Deep Learning for Hyperspectral Image Classification: An Overview (2019)
ABSTRACT
1.INTRODUCTION
2.DEEP MODELS
SAEs (stacked autoencoders):
DBNs (Deep Belief Networks):
CNNs (Convolutional Neural Network):
RNNs (recurrent neural networks):
GANs (Generation Adversarial Networks):
3.DEEP NETWORKS-BASED HSI CLASSIFICATION
Spectral-Feature Networks:
Spatial-Feature Networks:
Spectral-Spatial-Feature Networks:
(1) preprocessing-based networks
(2) integrated networks
(3) postprocessing-based networks
4.STRATEGIES FOR LIMITED AVAILABLE SAMPLES
Data Augmentation
Transfer Learning
Unsupervised / Semisupervised Feature Learning
Network Optimization
5.EXPERIMENT
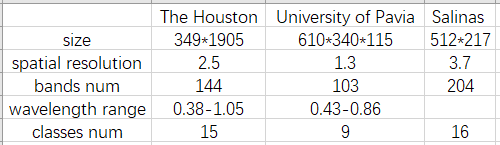
Experiment data sets
Compared Methods
Classification Results
Deep Feature Visualization
Effectiveness Analysis of Strategies for Limited Samples
6.CONCLUSION
ABSTRACT
First, the shortcomings of traditional machine learning methods and the advantages of deep learning are summarized.
Then, according to the characteristics of network extraction in the literature, recent research results are divided into three categories: spectral-feature networks, spatial-feature networks, and spectral-spatial-feature networks.
In addition, several strategies are proposed for the problem of limited training samples.
Finally, several deep learning-based classification methods are used to classify and compare hyperspectral data sets.
1.INTRODUCTION
The two major challenges of hyperspectral classification are:
(1) the spatial variation of spectral signatures is large; (2) the number of samples is limited, and the hyperspectral data has a high dimension.
Hyperspectral classification methods:
(1) pixelwise classification methods: NN, SVM, MLR (polynomial logistic regression), dynamic or random subspace (focus on spectral signature); PCA, ICA, LDA (linear discriminant analysis) (Focus on feature extraction or dimensionality reduction)
----------------------------------------- ------- Add spatial features ---------------------------------------- --------
(2) SSFC (spectral-spatial features-based classification, which adds spatial context information to the above-mentioned pixel-level classifier): EMP (extended morphological profiles, to obtain spatial information through morphological operations) , Mutiple kernel learning (design composite kernel and morphological kernel to obtain spectral-spatial information), EPF (edge-preserving filtering, post-processing method to optimize SVM probability results), sparse representation model (spatial information added to the neighborhood, sparse representation model is based on Hyperspectral cells can represent this finding with a linear combination of a small number of similar cells).
The shortcomings of traditional machine learning methods:
(1) Relying on hand-crafted or shallow-based descriptors, and artificial features are designed to complete specific tasks, and expert knowledge is required during the parameter initialization stage, which limits the model application scenario .
(2) The ability to express artificial features is not enough to identify small variations between different classes and large variations within a class.
The advantages of deep learning:
(1) the ability to extract information-rich features
(2) deep learning is automatic, so the scenario in which the model is applied is more flexible.
2.DEEP MODELS
Briefly introduce several deep network models commonly used in hyperspectral classification-SAEs (stacked self-coding), DBNs (deep belief networks), CNNs (convolutional neural networks), RNNs (recurrent neural networks), GANs (generating adversarial networks) ).
