11)[ 8 ] এ প্রস্তাবিত হিসাবে সংজ্ঞায়িত করা হয়
β′=H†Y
যেখানে H † হ'ল মুর-পেনরোজ ম্যাট্রিক্স H [ 33 ] এর সাধারণীকরণের বিপরীত । মুর-পেনরোজ সাধারণ বিপরীত এর H হিসাবে গণনা করা যাবে H† = HT (HHT)−1 [ 9 ]। আরও ভাল স্থিতিশীলতা এবং সাধারণীকরণের জন্য, একটি ইতিবাচক মান HHT এর তির্যক উপাদানগুলিতে 1/ρ যুক্ত করা হয় । সুতরাং, আমাদের ELM শ্রেণিবদ্ধের আউটপুট ফাংশন আছে
f(xi)=h(xi)β=h(xi)HT(Iρ+HHT)−1Y
ELM -তে একটি বৈশিষ্ট্য ম্যাপিং h(xi) সাধারণত ব্যবহারকারীদের কাছে পরিচিত। যদি কোনও বৈশিষ্ট্য ম্যাপিং ব্যবহারকারীদের কাছে অজানা থাকে তবে ELM এর জন্য কার্নেল ম্যাট্রিক্সটি নিম্নলিখিত হিসাবে সংজ্ঞায়িত করা যেতে পারে:
ΩELM=HHT:ΩELMq,t=h(xq)⋅h(xt)=K(xq,xt)
সুতরাং, KELM এর আউটপুট ফাংশন হিসাবে লেখা যেতে পারে
ইনপুট ডেটার লেবেল বৃহত্তম মান সহ আউটপুট নোডের সূচক দ্বারা নির্ধারিত হয়।
2.4। Proposed Spectral-Spatial Kernel Extreme Learning Machineপ্র
স্তাবিত স্পেকট্রাল-স্পেশিয়াল কার্নেল এক্সট্রিম লার্নিং মেশিন
একটি গ্যাবার ফিল্টার একটি চিত্রের মধ্যে কোনও অবজেক্টের কিছু শারীরিক কাঠামো ক্যাপচার করতে পারে, যেমন নির্দিষ্ট ওরিয়েন্টেশন সম্পর্কিত তথ্য, একটি স্থানিক কনভ্যুলেশন কার্নেল ব্যবহার করে। পূর্ববর্তী কাজ [ 15 - 18 ] হাইপারস্পেকট্রাল চিত্রের শ্রেণিবিন্যাসের জন্য গ্যাবার ফিল্টারের এক্সট্রাক্ট বর্ণালী-স্থানিক বৈশিষ্ট্য প্রয়োগ করেছে। [ 17 , ১৮ ] এর সাম্প্রতিক গবেষণার পরে , একটি PCA-projected সাব-স্পেসে দরকারী তথ্য ব্যবহার করার জন্য একটি দ্বিমাত্রিক গ্যাবার ফিল্টার হিসাবে বিবেচিত হয়। গ্যাবার বৈশিষ্ট্য এবং মূল বর্ণালী বৈশিষ্ট্যগুলি কেবল সংক্ষেপিত। প্রতিটি স্থানিক বৈশিষ্ট্য (গ্যাবার বৈশিষ্ট্য) ভেক্টর এবং বর্ণালী বৈশিষ্ট্য ভেক্টরকে ইউনিট L 2 রাখার জন্য স্বাভাবিক করা হয়, বৈশিষ্ট্য সংক্ষিপ্তকরণ বা স্ট্যাকিংয়ের আগে আদর্শ। আমরা নোট করি যে ব্যান্ড নির্বাচনের সাথে মূল ব্যান্ডগুলির একটি সাবসেটে গ্যাবার ফিল্টার প্রয়োগ [ 34 ] সমানভাবে নিযুক্ত হতে পারে। গ্যাবার-ফিল্টারিং-ভিত্তিক KELM কে গ্যাবর-KELM হিসাবে চিহ্নিত করা হয়। আমরা MH-এর পূর্বাভাসকে KELM শ্রেণিবদ্ধের প্রিপ্রোসেসিং হিসাবেও নিয়োগ করি, যা MH-KELM হিসাবে চিহ্নিত করা হয়। প্রস্তাবিত বর্ণালী-স্থানীয় KELM
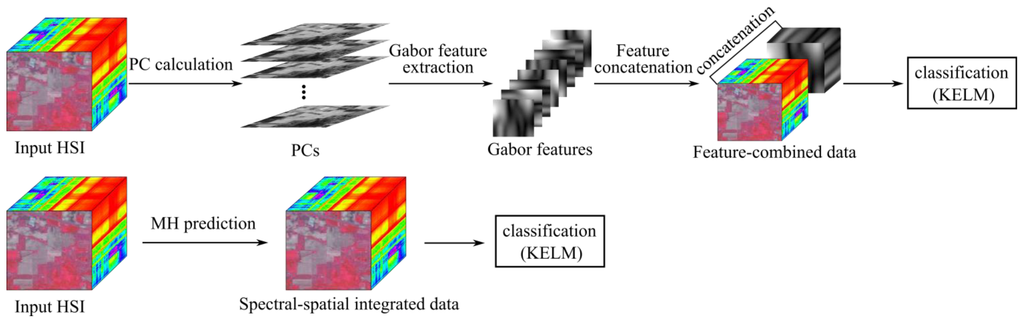
3. পরীক্ষা
এই বিভাগে, আমরা প্রস্তাবিত Gabor-KELM and MH-KELM এর শ্রেণিবিন্যাসের পারফরম্যান্সকে SVM, KELM, Gabor-filtering-based SVM (Gabor-SVM), এবং MH-প্রেডিকশন-ভিত্তিক SVM (Gabor-SVM) এর সাথে তুলনা করি। radial basis function (RBF) কার্নেল সহ SVM lib-svm প্যাকেজ [ 35 ] ব্যবহার করে প্রয়োগ করা হয় । RBF কার্নেল সহ KELM র জন্য, আমরা ELM ওয়েবসাইট [ 36 ] থেকে উপলব্ধ বাস্তবায়নটি ব্যবহার করি ।
3.1। Data Description and Experimental Setupডেটা বর্ণনা এবং পরীক্ষামূলক সেটআপ
আমরা প্রস্তাবিত পদ্ধতিগুলির কার্যকারিতা যাচাই করি, Gabor-KELM and MH-KELM , দুটি two hyperspectral datasets ।আমাদের পরীক্ষায় প্রথম HIS ডেটাসেট NASA’s Airborne Visible/Infrared Imaging Spectrometer (AVIRIS) sensor ব্যবহার করে অর্জিত হয়েছিল এবং জুন 1992 সালে উত্তর-পশ্চিম ইন্ডিয়ানা ইন্ডিয়ান পাইনের পরীক্ষার সাইটে সংগ্রহ করা হয়েছিল।এই দৃশ্যটি 20 মিটারের spatial resolution র সাথে visible and infrared spectrum 0.4–2.45-μm অঞ্চলে 145 × 145 পিক্সেল সহ vegetation-classification র দৃশ্যের প্রতিনিধিত্ব করে।এই ডেটাসেটের জন্য বর্ণালী ব্যান্ডগুলি [{104–108, 150–163, 220}] water-absorption bands are removed র সাথে সামঞ্জস্য করা হয়েছে, 200 বর্ণাল ব্যান্ডের ফলস্বরূপ।মূল ভারতীয় পাইনেস ডেটাসেটটিতে 16 ground-truth land-cover classes রয়েছে।
আমাদের পরীক্ষা-নিরীক্ষায় ব্যবহৃত দ্বিতীয় ডেটাসেট, Pavia বিশ্ববিদ্যালয়, Reflective Optics System Imaging Spectrometer (ROSIS) দ্বারা অর্জিত একটি urban scene [37] চিত্রের দৃশ্য, পাভিয়া শহরটি covering Italy, DLR (the German Aerospace Agency) [38].দ্বারা পরিচালিতHySens project র আওতায় সংগ্রহ করা হয়েছিল . ROSIS সেন্সরটি 0.43 থেকে 0.86μm অবধি 115 টি বর্ণালী ব্যান্ড জেনারেট করে এবং এর পিক্সেলটির স্থানিক রেজোলিউশনটি 1.3 মিটার এবং এতে 610 × 340 পিক্সেল রয়েছে। ডেটাসেটে 12 noisiest bands removed সহ 103 বর্ণালী ব্যান্ড রয়েছে , এই ডেটাসেটের লেবেলযুক্ত স্থল সত্যটি 9 টি শ্রেণীর সমন্বয়ে গঠিত। উভয় ভারতীয় পাইাইন এবং পাভিয়া বিশ্ববিদ্যালয়ের ডেটাসেটের শ্রেণীর বিবরণ এবং নমুনা বিতরণ সারণী 1 এবং 2 তে দেওয়া হয়েছে. উভয় ডেটাসেট, এবং তাদের সম্পর্কিত স্থground truth maps গুলি, Basque University (UPV/EHU) থেকে Computational Intelligence গোষ্ঠীগুলির সর্বজনীনভাবে উপলব্ধ ওয়েবসাইট [39] থেকে প্রাপ্ত। চিত্র 3 এ দুটি ডেটাসেটের False-color images প্রদর্শিত হবে।

