I. Summary and Contributions
বর্তমানে হাইপারস্পেকট্রাল ইমেজ (এইচএসআই) শ্রেণিবিন্যাসের জন্য গভীর শেখার পদ্ধতিগুলি সফলভাবে ব্যবহৃত হয়েছে। যাইহোক, একটি গভীর শিক্ষার শ্রেণিবদ্ধ প্রশিক্ষণ দেওয়ার জন্য কয়েকশ বা শত শত লেবেলযুক্ত নমুনার প্রয়োজন। এই নিবন্ধটি এইচএসআই শ্রেণিবিন্যাসের ছোট নমুনা সমস্যা সমাধানের জন্য একটি গভীর শিক্ষণ পদ্ধতির প্রস্তাব করেছে। There are three novel strategies in the proposed algorithm:
- The spatial features of the spectrum are extracted by a deep 3-D residual convolutional neural network to reduce the uncertainty of the label.
- Train the network through epideses to learn the metric space, where samples from the same class are close in distance and samples from different classes are far away.
- The test samples are classified by the nearest neighbor classifier in the learning metric space.
The key idea of this algorithm is to design the network to learn the metric space from the training data set. In addition, this metric space can be generalized to classes of test datasets.
১. একটি DFSL (ডিপ ফিউ-শট লার্নিং) পদ্ধতিটি মেট্রিক স্পেস শেখার জন্য নেটওয়ার্ককে প্রশিক্ষণের জন্য প্রস্তাবিত, যা একই বর্গের নমুনাগুলি বন্ধ করে দেয়। গুরুত্বপূর্ণভাবে, এই ধরনের একটি মেট্রিক স্থান প্রশিক্ষণের সময় দেখা যায় না শ্রেণীর জন্য একই কাজ করতে হবে। অতএব, পরীক্ষা ডেটা সেট শ্রেণীবিভাগ নিকটতম প্রতিবেশী ক্লাসিফায়ার দ্বারা সম্পন্ন করা যেতে পারে।
2. ডীপ 3-ডি convolutional স্নায়ুর নেটওয়ার্ক মেট্রিক স্থান parameterize ব্যবহার করা হয়। এছাড়াও, নেটওয়ার্ককে আরও ভাল প্রশিক্ষণের জন্য অবশিষ্ট প্রশিক্ষণ চালু করা হয়। এই গভীর 3-ডি অবশিষ্ট convolutional স্নায়ুর নেটওয়ার্ক কোনো প্রাক-প্রক্রিয়াকরণ উপর নির্ভর না করেই ডাটা ঘনক্ষেত্র থেকে সরাসরি ভুতুড়ে স্থানিক বৈশিষ্ট্য নিষ্কাশন করতে পারেন।
3. চার পরিচিত HSI ডেটাসেট উপর এক্সপেরিমেন্ট প্রমাণ প্রস্তাবিত পদ্ধতি শুধুমাত্র লেবেল নমুনা একটি ছোট সংখ্যা চিরাচরিত আধা তত্ত্বাবধানে থাকা পদ্ধতি সুখ্যাতি পারবেন না।
Method
DFSL (Deep Few-shot Learing)

চিত্র 1 Deep Few-Shot Learningপদ্ধতির ভিজ্যুয়াল উপস্থাপনা