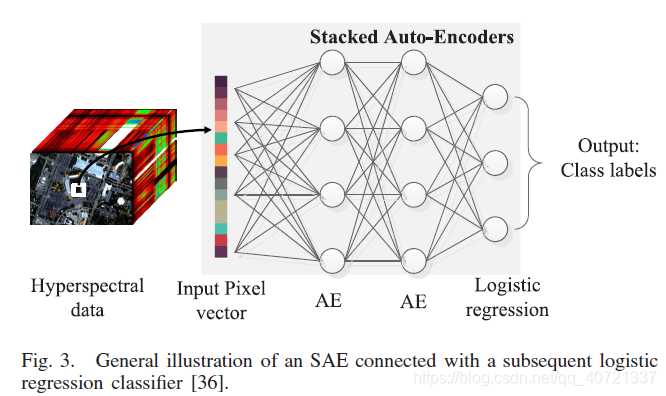
SAEs (stacked autoencoders):
"A Brief Introduction to Autoencoders and Stacked Autoencoders" (This article is a comprehensive description of SAEs)
AE is the basic unit of SAEs. AE network consists of input layer (x), hidden layer (h), output layer (y) Make up. The process from x to h is called "encoder", and the process from h to y is called "decoder". We pay attention to the "encoder" process, hoping that the h obtained by some transformation of x can be restored to y to the greatest extent, so that a certain characteristic h of x is extracted.

After training AE to extract the h features, we will remove the output layer layer and then stack them to extract deeper features. Finally, a Logistic regression classifier is added to get SAEs.
Inputting a pixel vector and outputting class labels can treat SAEs as a spectral classifier.
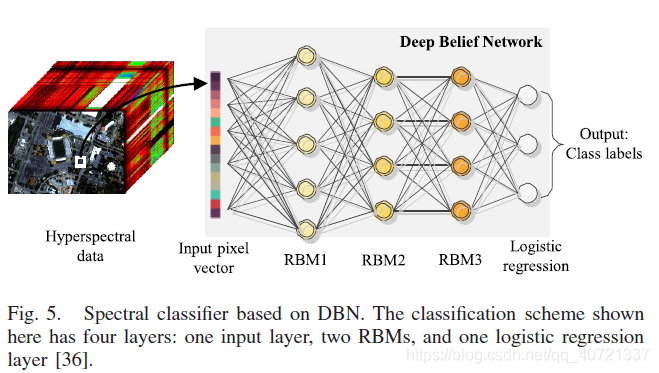
DBNs (Deep Belief Networks):
"Restricted Boltzmann Machine", copyright statement: This article is an original article by the CSDN blogger "Hiro Great", which follows the CC 4.0 by-sa copyright agreement. Please reprint the original source link and this statement.
Deep Learning-Deep Belief Network
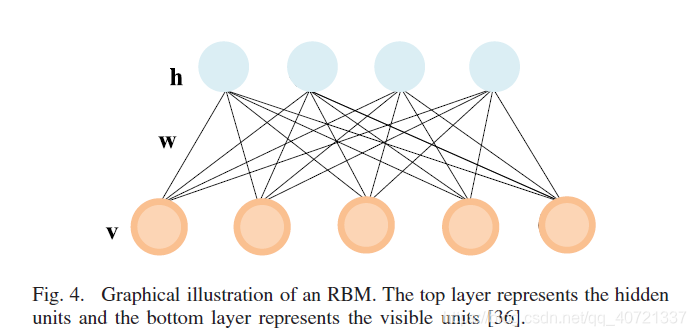
RBM (Restricted Boltzmann Machine) is the basic unit of DBN. It is similar to AE in SAEs and belongs to unsupervised classification. Forward propagation is the encoding process and back propagation. That is the decoding process. The connections between neuron nodes are two-way.
Each node of the RBM is a random binary node (valued as 0/1), which is also the source of "restriction". The energy function of RBM is based on the Boltzmann distribution of energy. The connection structure between each visible node and hidden node has an energy. Through the learning of the parameters in v and h, we can calculate its energy. The changing process of the neural network is essentially a process of continuously decreasing energy, and finally reaches the minimum point of energy, which is the steady state.
DBN is composed of multiple layers of RBM, which can be regarded as a generative model or discriminative model. Adding a Logistic regression classifier constitutes a spectral classifier.
CNNs (Convolutional Neural Network):
"One article gives you a thorough understanding of convolutional neural networks."