চিত্র 3. False-color images: (a) Indian Pines dataset, using bands 10, 20, and 30 for red, green, and blue, respectively; and (b) University of Pavia dataset, using bands 20, 40, and 60 for red, green, and blue, respectively
সারণী 1. ভারতীয় পাইনের ডেটাসেটের জন্য প্রতি শ্রেণির নমুনা।
| Class | Number of Samples | |
|---|---|---|
| No. | Name | |
| 1 | Alfalfa | 46 |
| 2 | Corn-notill | 1428 |
| 3 | Corn-mintill | 830 |
| 4 | Corn | 237 |
| 5 | Grass-pasture | 483 |
| 6 | Grass-trees | 730 |
| 7 | Grass-pasture-mowed | 28 |
| 8 | Hay-windrowed | 478 |
| 9 | Oats | 20 |
| 10 | Soybean-notill | 972 |
| 11 | Soybean-mintill | 2455 |
| 12 | Soybean-clean | 593 |
| 13 | Wheat | 205 |
| 14 | Woods | 1265 |
| 15 | Building-grass-trees-drives | 386 |
| 16 | Stone-steel-towers | 93 |
| Total | 10,249 | |
সারণী 2. পাভিয়া ডেটাসেট বিশ্ববিদ্যালয়ের জন্য প্রতি শ্রেণির নমুনা।
ইন্ডিয়ান পাইনের ডেটাসেটের জন্য,কিছু ক্লাসে কয়েকটি সংখ্যক নমুনা থাকে।উদাহরণস্বরূপ, Oats class তে মাত্র 20 টি নমুনা রয়েছে। আমাদের একটি পরীক্ষায়, আমরা প্রতিটি ক্লাসে নমুনার সংখ্যা অনুসারে 16 ক্লাসটিকে আরোহী ক্রম অনুসারে বাছাই করি এবং শেষ 9 ক্লাসের সাথে পৃথক পরীক্ষা নিরীক্ষা করি, একটি পরিসংখ্যানগত দৃষ্টিকোণ থেকে আরও প্রশিক্ষণের নমুনাগুলির অনুমতি দেয় [5]। নয়টি ক্লাসের শ্রেণীর নম্বরগুলি টেবিল 1 এ boldface হাইলাইট করা হয়েছে। SSS শর্তটি নিম্নলিখিত কাজটিতে আলোচনা করা হবে, এবং আমরা প্রতি ক্লাসে 20 লেবেলযুক্ত নমুনাগুলি (180 Total) নির্বাচন করি, সমস্ত বাম শ্রেণিবদ্ধ করা হবে। প্রতিটি শ্রেণিবিন্যাস পরীক্ষাবিভিন্ন প্রশিক্ষণ এবং পরীক্ষার নমুনাগুলি সহ 10 টি পরীক্ষার জন্য পুনরাবৃত্তি করা হয়, এবং সামগ্রিক শ্রেণিবিন্যাসের নির্ভুলতা গড়ে 10 টি পুনরাবৃত্ত পরীক্ষার গড় হয়। পাভিয়া বিশ্ববিদ্যালয় ডেটাসেট একইভাবে প্রক্রিয়া করা হয়, পার্থক্য হ'ল প্রতিটি পরীক্ষার জন্য আমরা প্রথমে প্রতিটি শ্রেণি থেকে এলোমেলোভাবে 900 টি নমুনা বেছে নিয়েছি প্রতিটি পরীক্ষার জন্য মোট নমুনা সেট (8100 total) গঠনের জন্য। তারপর,শ্রেণিবিন্যাসের জন্য মোট নমুনা সেটের প্রতিটি শ্রেণি থেকে training and testing/প্রশিক্ষণ এবং পরীক্ষার নমুনাগুলি এলোমেলোভাবে বেছে নেওয়া হয়।পাভিয়া ডেটাসেট বিশ্ববিদ্যালয়ের কয়েকটি ক্লাসে অন্যান্য শ্রেণীর তুলনায় উল্লেখযোগ্য পরিমাণে বেশি নমুনা থাকায় এই পদ্ধতিটি ব্যবহৃত হয়, যা পার্থক্য করতে পারে। fair comparison করার জন্য,প্রতি ক্লাসে নমুনার সংখ্যা সমান বা অনুরূপ হতে হবে। সমস্ত পরীক্ষা-নিরীক্ষা মেটল্যাব (SVM ব্যতীত, C তে প্রয়োগ করা হয়) ব্যবহার করে 6 জিবি র্যাম সহ একটি ইন্টেল i7 Quadcore 2.63-GHz machine মেশিনে চালিত হয়।
3.2। প্যারামিটার টিউনিং
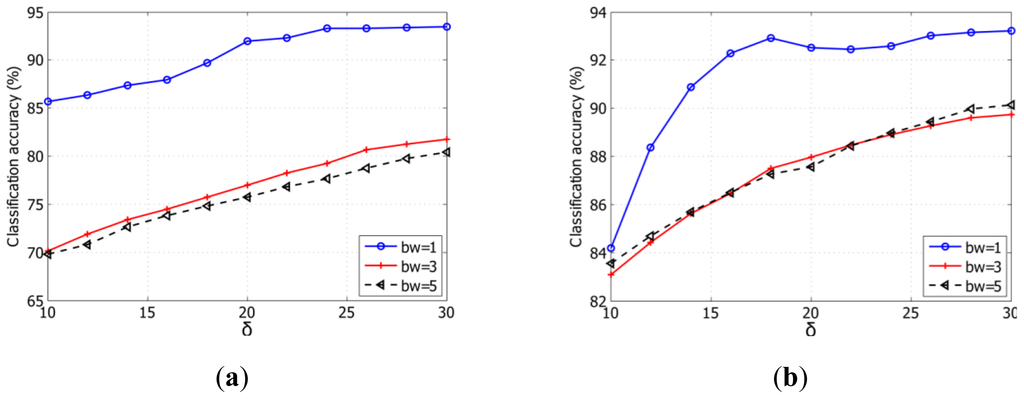
প্রথমত, আমরা হাইপারস্পেকট্রাল ইমেজগুলির জন্য গ্যাবার ফিল্টারের পরামিতিগুলি অধ্যয়ন করি। আমাদের কাজের ক্ষেত্রে, চিত্র 1-এ দেখানো অনুসারে আটটি দিকনির্দেশনা, [0, π/8, π/4,3π/8, π/2,5π/8,3π/4,7π/8,] বিবেচনা করা হয়েছে। সমীকরণ (4) অনুসারে, δ এবং bw হ'ল Gabor filter র two parameter তদন্ত করতে হবে। ইন্ডিয়ান পাইাইনস ডেটাসেটের জন্য চিত্র 4 এ এবং পাভিয়া ডেটাসেট বিশ্ববিদ্যালয়ের জন্য (b) চিত্র 4 অনুসারে আমরা বিভিন্ন δ এবং bw পরীক্ষা করি। চিত্র 4 প্রস্তাবিত গ্যাবর-KELM বনাম বিভিন্ন পরিবর্তনের শ্রেণিবিন্যাসের যথার্থতা - পাশাপাশি bw ওয়ের চিত্র তুলে ধরেছে। নোট করুন যে পরীক্ষায় গ্যাবার-kelm -এর জন্য আমরা উভয় ডেটাসেটের প্রথম 10 প্রধান উপাদান (PCs) নির্বাচন করি, যা চিত্রগুলিতে মোট পরিবর্তনের 99% এর বেশি হয়ে থাকে. ফলাফল থেকে, আমরা সন্তোষজনক সেট করি δ করি এবং পরীক্ষামূলক ডেটাসেটের জন্য যথাক্রমে 26 এবং 1 এ bw set করি।
Figure 4. Classification accuracy (%) versus varying δ and bw for the proposed Gabor-KELM using 20 labeled samples per class for (a) Indian Pines dataset; and (b) University of Pavia dataset.