প্রশিক্ষণ সেট থেকে ক্লাসগুলির একটি উপসেট এলোমেলোভাবে গ্রেডিয়েন্টগুলি কম্পিউটিং এবং নেটওয়ার্ক আপডেট করার জন্য এপিডিস গঠন করতে নির্বাচিত হয়। চিত্র 1-এ প্রদর্শিত হিসাবে, প্রতিটি শ্রেণীর মধ্যে নমুনার একটি উপসেট সমর্থন সেট হিসাবে নির্বাচিত হয় এবং অবশিষ্ট উপগ্রহগুলি ক্যোয়ারী সেট হিসাবে ধরে রাখা হয়। এই কাগজটিতে, পরীক্ষার ডেটা সেটে ছোট ছোট নমুনাগুলির শ্রেণিবিন্যাস অনুকরণের জন্য প্রতিটি ধরণের মাত্র একটি নমুনা সমর্থন সেট হিসাবে নির্বাচিত হয়। সমর্থন সেট এবং ক্যোয়ারী সেটগুলির নমুনাগুলি এম্বেডযুক্ত বৈশিষ্ট্যগুলি বের করতে নেটওয়ার্কের মাধ্যমে খাওয়ানো হয়। এম্বেডিং স্পেসে সমর্থন সেটগুলির নমুনাগুলির দূরত্বের সফটম্যাক্স গণনার ভিত্তিতে ক্যোয়ারী নমুনার শ্রেণিবণ্টন গণনা করা হয়।

চিত্র 2: চিত্র 2 Deep Few-Shot Learning অ্যালগরিদম পদক্ষেপে নির্দিষ্ট অ্যালগরিদম দেখানো হয়েছে
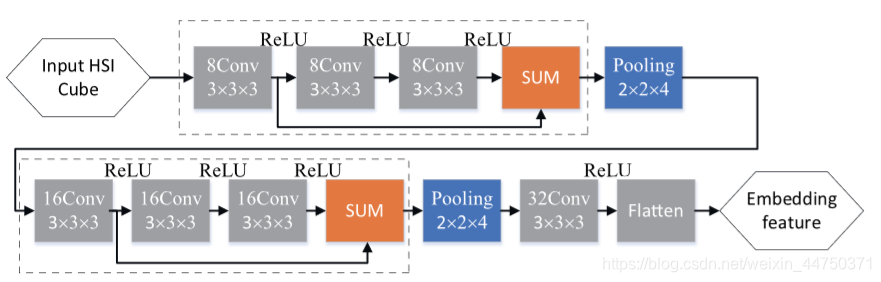
গভীর 3-ডি সিএনএন
Figure 3 Network architecture of Deep 3-D CNN
চিত্র 3-তে দেখানো হয়েছে, 2 টি অবশিষ্ট অবরুদ্ধ ব্লক, 2 টি পুলিং স্তর এবং 1 কনভ্যুশনাল সহ একটি নেটওয়ার্ক স্তর এম্বেডিং ফাংশন হিসাবে নকশা করা হয়েছে। তন্মধ্যে, ডটেড বাক্সটি একটি অবশিষ্টাংশ। পুলিং স্তরগুলি শর্টকাট এবং বিভিন্ন আকারের প্রধান পাথের ফলস্বরূপ। অতএব, অবরুদ্ধ ব্লকে কোনও পুলিং স্তর ব্যবহার করা হয় না। পরিবর্তে, প্রতিটি অবশিষ্ট অবরুদ্ধকরণ গণনা এবং সমষ্টিগত বৈশিষ্ট্য হ্রাস করতে 3-ডি সর্বাধিক পুলিং স্তরের সাথে সংযুক্ত থাকে। ইনপুট হাইপারস্পেকট্রাল ডেটার কিউব আকারের কারণে বর্ণাল মাত্রা বরাবর স্ট্রাইডটি 4 এবং স্থানিক মাত্রার বরাবর স্ট্রাইড 2 তে সেট করা হয়। পরিশেষে, বৈশিষ্ট্যটির মানচিত্রটি 1-ডি ভেক্টরে প্রসারিত করা যেতে পারে। চিত্র 3 এ প্রদর্শিত নেটওয়ার্কটি একটি মেট্রিক স্পেস শিখতে পারে যেখানে একই বিভাগের নমুনাগুলি একে অপরের কাছাকাছি রয়েছে।
Classi fi cation With the Nearest Neighbor নিকটতম নিকটবর্তী সহ ক্লাসিকেশন

Figure 4 Classification process on the test set
The classification of the test data set consists of three steps:
Extract embedded features through 3-D CNN with pre-trained depth residuals;
Calculate the Euclidean distance between the labeled sample and the sample to be classified;
The final label is determined by the NN classifier.