CNNs can extract two-dimensional spatial features of an image, and can also use parameter sharing to reduce network parameters. Including convolutional layer, pooling layer, fully connected layer. The fully connected layer converts feature maps into feature vectors.

RNNs (recurrent neural networks):
"RNN for Deep Learning (Recurrent Neural Network)", copyright statement: This article is the original article of CSDN blogger "Awkward Stone", which follows the CC 4.0 by-sa copyright agreement. Please reprint the original source link and this statement.
The nodes in the hidden layer in RNNs are connected. The input of the hidden layer includes not only the output of the input layer but also the output of the hidden layer at the previous moment. So RNNs are suitable to deal with the problems related to time series.
Also, in the spectral space, each pixel vector of hyperspectral data can be regarded as a series of ordered and continuous spectral sequences, so RNNs are suitable for hyperspectral classification.
For the problem of gradient disappearance or gradient explosion, improved algorithms for RNNs are also proposed: LSTM and GRU.
GANs (Generation Adversarial Networks):
In the field of machine learning, models can be roughly divided into two categories: generative models and discriminative models. The generated model learns the parameter distribution from the data, and then generates new samples based on the learned model; discriminates the differences between the data of the model, establishes a mapping from x to y based on the sample data, and then makes predictions based on this mapping.
"One article read Generative Adversarial Networks (GANs) [Download PDF | Long article]" The
generation model enhances the ability of the generation model to generate false data by generating false data with noise, and judging true data and false data by discriminating the model.
3.DEEP NETWORKS-BASED HSI CLASSIFICATION
Spectral-Feature Networks:
In the early days, SAE or DBN was directly trained in an unsupervised manner using the original spectral vector.
Later, a classification framework combining deep learning and active learning was proposed, in which DBN was used to extract deep spectral features, and deep learning algorithms were used to select high-quality training samples for people to label; and proposed diversified DBN, which is a preprocessing and fine-tuning program for regularized DBN .
In addition, 1-D CNN, 1-D GAN, and RNN are also used to extract the spectral features; perform conv extraction of pixel-pair features (PPFs) in the spectral domain.
Finally, the dictionary is trained to train deep networks that are reformulated.
Spatial-Feature Networks:
The learned spatial features will be fused with the spectral features extracted by other feature extraction methods to perform more accurate hyperspectral classification.
PCA (reduce the original data dimension) + 2-D CNN (extract spatial information in the space domain);
use sparse representation to encode the deep spatial feature extracted by CNN to make it a low-dimensional sparse representation;
directly use AlexNet And GoogleNet's CNNs to extract deep spatial
features ; SSFC framework, which uses balanced local discriminant embedding (BLDE) and CNN to extract spectral and spatial features, and then fuses features to train multiple-features-based classifier;
multiscale spatial-spectral feature extraction algorithm, the trained FCN-8 is used to extract deep multiscale spatial features, then the original spectral features and deep multiscale spatial features are fused using a weighted fusion method, and the fused features are finally put into the classifier;
Spectral-Spatial-Feature Networks:
This network is not used to extract spectral features or spatial features, but to extract joint deep spectral-spatial features.
There are three ways to obtain joint deep spectral-spatial features: (1) map low-level spectral-spatial features to high-level spectral-spatial features through a deep network; (2) directly extract from the original data or several principal components deep spectral-spatial features; (3) Fusion of 2 deep features, namely deep spectral features and deep spatial features.
Therefore, according to the different processing stages of fusion of spectral information and spatial information, spectral-spatial-feature networks are also divided into 3 categories: preprocessing-based networks, integrated networks, and postprocessing-based networks.
(1) preprocessing-based networks
Spectral features and spatial features have been merged before connecting to the deep network.
Processing steps: ① low-level spectral-spatial feature fusion; ② extract high-level spectral-spatial feature with deep networks; ③ connect deep SSFC with simple classifier (such as SVM, ELM extreme learning machine, polynomial logistic regression).