MH পূর্বাভাসের সাথে জড়িত একটি important parameter হ'ল hypothesis generation নে ব্যবহৃত search-window size d ।আমরা সামগ্রিক শ্রেণিবদ্ধকরণ নির্ভুলতার পাশাপাশি অ্যালগরিদমের কার্য সম্পাদনের সময় অনুসারে অনুসন্ধান-উইন্ডো আকারের প্রভাব বিশ্লেষণ করি।উইন্ডো আকারের একটি সেট, d {{3, 5, 7, 9, 11, 13}, পরীক্ষার জন্য ব্যবহৃত হয়। চিত্র 5 থেকে, আমরা দেখতে পারি যে যখন উইন্ডোর আকার 9 × 9 এবং 13 × 13 এর মধ্যে হয়, তখন শ্রেণিবদ্ধকরণের যথাযথতা একই রকম হয়। আমরা এটিও দেখতে পেলাম যে d = 11 ব্যবহার করা কার্যকরভাবে d = 9 এর কার্যকর সময়ের চেয়ে দ্বিগুণ সময় নেয়, তবে শ্রেণিবদ্ধকরণের নির্ভুলতায় কোনও উল্লেখযোগ্য লাভ দেয় না। বিশেষত, টেবিল 3 বিভিন্ন অনুসন্ধান-উইন্ডো আকারের জন্য MH prediction এক পুনরাবৃত্তির সম্পাদনের সময় দেখায়। সমস্ত পরীক্ষায়, mh পূর্বাভাসের দুটি পুনরাবৃত্তি ব্যবহৃত হয়। আর একটি গুরুত্বপূর্ণ parameter হ'ল সমীকরণের অপ্টিমাইজেশনে (6) Tikhonov regularization/ টিখনোভ নিয়মিতকরণ শব্দটির আপেক্ষিক প্রভাব নিয়ন্ত্রণ করে। অনেক পদ্ধতির সাহিত্যে উপস্থাপন করা হয়েছে - যেমন L -কার্ভ [40], discrepancy principle/তাত্পর্য নীতি, এবং generalized cross-validation (GCV) - যেমন regularization parameter জন্য অনুকূল মান সন্ধান করার জন্য। চিত্র 6 তে বর্ণিত মানগুলির একটি সেট পরীক্ষা করে আমরা এখানে একটি optimal value/অনুকূল find করি MH পূর্বাভাসের জন্য values এর বিভিন্ন মানের সাথে সামগ্রিক শ্রেণিবিন্যাসের নির্ভুলতা উপস্থাপন করে। কেউ দেখতে পাচ্ছেন যে শ্রেণিবিন্যাসের নির্ভুলতা ব্যবধান λ ∈ [1, 2] এর চেয়ে বেশ স্থিতিশীল। ফলস্বরূপ, এখানে প্রতিবেদন করা সমস্ত পরীক্ষায় আমরা λ = 1.5 ব্যবহার করি।
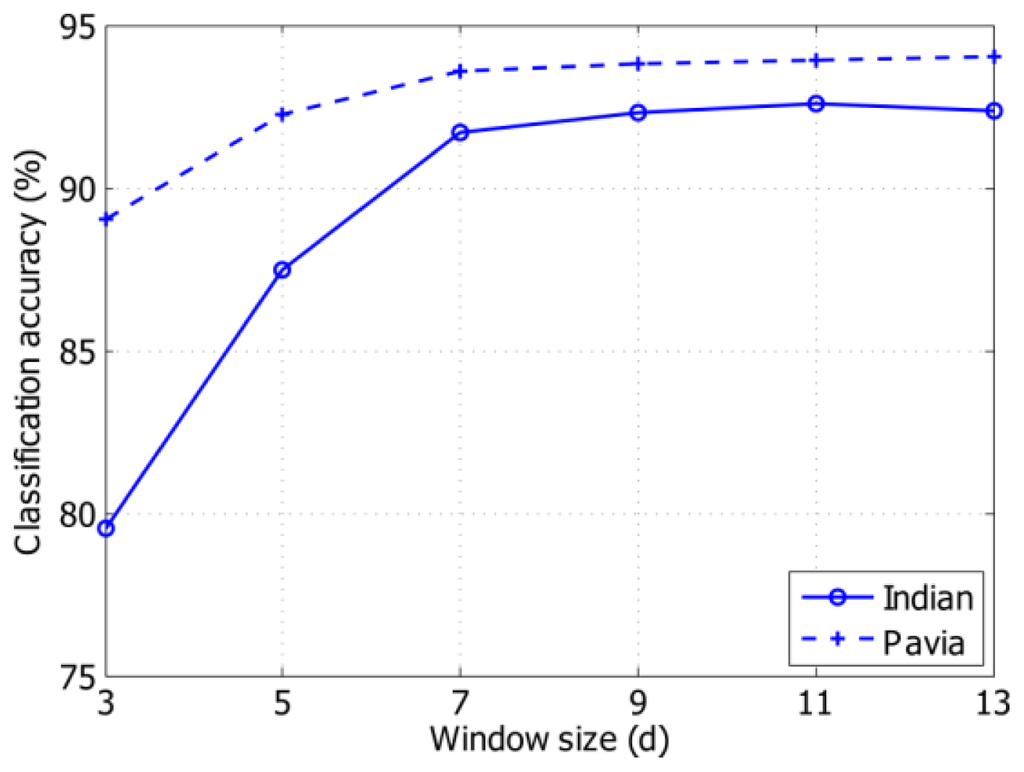
চিত্র 5. প্রস্তাবিত এমএইচ-কেএলএমের জন্য পৃথক দুটি পরীক্ষামূলক ডেটাসেটের জন্য 20 টি লেবেলযুক্ত নমুনা ব্যবহার করে শ্রেণিবিন্যাসের নির্ভুলতা (%) বনাম অনুসন্ধান-উইন্ডো আকার ( ডি ) এর বিপরীতে ।
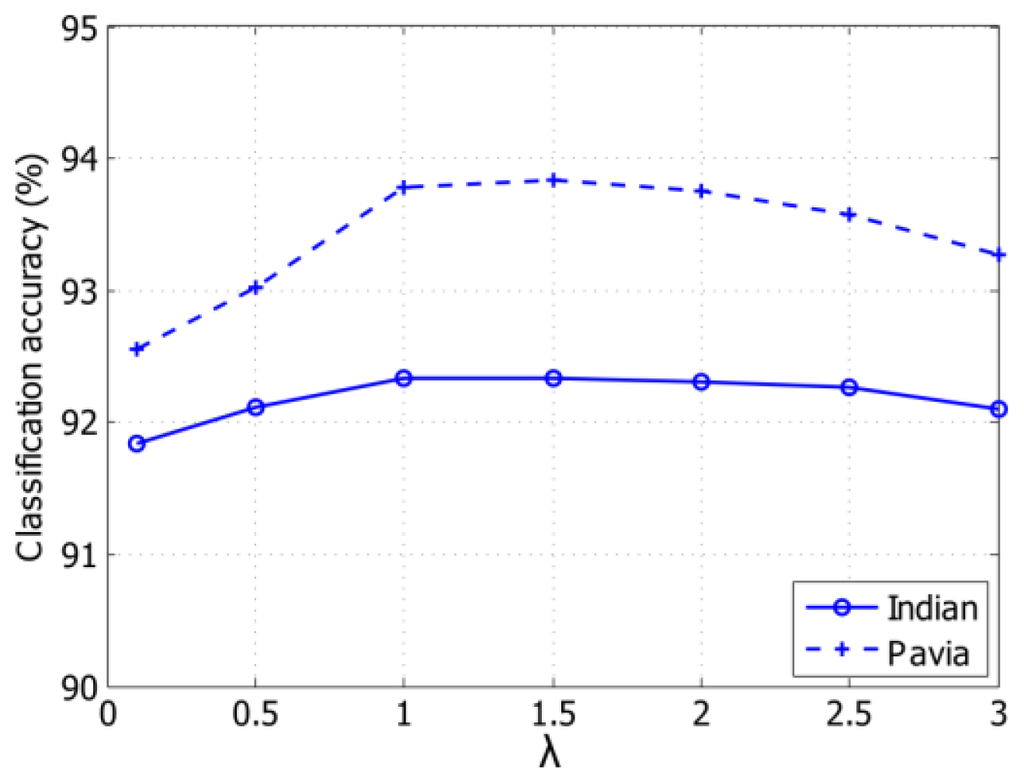
চিত্র 6. এমএইচ-ভবিষ্যদ্বাণী নিয়মিতকরণ প্যারামিটারের একটি ফাংশন হিসাবে ক্লাসিফিকেশন সঠিকতা (%) ভারতীয় পাইন্স এবং বিশ্ববিদ্যালয় Pavia, এর ডেটাসেট জন্য λ প্রস্তাবিত এমএইচ-KELM প্রতি ক্লাসে 20 লেবেল নমুনা ব্যবহার করার জন্য। এমএইচ পূর্বাভাসের জন্য অনুসন্ধান-উইন্ডোর আকার d = 9 × 9।