লেবেলযুক্ত নমুনা এবং শ্রেণিবদ্ধ করার নমুনার মধ্যে ইউক্যালিডিয়ান দূরত্ব গণনা করুন;
চূড়ান্ত লেবেলটি এনএন শ্রেণিবদ্ধ দ্বারা নির্ধারিত হয়।
প্রকৃতপক্ষে, ডিজাইন করা গভীর অবশিষ্টাংশ 3-ডি সিএনএন প্রশিক্ষণের পরে এম্বেডড ফাংশন হিসাবে বিবেচনা করা যেতে পারে। পরীক্ষার ডেটা সেটটির শ্রেণিবদ্ধকরণ প্রক্রিয়াতে, সমস্ত নমুনা পূর্ব-প্রশিক্ষিত গভীরতা অবধি 3-ডি সিএনএন এর মাধ্যমে বৈশিষ্ট্যগুলি নিষ্কাশন করে। তারপরে, তদারকি করা নমুনাগুলি হিসাবে এলোমেলোভাবে কিছু লেবেলযুক্ত নমুনা নির্বাচন করুন। প্রশিক্ষিত নেটওয়ার্ক এম্বেডিং স্পেসে একে অপরের নিকটে একই ধরণের নমুনা নিয়ে আসে। অতএব, পরীক্ষার নমুনাগুলি চিত্র 5-এ দেখানো হিসাবে, সাধারণ NN বিশ্লেষণ দ্বারা শ্রেণিবদ্ধ করা যেতে পারে। এটি লক্ষ্য করা গুরুত্বপূর্ণ যে প্রশিক্ষণ এবং পরীক্ষার ডেটা সেটগুলি একে অপরের থেকে স্বতন্ত্র। পরিশেষে, পরীক্ষার নমুনাগুলির লেবেলের দ্বারা উত্পন্ন শ্রেণিবদ্ধকরণ মানচিত্রটি বিভিন্ন শ্রেণিবদ্ধকরণ পদ্ধতিগুলি মূল্যায়নের জন্য আসল মানচিত্রের সাথে মেলানো হয়।
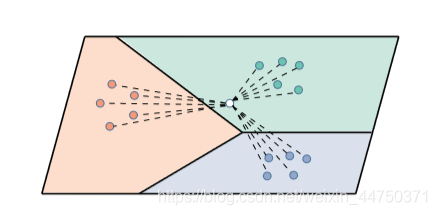
Figure 5 Classification in the test data set (each sample is labeled as 5 samples)
Experiments and data analysis
Experimental data set
(1) Training data set
In order to train Deep 3-D CNN, four publicly available HSI data sets were collected. Table 1 lists the details of the four data sets.
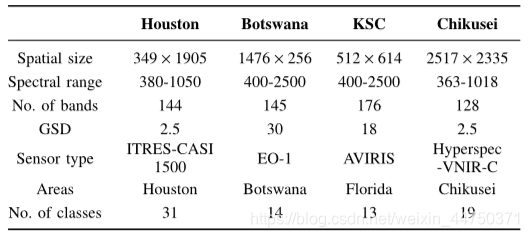