Because fully connected networks (such as DBN, SAE, etc.) can only process 1-dimensional inputs, we thought of reshape the spatial neighborhood into a 1-dimensional vector, superimposed with 1-dimensional spectral information, and put it into a fully-connected network;
placing a spatial neighborhood The spectral information of all pixels is averaged into a spectral vector. This average spectral vector actually includes spatial information, and we put it into the next deep network;
some of them do not obtain spatial information in the neighborhood. Filtering methods (such as using Gobar filtering, attribute filtering, extension filtering, and rolling guidance filtering to extract more effective spatial features), which combine deep learning and spatial-feature extraction methods.
(2) integrated networks
Instead of obtaining the spectral features and spatial features separately and then merging, you can directly obtain joint deep spectral-spatial features.
Use 2-D CNN or 3-D CNN to directly extract joint deep spectral-spatial features from the original data;
FCN (fully convolutional network) can learn hyperspectral deep features through supervised or unsupervised methods;
RL (residual learning) Can help build a deep and wide network. The output in a residual unit is the sum of the input and input roll values;
use 3-D GAN to extract features, where one CNN is a discriminative model and the other CNN is a generation model;
correction CapsNets as a spectral-spatial capsules to extract features;
--------------------------------------- --------- Propose hybrid deep networks ------------------------------------- -----------
Three-layer stacked convolutional autoencoder can learn generalizable features through unlabeled pixels;
convolutional RNNS (CRNNs) use CNN to extract middle-level features from hyperspectral sequences, and use RNN Extract context information from middle-level features;
The spectral-spatial cascaded RNN model is used to extract features.
(3) postprocessing-based networks
Processing steps: ① Use 2 deep networks to extract deep spectral features and deep spatial features; ② Fusion 2 features at the fully connected layer to generate deep spectral-spatial features; ③ combine deep SSFC with simple classifier (such as SVM, ELM extreme learning machine , Polynomial Logistic Regression).
The two deep networks in step ① may or may not share weights.
1-D CNN is used to extract spectral features, and 2-D CNN is used to extract spatial features. Then these two features are fused and connected with the fully connected layer to extract the spectral-spatial features for classification;
for each input pixel, the stacked features are extracted using a denoising autoencoder. For the corresponding picture block, deep CNN is used to extract spatial features, and then the two prediction probabilities are fused;
two principal component analysis networks are used to extract the spectral features, and two stacked sparse autoencoders are used to extract the spatial features + fully connected layers + SVM
Multiple CNNs simultaneously process multiple spectral sets (shared weights), each CNN extracts the corresponding spatial feature + fuses the individual spatial features in the fully connected layer.
4.STRATEGIES FOR LIMITED AVAILABLE SAMPLES
Data Augmentation
DA generates virtual samples through training samples, including 2 methods: (1) transform-based sample generation; (2) mixture-based sample generation
(1) transform-based sample generation
due to similar objects under different lighting conditions will be different , So we can generate new data by rotating and mirroring existing training samples.
(2) Mixture-based sample generation
can generate 1 new sample by linear combination of 2 similar samples.