সারণী 3. অনুসন্ধান উইন্ডো আকারের ফাংশন হিসাবে ইন্ডিয়ান পাইনেস ডেটাসেটের জন্য এমএইচ পূর্বাভাসের এক পুনরাবৃত্তির জন্য কার্যকরকরণের সময় (গুলি) d ।
3.3। শ্রেণিবিন্যাস ফলাফল
হাইপারস্পেকট্রাল ইমেজ শ্রেণিবিন্যাসের মধ্যে SSS সমস্যা হ'ল অন্যতম মৌলিক এবং চ্যালেঞ্জিং সমস্যা। অনুশীলনে, উপলব্ধ লেবেলযুক্ত নমুনার সংখ্যা প্রায়শই হাইপারস্পেকট্রাল চিত্রগুলির জন্য অপর্যাপ্ত। সুতরাং, আমরা বিভিন্ন লেবেলযুক্ত নমুনাগুলির আকার হিসাবে একটি ফাংশন হিসাবে পূর্বোক্ত শ্রেণিবদ্ধদের শ্রেণিবিন্যাসের নির্ভুলতা তদন্ত করি, প্রতি ক্লাসে 20-40 থেকে পৃথক। কোনও পক্ষপাতিত্ব এড়ানোর জন্য, সমস্ত পরীক্ষা 10 বার পুনরাবৃত্তি করা হয়, এবং আমরা গড় শ্রেণিবিন্যাসের যথাযথতার সাথে সংশ্লিষ্ট মানক বিচ্যুতি সম্পর্কে প্রতিবেদন করি। সমস্ত পরীক্ষায়, নির্দিষ্ট নির্দেশ না থাকলে, KELM এর টিউনিং parameters ( RBF kernel parameters) এবং প্রতিযোগী পদ্ধতির parameters গুলির (SVM) ওভার-ফিটিং এড়াতে পাঁচগুণ ক্রস-বৈধকরণের মাধ্যমে প্রশিক্ষণের নির্ভুলতা সর্বাধিক করে তোলা হিসাবে বেছে নেওয়া হয়। প্রস্তাবিত বর্ণালী-স্থানিক ভিত্তিক KELM পদ্ধতিগুলির কার্যকারিতা দুটি পরীক্ষামূলক তথ্যের জন্য টেবিল 4 এবং 5 এ প্রদর্শিত হয়।
Table 4. Overall classification accuracy (%)—mean ± standard deviation over 10 trials using varying number of labeled training samples (ratio represents the proportion of labeled training samples and samples to be classified) per class for the Indian Pines dataset (nine classes).
| Method | Number of Training Samples Per Class (Ratio) | ||
|---|---|---|---|
| 20 (1.99%) | 30 (3.01%) | 40 (4.06%) | |
| SVM | 65.83 ± 2.71 | 71.96 ± 2.20 | 75.67 ± 1.39 |
| KELM | 68.28 ± 2.04 | 72.97 ± 1.47 | 76.02 ± 1.45 |
| Gabor-SVM | 92.74 ± 1.22 | 95.25 ± 1.26 | 96.51 ± 1.05 |
| Gabor-KELM | 93.02 ± 1.08 | 95.44 ± 1.03 | 96.64 ± 1.14 |
| MH-SVM | 87.61 ± 2.01 | 89.91 ± 1.05 | 91.87 ± 0.86 |
| MH-KELM | 92.43 ± 1.89 | 94.87 ± 0.98 | 96.75 ± 0.78 |
Table 5. Overall classification accuracy (%)—mean ± standard deviation over 10 trials using a varying number of labeled training samples (ratio represents the proportion of labeled training samples and samples to be classified) per class for the University of Pavia dataset.