Table 1 Details of the training dataset
(2) Test data set
প্রস্তাবিত পদ্ধতির শ্রেণিবদ্ধকরণের প্রমাণের জন্য, চারটি সুপরিচিত এইচএসআই ডেটা সেটগুলিতে পরীক্ষা-নিরীক্ষা করা হয়েছিল। টেবিল 2 চারটি পরীক্ষার ডেটা সেটগুলির বিশদ তালিকাভুক্ত করে।
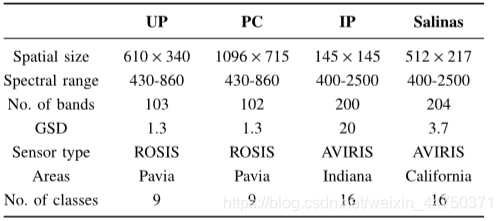
Table 2 Details of the test data set
ইউপি এবং পিসি ডেটাসেটের প্রথম 100 টি ব্যান্ড একই ইনপুট মাত্রা নিশ্চিত করতে ব্যবহৃত হয়। একইভাবে, আইপি এবং স্যালিনাস ডেটাসেটের প্রথম 200 টি ব্যান্ড শ্রেণিবদ্ধকরণের জন্য ব্যবহৃত হয়। আইপি এবং স্যালিনাস ডেটাসেটের পরীক্ষায়, প্রথম 100 ফ্রিকোয়েন্সি ব্যান্ড এবং শেষ 100 ফ্রিকোয়েন্সি ব্যান্ডগুলি বৈশিষ্ট্যগুলি বের করার জন্য ডি-রেজ-থ্রিডি সিএনএন দিয়ে প্রাক-প্রশিক্ষিত ছিল। তারপরে প্রথম 100 টি ব্যান্ড থেকে নেওয়া বৈশিষ্ট্যগুলি এবং শেষ 100 ব্যান্ডগুলি নতুন বৈশিষ্ট্য ভেক্টর গঠনের জন্য সংযুক্ত করা হয়েছে, যা শ্রেণিবদ্ধকরণের জন্য চূড়ান্ত বৈশিষ্ট্য হিসাবে ব্যবহৃত হয়।
Experimental setup
(1) (1) Different network architectures বিভিন্ন নেটওয়ার্ক আর্কিটেকচার
Table 3 Overall accuracy of different neural network architectures
টেবিল 3 চারটি পরীক্ষার ডেটা সেটগুলিতে বিভিন্ন নিউরাল নেটওয়ার্ক আর্কিটেকচারের সামগ্রিক যথার্থতা দেখায়। সমস্ত ক্ষেত্রে, পরামিতিগুলির সংখ্যা বাড়ার সাথে সাথে নেটওয়ার্ক আর্কিটেকচারের জটিলতাও বৃদ্ধি পায়। সারণী 3 থেকে দেখা যায়, শ্রেণিবিন্যাসের নির্ভুলতা নেটওয়ার্কের জটিলতা বাড়ার সাথে সাথে বৃদ্ধি পায় যা নেটওয়ার্ক গভীরতার গুরুত্ব প্রমাণ করে। এছাড়াও, অবশিষ্ট শিখনের প্রবর্তন শ্রেণিবিন্যাসের কার্যকারিতাও উন্নত করতে পারে।