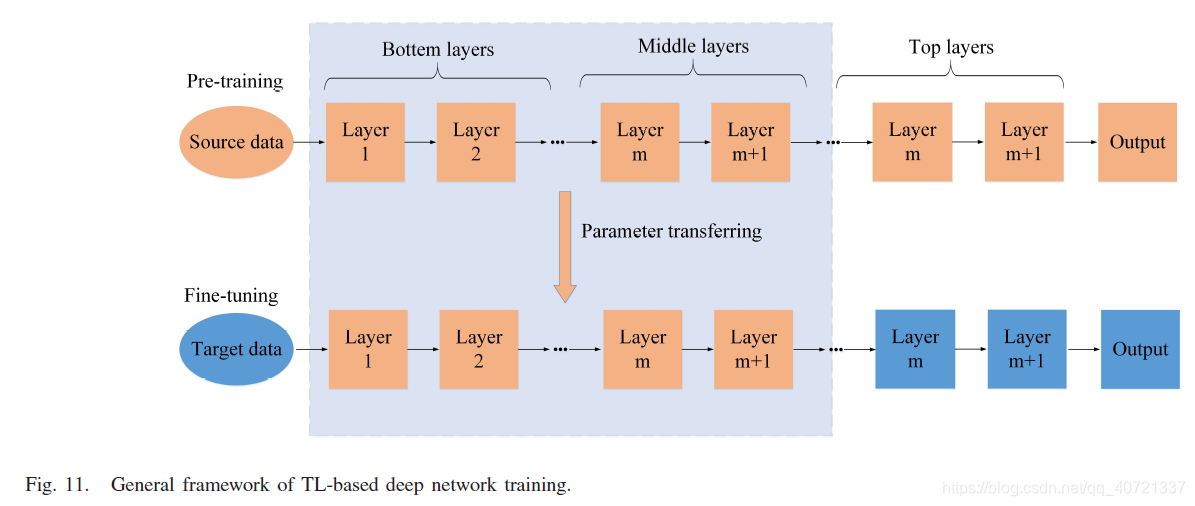
Transfer Learning
TL can copy parameters from other trained networks to initialize parameters. directly transfer the network parameters of low and middle layers to a new network that has the same architecture as the previous network.
The parameters of the top layers are also randomly initialized to deal with specific problems.
Once the network parameters have been migrated, the subsequent classifications can also be divided into unsupervised and supervised methods. The unsupervised method directly uses the features extracted by the migration network for classification; the unsupervised classification also adds a small number of training samples to be fine-tuned.
Unsupervised / Semisupervised Feature Learning
Unsupervised feature learning only uses unlabeled data sets, which can be considered as an encoder-decoder process. Semi-supervised classification feature learning can extract features by transferring the parameters of the trained network and fine-tuning the labeled dataset.
HSIs are classified using a fully connected network. The training of the network is divided into unsupervised pretraining and fine-tuning with labeled data. During the pretraining period, parameter learning can be viewed as an encoder-decoder process (unlabled data–intermediate feature–reconstruction). But this is relatively inefficient, so an unsupervised end-to-end training framework is proposed, which regards the convolutional network as the encoder and the deconvolution network as the decoder.
GAN is also used to build a semi-supervised feature learning framework.
A large number of unlabeled data and pseudo labels obtained using the parameterless Bayesian clustering algorithm are used to pre-train the CRNN.
Network Optimization
By adopting more efficient modules or functions, network optimization can improve network performance.
The ReLU activation function can alleviate overfitting during training.
RL has two mapping modes: identity mapping and residual mapping. By introducing the residual function G (X) = F (X) -X, F (X) = X is converted into G (X) = 0.
Regularized pre-training and fine-tuning programs can improve the performance of DBN;
label consistency constraint is added to SAE training;
and the correlation between samples is considered.
5.EXPERIMENT
Experiment data sets


Compared Methods
This paper discusses 6 deep learning classification methods-3-D-CNN, Gabor CNN, CNN with PPFs, Siamese CNN (S-CNN), 3-D-GAN, deep feature fusion network (DFFN) and 4 Traditional classification methods-SVM, EMP, joint sparse representation (JSP), EPF.
3-D-CNN uses 3-D convolution filtering to directly extract the spectral-spatial features from the original cube, but ignores the correlation between different layers;
DFFN only uses DRN, taking into account the correlation between layers, it can be extracted More discriminative features. But it relies on artificial features;
Gabor CNN uses Gabor filtering to extract spatial features, and uses CNN to obtain joint deep spectral-spatial features;
CNN-PPF and S-CNN both consider the correlation between samples. Among them, CNN-PPF does not consider spatial information, S-CNN uses two-branch CNN to directly extract spectral-spatial features, but because the dimension is too high, the amount of calculation is also relatively large;
3-D-GAN with a small number of samples, Can effectively improve the generalization of CNN.
SVM is a spectral feature-based method. EMP, JSP, and EPF are all spectral-spatial feature-based methods.
EMP uses the first three principal components to construct the morphological profile. For each principal component, a structural unit with a step size of 2 is used to perform 4 opening and closing operations.