| Method | Number of Training Samples Per Class (Ratio) | ||
|---|---|---|---|
| 20 (2.27%) | 30 (3.45%) | 40 (4.65%) | |
| SVM | 81.11 ± 1.15 | 82.80 ± 0.86 | 84.09 ± 0.63 |
| KELM | 81.21 ± 1.64 | 82.96 ± 0.98 | 84.34 ± 0.64 |
| Gabor-SVM | 90.83 ± 1.11 | 93.45 ± 1.48 | 94.88 ± 0.85 |
| Gabor-KELM | 92.57 ± 1.49 | 94.77 ± 1.26 | 96.07 ± 0.92 |
| MH-SVM | 92.85 ± 0.91 | 94.89 ± 0.74 | 95.74 ± 0.47 |
| MH-KELM | 93.14 ± 1.05 | 95.29 ± 0.68 | 96.31 ± 0.53 |
Gabor-SVMর, SVM র তুলনায় 26.9% উচ্চতর নির্ভুলতা রয়েছে, MH-SVM র SVMর তুলনায় 21.8% বেশি যথার্থতা রয়েছে,Gabor-KELM এর KELM র চেয়ে 24.7% বেশি নির্ভুলতা রয়েছে, এবং MH-KELMর, KELM-র তুলনায় 24.1% উচ্চতর নির্ভুলতা রয়েছে, যখন ভারতীয় পাইনের ডেটাসেটের প্রশিক্ষণের জন্য ক্লাসে 20 লেবেলযুক্ত নমুনা থাকে। তদুপরি, ইন্ডিয়ান পাইনেস ডেটাসেটের জন্য, KELM স্থানিক বৈশিষ্ট্যগুলি নিযুক্ত করে (Gabor features or MH prediction) SVM স্থানিক বৈশিষ্ট্যগুলিকে নিয়োগের চেয়ে আরও ভাল শ্রেণিবিন্যাস সম্পাদন করেছে। বিশেষত MH-পূর্বাভাস-ভিত্তিক পদ্ধতির জন্য, প্রস্তাবিত MH-KELM র যথার্থতা সর্বদা সমস্ত নমুনার আকারে এ MH-SVMর চেয়ে প্রায় 5% বেশি থাকে। পাভিয়া ডেটাসেট বিশ্ববিদ্যালয়ের জন্য, শ্রেণিবদ্ধকরণের নির্ভুলতার শর্তে, গ্যাবর-কেএলএম Gabor-KELM কে ছাড়িয়ে যায় এবং MH-KELM, MH-SVMকে ছাড়িয়ে যায়। এটি লক্ষ্য করা আকর্ষণীয় যে গ্যাবোর-কেএলএমের পারফরম্যান্স উভয় ডেটাসেটের জন্য Gabor-KELM-র খুব কাছাকাছি, যা প্রমাণ করে যে SVMর তুলনায় KELM-র আরও সাধারণীকরণ রয়েছে।
Based on the results shown in Tables 4 and 5, we further perform the standard McNemar’s test [41], which is based on a standardized normal test statistic
Z=f12−f21f12+f21−−−−−−−√
যেখানে f12 শ্রেণীবদ্ধকারী 1 দ্বারা সঠিকভাবে শ্রেণিবদ্ধ হওয়া নমুনাগুলির সংখ্যা এবং একই সাথে শ্রেণিবদ্ধ 2 দ্বারা ভুল শ্রেণিবদ্ধ করে নির্দেশ করে।প্রস্তাবিত পদ্ধতির নির্ভুলতার উন্নতিতে পরিসংখ্যানের তাত্পর্য যাচাই করার জন্য পরীক্ষাটি নিযুক্ত করা হয়।6 এবং ables সারণী প্রস্তাবিত KELM- ভিত্তিক পদ্ধতি এবং Sতিহ্যগত SVM- ভিত্তিক পদ্ধতির মধ্যে পার্থক্য সম্পর্কে মানকৃত ম্যাকনামারের পরীক্ষা থেকে পরিসংখ্যানিক তাত্পর্য উপস্থাপন করে।এই দুটি সারণীতে,শ্রেণিবদ্ধ 1 টি সি 1 হিসাবে শ্রেণিবদ্ধ এবং 2 কে সি 2 হিসাবে চিহ্নিত করা হয়।সারণীতে তালিকাবদ্ধ হিসাবে,দুটি পদ্ধতির মধ্যে যথার্থতার মধ্যে পার্থক্যটি যদি জেড | জেড | 95% আস্থা স্তরে উল্লেখযোগ্যভাবে আলাদাভাবে দেখা হয় to > 1.96 এবং 99% আত্মবিশ্বাসের স্তরে যদি | জেড | > 2.58।তদ্ব্যতীত, জেডের চিহ্নটি শ্রেণিবদ্ধ 1 আউটফর্মফর্ম ক্লাসিফায়ার 2 (জেড> 0) বা বিপরীত কিনা তা নির্দেশ করে।আমরা পর্যবেক্ষণ করতে পারি যে উভয় ডেটাসেটের জন্য ম্যাকনামারের পরীক্ষার সামগ্রিক ফলাফলগুলির সকলের নেতিবাচক চিহ্ন রয়েছে।এটি দেখায় যে কেএলএম-ভিত্তিক পদ্ধতিগুলি এসভিএম-ভিত্তিক পদ্ধতিগুলিকে ছাড়িয়ে যায়,যা টেবিল 4 এবং 5 তে বর্ণিত শ্রেণিবিন্যাসের যথাযথতা থেকে প্রাপ্ত সিদ্ধান্তগুলি নিশ্চিত করে।
Table 6. McNemar’s test (Z ) for the Indian Pines dataset (nine classes, 20 samples per class for training).
| Class | (SVM, KELM)(C1, C2) | (Gabor-SVM, Gabor-KELM)(C1, C2) | (MH-SVM, MH-KELM)(C1, C2) |