(3) Different learning rates
Table 4 Overall accuracy of network architectures with different numbers of convolution kernels
সারণি 4 বিভিন্ন সংখ্যার কনভ্যুশনাল কার্নেলের সাথে নেটওয়ার্ক আর্কিটেকচারের সামগ্রিক যথার্থতার তালিকা করে। দেখা গেছে যে সংখ্যার কনভ্যুশনাল কার্নেলগুলি (উদাহরণস্বরূপ, 2, 4) শ্রেণিবিন্যাসের নির্ভুলতা হ্রাস করে এবং বিপুল সংখ্যক কনভলিউশন কার্নেলগুলি (উদাহরণস্বরূপ, 32) শ্রেণিবিন্যাসের নির্ভুলতাও হ্রাস করবে। কোরগুলির সংখ্যা 8 বা 16 এ সেট করা উপযুক্ত। তদতিরিক্ত, বিপুল সংখ্যক কনভ্যুশনাল কার্নেলগুলি (উদাহরণস্বরূপ, 16) প্রশিক্ষণের সময়কে প্রচুর পরিমাণে বাড়িয়ে তুলবে।
(3) বিভিন্ন শিক্ষার হার
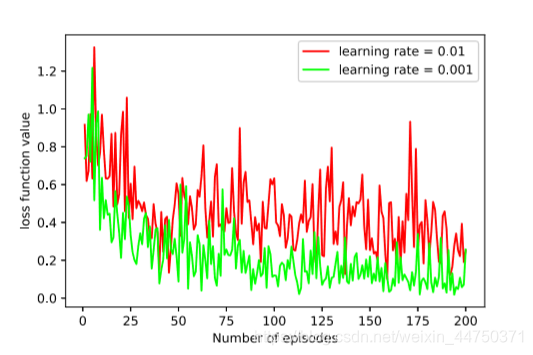
Figure 6 Loss function values for different learning rates
এটি লক্ষ করা যায় যে একটি বৃহত শিক্ষার হার (উদাহরণস্বরূপ, 0.01) ক্ষতি ফাংশনের মান উল্লেখযোগ্যভাবে ওঠানামা করে, যার ফলে নেটওয়ার্ক বিচ্ছিন্ন হতে পারে। বিপরীতে, একটি ছোট শিক্ষার হার (উদাহরণস্বরূপ, 0.001) সম্পূর্ণরূপে ক্ষতির ফাংশনের মান হ্রাস করতে পারে। অতএব, শিক্ষার হার 0.001 এ সেট করা হয়েছে।
(4) the number of samples different queries
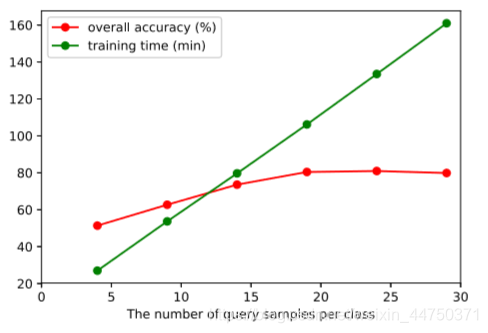