JSP uses joint sparse regularization to obtain the spatial information of the neighborhood.
To summarize, except SVM and CNN-PPF use spectral features in the classification process, the other methods are based on spectral-spatial fetures classification methods.
Classification Results
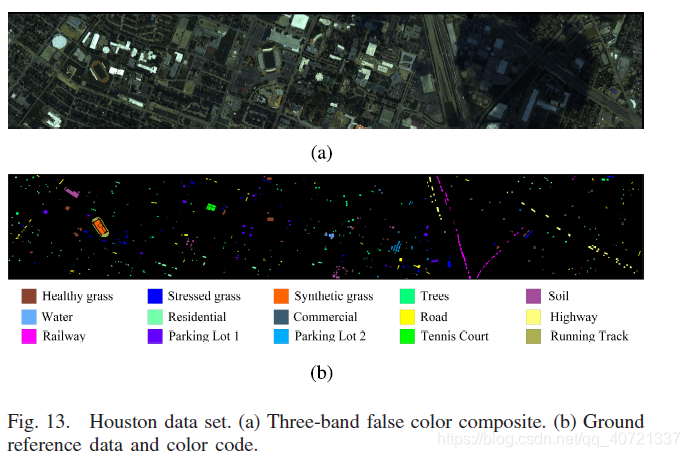
For the Houston dataset, SVM and JSP results are not good, with a lot of visible noise. EPF and Gabor-CNN are both filtering-based methods. The classification map of ESF is too smooth, while Gabor-CNN retains edge details.
Except for 3-D-DAN, other deep learning methods have OAs greater than 80%, which is higher than traditional classification methods.
In deep learning methods, CNN-PPF considering only the spectral information has worse classification results than other methods.
DFFN combines RL and feature fusion, achieving the highest accuracy in OA, AA and Kappa.
For the University of Pavia dataset and Salinas dataset, the deep learning method is more accurate than the traditional classification method in both classification map results and quantitative results.
SVM, EMP, EPF, and S-CNN are all SVM-based classifiers, and S-CNN has the highest classification accuracy.
EPF and Gabor-CNN are both filtering-based methods. Gabor-CNN's OA is 3.5% higher than EPF, which indicates that the combination of filter and deep learning can have better classification results.
Although CNN-PPF only considers the spectral information, it still performs better than traditional classification methods.
Deep Feature Visualization

By comparing the weights of the convolution kernel before and after learning, we can find that the weights of the convolution kernel after learning are more regular.


It can be seen from the above two pictures that the previous convolutional layer mainly extracts simple features such as edge or texture information. These lower level features can be combined into more complex high-level features through the subsequent convolutional layers. This feature makes CNNs suitable for dealing with problems in different situations.
Effectiveness Analysis of Strategies for Limited Samples
We set up a simple CNN and use three strategies (DA, TL, RL) to test their effectiveness.
CNN-Original, CNN-DA, CNN-TL, and CNN-RL are used in the Salinas dataset, where the training sets include 5, 10, 15, 20, 25, 30 labeled samples / classes, and other labeled samples are used. Treated as test set data.
The CNN in CNN-TL is pre-trained in Indian Pines because Indian Pines and Salinas images have the same sensor.
Observing the classification results, we find that all three strategies can improve OA, and CNN-RL performs best in most cases, which shows that RL is a very useful network optimization method.
6.CONCLUSION
First, we introduce several deep models commonly used in HSIs classification-SAE, DBN, CNN, RNN, GAN,
and then divide the deep learning-based classification methods into three categories: spectral-feature networks, spatial-feature networks, spectral-spatial networks.
Second, we compared the classification accuracy of deep learning classification and traditional classification methods, and found that deep learning classification methods performed better than traditional classification methods in general, and the DFFN method combining RL and feature fusion performed best.
Also, deep features and network weights are visualized.
In addition, we verified several strategies proposed for small sample sizes and found that using RL can better improve network performance.
0 comments:
Post a Comment