|---|---|---|---|
| Hay-windrowed | 1.73 | NaN | NaN |
| Grass-pasture | −0.26 | 2.83 | 2.00 |
| Soybean-clean | 0.32 | 1.51 | 4.56 |
| Grass-trees | −0.76 | −1.41 | −0.77 |
| Corn-mintill | 2.56 | 5.40 | 4.06 |
| Soybean-notill | 1.53 | 2.89 | 6.35 |
| Woods | 2.45 | −1.73 | −0.20 |
| Corn-notill | 3.51 | 4.67 | 8.09 |
| Soybean-mintill | 8.30 | −7.00 | 12.23 |
| Overall | 6.09 | 1.34 | 16.65 |
Table 7. McNemar’s test (Z) for the University of Pavia dataset (180 training and 7920 testing samples)

দুটি ডাট্যাসেটের পুরো দৃশ্যটি ব্যবহার করে আমরা একটি পরীক্ষাও পরিচালনা করি।ইন্ডিয়ান পাইনেস ডেটাসেটের জন্য, আমরা এলোমেলোভাবে প্রতিটি শ্রেণি থেকে 10% নমুনা প্রশিক্ষণের জন্য (16 পরীক্ষাগুলি এই পরীক্ষায় ব্যবহৃত হয়) নির্বাচন করিএবং পরীক্ষার জন্য বাকি।পাভিয়া ডেটাসেট বিশ্ববিদ্যালয়ের জন্য,আমরা প্রশিক্ষণের জন্য প্রতিটি শ্রেণি থেকে 1% নমুনা এবং বাকী পরীক্ষার জন্য ব্যবহার করি। প্রতিটি শ্রেণীর জন্য শ্রেণিবদ্ধকরণ নির্ভুলতা,সামগ্রিক নির্ভুলতা (ওএ),গড় নির্ভুলতা (এএ),এবং কোহেন-দুটি ডেটাসেটের জন্য যথাক্রমে টেবিল 8 এবং 9 এ প্রদর্শিত হবে।টেবিল 8 এবং 9 থেকে দেখা যাবে,প্রস্তাবিত গ্যাবর-কেএলএম এবং এমএইচ-কেএলএমের পিক্সেল-ভিত্তিক শ্রেণিবদ্ধকারী এবং গ্যাবার-এসভিএম এবং এমএইচ-এসভিএমকে ছাড়িয়ে গেছে performanceঅধিক গুরুত্বের সাথে,আমরা দেখতে পারি যে শ্রেণিবদ্ধকরণের জন্য স্থানিক বৈশিষ্ট্যগুলি নিযুক্ত করা এসএসএস শর্তের অধীনে নির্ভুলতার উন্নতি করতে পারে।উদাহরণস্বরূপ, টেবিল 8-এ, ক্লাস 1 (চার প্রশিক্ষণের নমুনা) এর শ্রেণিবিন্যাস যথাযথভাবে নেওয়া,7 (দুটি প্রশিক্ষণের নমুনা) এবং 9 (দুটি প্রশিক্ষণের নমুনা) কেইএলএম শ্রেণিবদ্ধের জন্য স্থানিক তথ্য (যেমন, গ্যাবার বৈশিষ্ট্য বা এমএইচ পূর্বাভাস) একীকরণ করে 40% এরও বেশি উন্নত হয়েছে।প্রশিক্ষণের ডেটা বেশি দামের কারণে,প্রশিক্ষণের ডেটা স্বল্প সংখ্যায় এ জাতীয় কর্মক্ষমতা অনেক অ্যাপ্লিকেশনগুলিতে গুরুত্বপূর্ণ।অতএব, আমরা উপসংহারে পৌঁছেছি যে প্রস্তাবিত গ্যাবর-কেএলএম এবং এমএইচ-কেএলএম হ'ল এসএসএস শর্তে হাইপারস্পেকট্রাল ডেটা বিশ্লেষণ কর্মের জন্য খুব কার্যকর শ্রেণিবিন্যাসের কৌশল।চিত্রগুলি 7 এবং 8 ইন্ডিয়ান পাইনেস ডেটাসেট (লেবেলযুক্ত পিক্সেল সহ 145 × 145) এবং পাবিয়া ডেটাসেট (610 × 340, লেবেলযুক্ত পিক্সেল সহ) জন্য পুরো এইচএসআই দৃশ্যের সাহায্যে উত্পন্ন শ্রেণিবিন্যাসের মানচিত্রের একটি ভিজ্যুয়াল পরিদর্শন সরবরাহ করে,যথাক্রমে। দুটি পরিসংখ্যান হিসাবে দেখানো হয়েছে, বর্ণাল-স্থানিক ভিত্তিক শ্রেণিবদ্ধকরণ পদ্ধতির শ্রেণিবদ্ধকরণ মানচিত্রগুলি পিক্সেল-ভিত্তিক শ্রেণিবদ্ধকরণ পদ্ধতি থেকে উত্পন্ন মানচিত্রের চেয়ে কম গোলমাল এবং আরও নির্ভুল।তদ্ব্যতীত বর্ণাল-স্থানিক ভিত্তিক শ্রেণিবদ্ধকরণ পদ্ধতিগুলি পিক্সেল-ভিত্তিক শ্রেণিবদ্ধকরণ পদ্ধতির চেয়ে আরও ভাল স্থানগত এককতার প্রদর্শন করে।এই একজাতীয়তা প্রায় প্রতিটি লেবেলযুক্ত অঞ্চলে পর্যবেক্ষণযোগ্য।
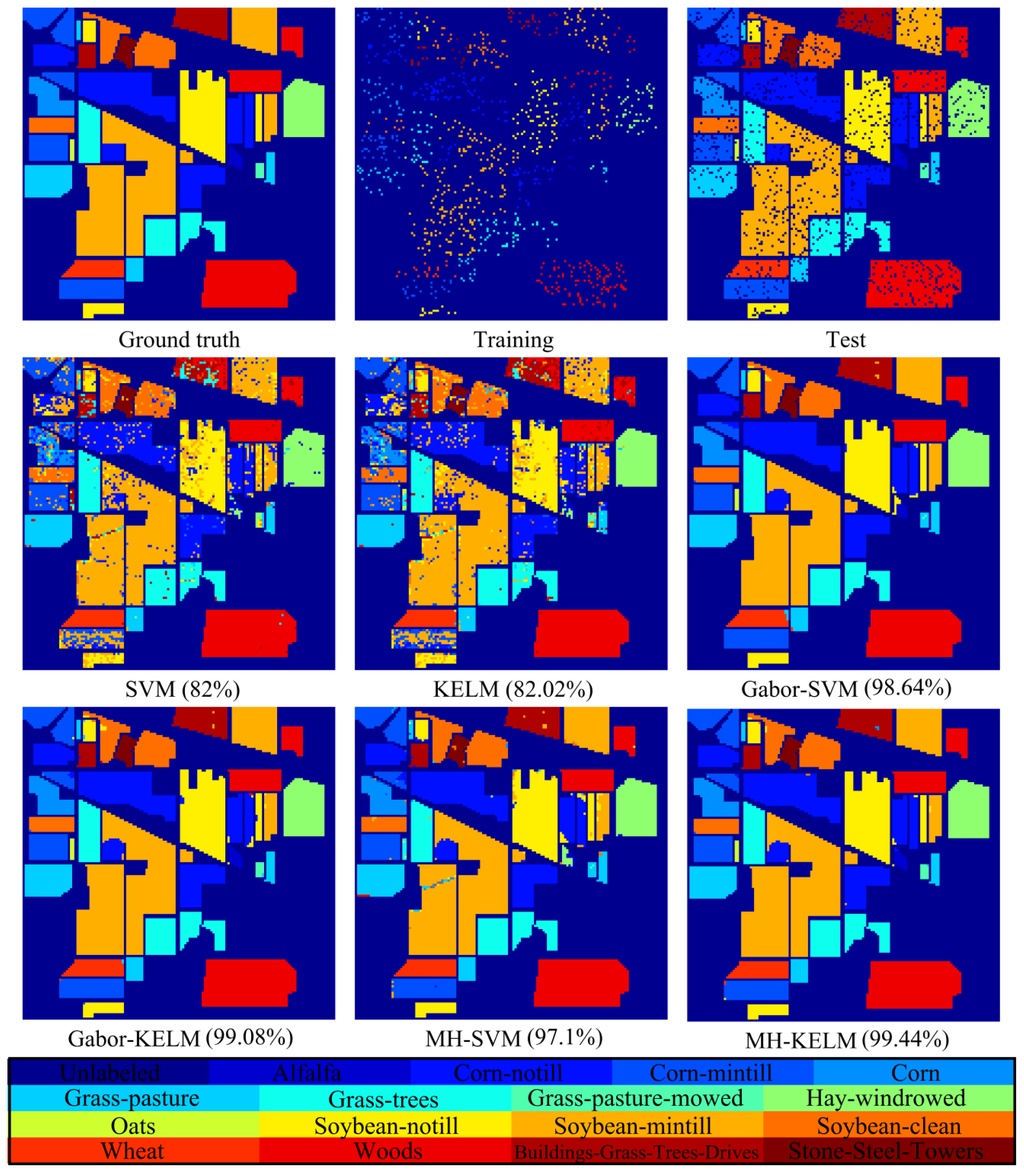
Figure 7. Thematic maps resulting from classification using 1018 training samples (10% per class) for the Indian Pines dataset with 16 classes. The overall classification accuracy of each algorithm is indicated in parentheses.
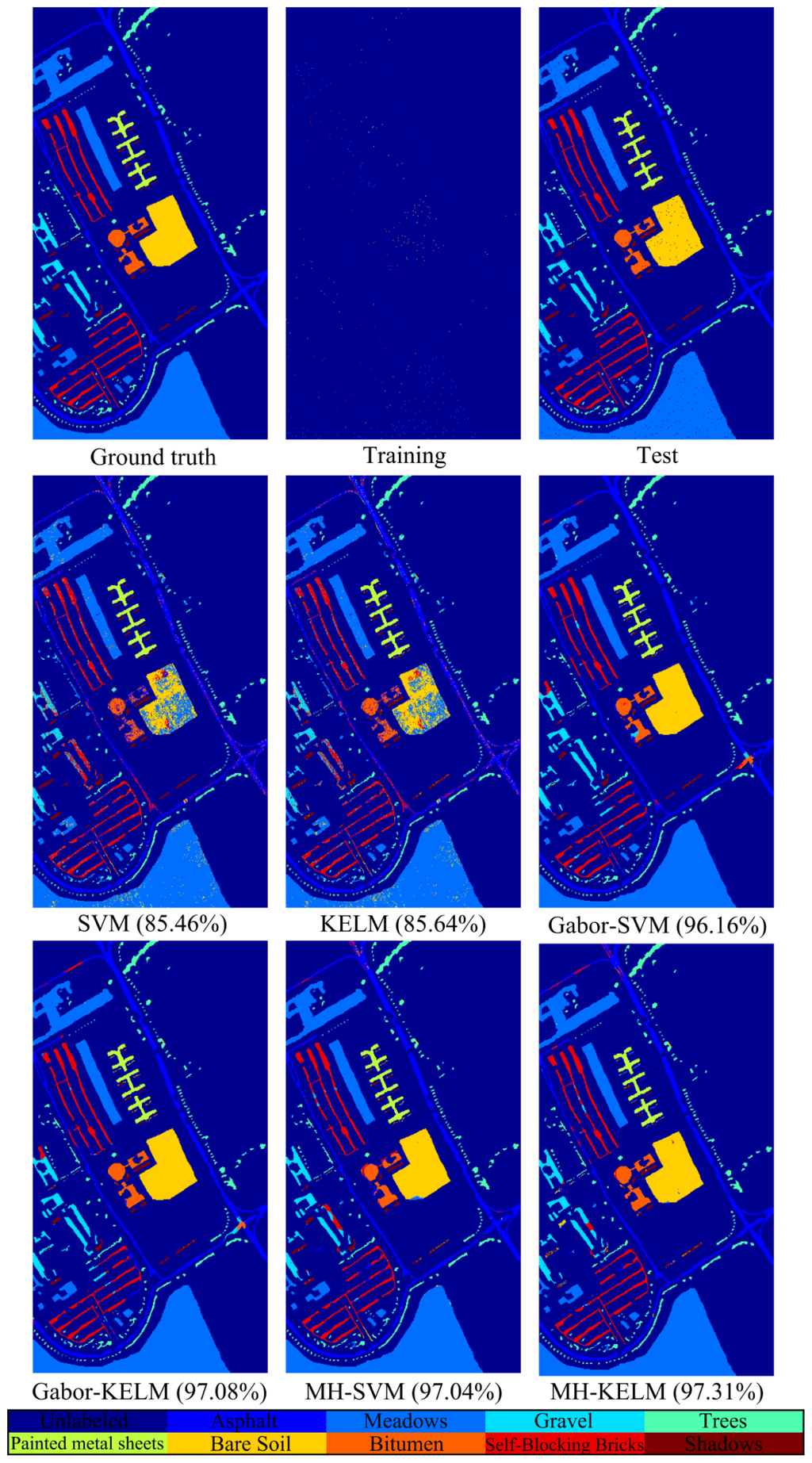
Figure 8. Thematic maps resulting from classification using 423 training samples (1% per class) for the University of Pavia dataset. The overall classification accuracy of each algorithm is indicated in parentheses.
সারণী 8. ভারতীয় পাইনের ডেটাসেটের জন্য শ্রেণিবদ্ধকরণের নির্ভুলতা (%) (16 শ্রেণি)।
| Class | Samples | SVM | KELM | Gabor-SVM | Gabor-KELM | MH-SVM | MH-KELM | |
|---|---|---|---|---|---|---|---|---|
| Train | Test | |||||||
| Alfalfa | 4 | 42 | 57.14 | 54.76 | 64.29 | 97.62 | 26.19 | 90.48 |
| Corn-notill | 142 | 1286 | 78.85 | 81.03 | 98.76 | 98.68 | 97.43 | 98.99 |
| Corn-mintill | 83 | 747 | 62.25 | 62.78 | 97.86 | 98.39 | 96.12 | 99.06 |
| Corn | 23 | 214 | 50.00 | 53.74 | 98.13 | 99.07 | 96.26 | 99.53 |
| Grass-pasture | 48 | 435 | 93.56 | 90.80 | 99.54 | 100 | 97.47 | 100 |
| Grass-trees | 73 | 657 | 95.28 | 95.28 | 100 | 100 | 99.70 | 100 |
| Grass-pasture-mowed | 2 | 26 | 0 | 42.31 | 0 | 92.31 | 0 | 96.15 |
| Hay-windrowed | 47 | 431 | 96.29 | 98.84 | 100 | 100 | 99.30 | 100 |
| Oats | 2 | 18 | 0 | 33.33 | 100 | 100 | 0 | 100 |
| Soybean-notill | 97 | 875 | 69.94 | 71.66 | 99.31 | 98.17 | 96.91 | 99.89 |
| Soybean-mintill | 245 | 2210 | 88.64 | 85.48 | 99.32 | 99.28 | 97.24 | 99.41 |
| Soybean-clean | 59 | 534 | 76.97 | 72.66 | 97.75 | 97.57 | 98.88 | 98.50 |
| Wheat | 20 | 185 | 99.46 | 98.92 | 96.62 | 98.92 | 100 | 100 |
| Woods | 126 | 1139 | 97.54 | 95.61 | 100 | 100 | 99.91 | 100 |
| Bldg-Grass-Trees-Drives | 38 | 348 | 44.54 | 62.93 | 97.99 | 98.85 | 97.70 | 99.14 |
| Stone-Steel-Towers | 9 | 84 | 94.05 | 75.00 | 100 | 100 | 95.24 | 98.81 |
| OA | 82.00 | 82.02 | 98.64 | 99.08 | 97.10 | 99.44 | ||
| AA | 69.03 | 73.45 | 90.57 | 98.68 | 81.15 | 98.75 | ||
| κ | 79.28 | 79.37 | 98.44 | 98.95 | 96.69 | 99.36 | ||
সারণী 9. পাভিয়া ডেটাসেট (পুরো দৃশ্য) বিশ্ববিদ্যালয়ের জন্য শ্রেণিবদ্ধকরণের নির্ভুলতা (%)।
| Class | Samples | SVM | KELM | Gabor-SVM | Gabor-KELM | MH-SVM | MH-KELM | |
|---|---|---|---|---|---|---|---|---|
| Train | Test | |||||||
| Asphalt | 66 | 6565 | 87.02 | 84.01 | 94.30 | 94.49 | 97.93 | 96.29 |
| Meadows | 186 | 18463 | 97.28 | 97.51 | 99.82 | 99.96 | 99.91 | 99.98 |
| Gravel | 20 | 2079 | 57.58 | 61.28 | 93.27 | 95.00 | 87.01 | 93.25 |
| Trees | 30 | 3034 | 74.03 | 76.43 | 94.99 | 95.45 | 94.96 | 96.30 |
| Painted metal sheets | 13 | 1332 | 99.25 | 99.47 | 99.77 | 99.92 | 99.55 | 99.70 |
| Bare Soil | 50 | 4979 | 57.02 | 60.88 | 99.92 | 99.98 | 98.57 | 99.46 |
| Bitumen | 13 | 1317 | 63.63 | 72.59 | 88.23 | 98.56 | 82.38 | 95.67 |
| Self-Blocking Bricks | 36 | 3646 | 86.48 | 83.19 | 85.24 | 88.62 | 94.30 | 97.11 |
| Shadows | 9 | 938 | 98.83 | 86.99 | 75.69 | 79.64 | 82.73 | 52.35 |
| OA | 9 | 938 | 85.46 | 85.4 | 96.16 | 97.08 | 97.04 | 97.31 |
| AA | 80.12 | 80.26 | 92.36 | 94.62 | 93.04 | 92.23 | ||
| κ | 80.23 | 80.53 | 94.89 | 96.12 | 96.06 | 96.42 | ||
পরিশেষে, আমরা প্রতি ক্লাসে 20 লেবেলযুক্ত নমুনা ব্যবহার করে উল্লিখিত শ্রেণিবদ্ধকরণ পদ্ধতিগুলির গণ্য জটিলতার প্রতিবেদন করি।সমস্ত পরীক্ষাগুলি মেটাল্যাব ব্যবহার করে একটি Intel i7 Quadcore 2.63-GHz machine with 6 GB of RAM সহ ব্যবহার করা হয়। দুটি পরীক্ষামূলক তথ্য কার্যকর করার সময়টি টেবিল 10-এ তালিকাভুক্ত করা হয়েছে বর্ণাল-স্থানিক ভিত্তিক পদ্ধতির জন্য,আমরা আলাদাভাবে বৈশিষ্ট্য নিষ্কাশন এবং শ্রেণিবিন্যাস (প্রশিক্ষণ এবং পরীক্ষার) জন্য সময় প্রতিবেদন করি।এটি লক্ষ করা উচিত যে এসভিএম লাইবসভিএম প্যাকেজে প্রয়োগ করা হয় যা ম্যাটল্যাবে সি প্রোগ্রাম কল করার জন্য ম্যাক্স ফাংশন ব্যবহার করে এবং কেএলএম নিখুঁতভাবে ম্যাটল্যাবে প্রয়োগ করা হয়।টেবিল 10-তে দেখা যাবে, পিক্সেল-ভিত্তিক শ্রেণিবদ্ধদের কার্যকরকরণের সময় হিসাবে,[সি] তে এসভিএম প্রয়োগ করা সত্ত্বেও কেইএলএম এসভিএমের তুলনায় অনেক দ্রুত। বর্ণাল-স্থানিক ভিত্তিক শ্রেণিবদ্ধীদের জন্য(অর্থাত্ গ্যাবার-ফিল্টারিং-ভিত্তিক এবং এমএইচ-প্রেডিকশন-ভিত্তিক শ্রেণিবদ্ধ) প্রত্যাশার মতো,তারা স্থানিক বৈশিষ্ট্য নিষ্কাশনের অতিরিক্ত বোঝা বহন করে (যেমন, পিসিগুলিতে গ্যাবার ফিল্টারিং, বা এমএইচ পূর্বাভাস প্রিপ্রোসেসিং) পিক্সেল-ভিত্তিক শ্রেণিবদ্ধের তুলনায় অনেক ধীর।এমএইচ-পূর্বাভাস-ভিত্তিক পদ্ধতিগুলি সবচেয়ে বেশি সময় ব্যয়কারী যেহেতু এমএইচ পূর্বাভাসের দুটি পুনরাবৃত্তি পরীক্ষাগুলিতে ব্যবহৃত হয় এবং ওজন ভেক্টর [Ŵ] গণনা করতে হয়এমএইচ পূর্বাভাসের সময় সমীকরণ (8) অনুসারে চিত্রের প্রতিটি পিক্সেলের জন্য। এটি উল্লেখযোগ্য যে গ্যাবর বৈশিষ্ট্য নিষ্কাশন পদ্ধতি প্রতিটি পিসিতে স্বাধীনভাবে সঞ্চালিত হয়, যার অর্থ গ্যাবার বৈশিষ্ট্য নিষ্কাশন সমান্তরাল যেতে পারে can সুতরাং, পিসিগুলিতে গ্যাবার বৈশিষ্ট্য নিষ্কাশনের গতি অনেক উন্নত করা যায়।
Table 10. Execution time for the Indian Pines dataset (nine classes, 180 training and 9054 testing samples) and the University of Pavia dataset (180 training and 7920 testing samples).
| Method | Indian Pines | University of Pavia | ||
|---|---|---|---|---|
| Time (s)(Feature Extraction) | Time (s)(Classification) | Time (s)(Feature Extraction) | Time (s)(Classification) | |
| SVM | - | 0.94 | - | 0.89 |
| KELM | - | 0.23 | - | 0.17 |
| Gabor-SVM | 46.83 | 1.02 | 377.04 | 0.93 |
| Gabor-KELM | 46.83 | 0.27 | 377.04 | 0.20 |
| MH-SVM | 215.40 | 0.91 | 479.78 | 0.85 |
| MH-KELM | 215.40 | 0.25 | 479.78 | 0.16 |
4। উপসংহার
এই কাগজে, আমরা Gabor features and MH prediction preprocessing ব্যবহার করে KELM শ্রেণিবদ্ধের কার্যকারিতা উন্নত করতে spectral and spatial তথ্য সংহত করার প্রস্তাব দিয়েছিলাম। বিশেষত, PCA-projected domain নে স্থানিক বৈশিষ্ট্যগুলি সন্ধান করতে একটি সাধারণ দ্বিমাত্রিক গ্যাবার ফিল্টার প্রয়োগ করা হয়েছিল। MH চিত্রের স্থানিক টুকরা-ধারাবাহিক প্রকৃতির ব্যবহার করে। প্রস্তাবিত শ্রেণিবিন্যাস কৌশল,অর্থাত্ i.e., Gabor-KELM and MH-KELM তুলনা করা হয়েছে conventional pixel-wise classifiers র সাথে, যেমন SVM এবং HELM, পাশাপাশি Gabor-SVM and MH-SVM, হাইপারস্পেকট্রাল ডেটার জন্য SSS শর্তের অধীনে। পরীক্ষামূলক ফলাফলগুলি প্রমাণ করেছে যে প্রস্তাবিত পদ্ধতিগুলি প্রচলিত পিক্সেল-ভিত্তিক শ্রেণিবদ্ধের পাশাপাশি গ্যাবার-ফিল্টারিং-ভিত্তিক SVM এবং MH-প্রেডিকশন-ভিত্তিক SVMকে ছোট প্রশিক্ষণের নমুনা আকারের শর্তগুলিকে চ্যালেঞ্জ জানায়, বিশেষ করে, প্রস্তাবিত বর্ণালী-স্থানীয় শ্রেণিবিন্যাস পদ্ধতিগুলি ভারতীয় পাইনের ডেটাসেটের জন্য পিক্সেল-ভিত্তিক শ্রেণিবদ্ধকরণ পদ্ধতির চেয়ে 16% এবং 9% শ্রেণিবিন্যাসের নির্ভুলতার উন্নতি অর্জন করেছে এবং যথাক্রমে পাভিয়া ডেটাসেট বিশ্ববিদ্যালয়। MH-KELM, MH-SVM কে পেনিয়া ইউনিভার্সিটি অফ পাভিয়া ডেটাসেটের জন্য সমস্ত প্রশিক্ষণের নমুনার আকারে প্রায় 1.3% ছাড়িয়ে ভারতীয় পাইনের ডেটাসেটের জন্য প্রায় 5% এবং Gabor-SVM কে ছাড়িয়ে গেছেন। তদুপরি, KELM খুব দ্রুত প্রশিক্ষণ এবং পরীক্ষার গতি প্রদর্শন করে যা হাইপারস্পেক্ট্রাল বিশ্লেষণ অ্যাপ্লিকেশনগুলির জন্য একটি গুরুত্বপূর্ণ বৈশিষ্ট্য। যদিও প্রস্তাবিত পদ্ধতিগুলি স্থানিক বৈশিষ্ট্য নিষ্কাশনের উপরে অতিরিক্ত বোঝা বহন করে, সমান্তরাল কম্পিউটিংয়ের মাধ্যমে গুণগত ব্যয় হ্রাস করা যায়।
প্রাপ্তি স্বীকার
এই গবেষণার অংশটি চীনের ন্যাশনাল ন্যাচারাল সায়েন্স ফাউন্ডেশন (41201341, 61302164), স্যাটেলাইট ম্যাপিং প্রযুক্তি ও প্রয়োগের মূল গবেষণাগার, সমীক্ষার জাতীয় প্রশাসন, ম্যাপিং এবং জিওনফরমেশন (কেএলএসএমটিএ-201301) এর মূল গবেষণাগার এবং এর উন্নত প্রকৌশল সমীক্ষার মূল গবেষণাগার দ্বারা অংশীদারিত হয়েছিল সমীক্ষা, ম্যাপিং এবং ভূ-তদন্তের জাতীয় প্রশাসন (নং টিজেইএস 1301)।
0 comments:
Post a Comment