overall accuracy of the sample number of different queries (%) for each class of the data set of FIG. 7 UP and training time (in minutes) (average of 10 runs)
UP ডেটাসেটকে উদাহরণ হিসাবে গ্রহণ করে, প্রতিটি শ্রেণীর জন্য বিভিন্ন কোয়েরি নমুনাগুলির সংখ্যার সামগ্রিক যথার্থতা এবং প্রশিক্ষণের সময় চিত্র 7-এ দেখানো হয়েছে। ক্যোয়ারী ডেটা সেটগুলির সংখ্যা যথাক্রমে 4, 9, 14, 19, 24 এবং 29 এ সেট করা হয়েছে। প্রশিক্ষণ থেকে এটি পর্যবেক্ষণ করা যেতে পারে যে সময়টি ক্যোয়ারী ডেটাসেটের সংখ্যার সাথে রৈখিকভাবে বৃদ্ধি পায়। তবে ক্যোয়ারী ডেটাসেটের সংখ্যা বাড়ার সাথে সাথে নির্ভুলতার হার শিগগিরই স্যাচুরেটেড হবে। অতএব, কোয়েরি ডেটা সেটগুলির সংখ্যা 19 এ সেট করে, পছন্দসই ফলাফল পাওয়া যাবে।
Compare with semi-supervised method
The authors compare the semi-supervised method with the proposed method on four data sets. The experimental results are shown in Table 5-8.
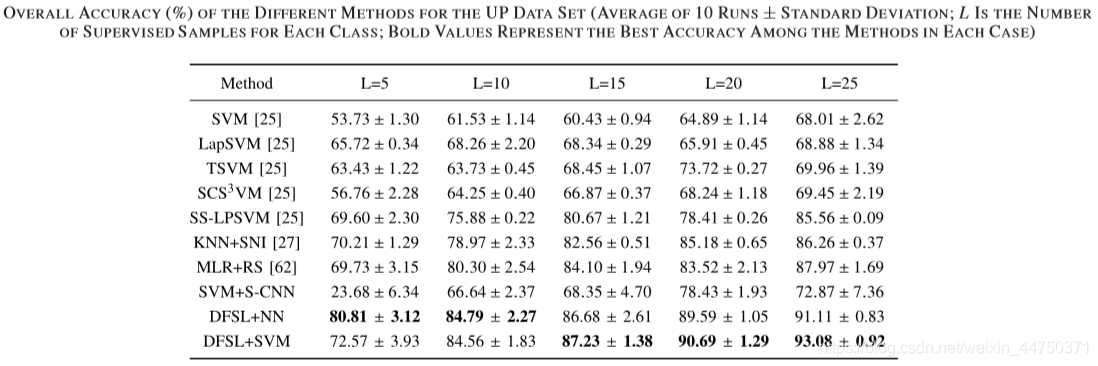
Table 5 accuracy on UP dataset
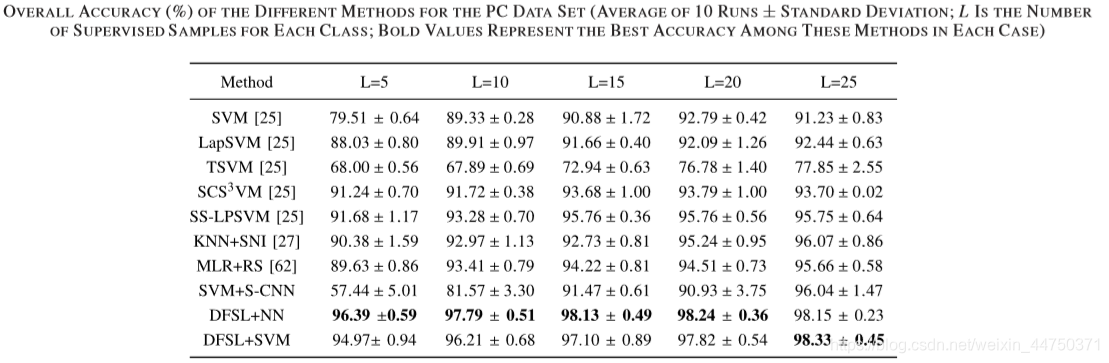
Table 6 accuracy on the PC dataset
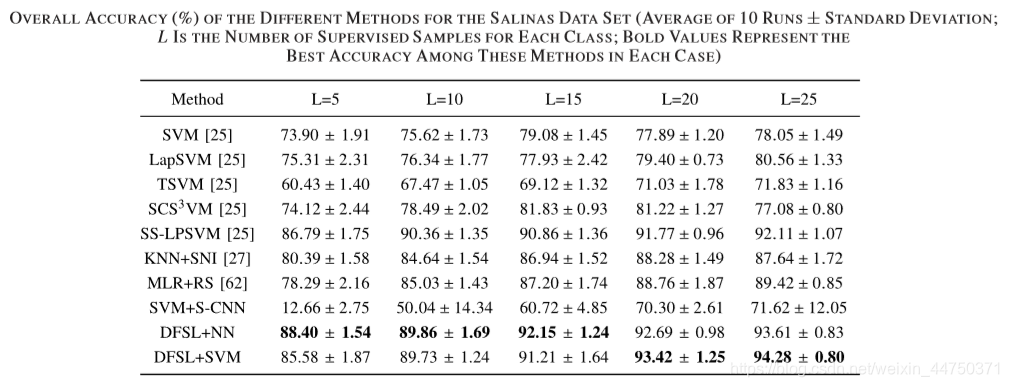
Table 7 accuracy on SALINAS dataset
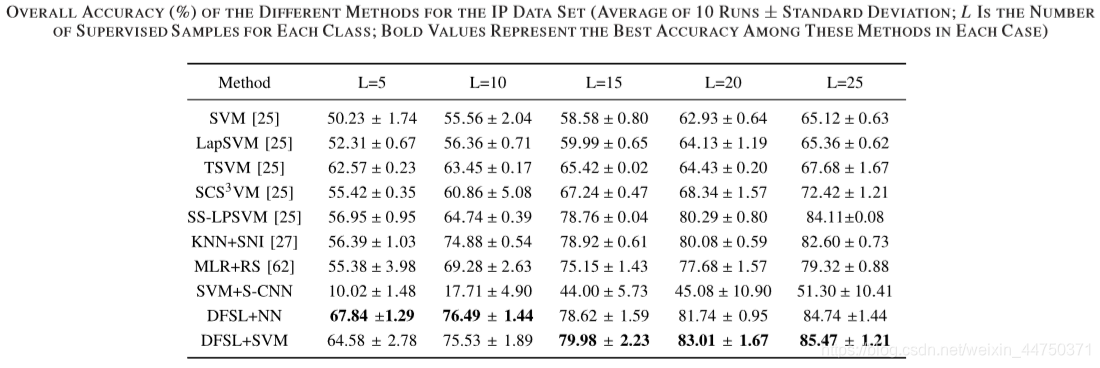
Table 8 accuracy on the IP data set
can conclude the above experiment:
1) শ্রেণিবদ্ধকরণ পদ্ধতির সামগ্রিক নির্ভুলতা সাধারণত এল বৃদ্ধি পাওয়ার সাথে সাথে বৃদ্ধি পায়।
2) আধা-তত্ত্বাবধানের পদ্ধতিগুলি (ল্যাপএসভিএম, টিএসভিএম, এসসিএস 3 ভিএম, এবং এসএস-এলপিএসভিএম) সাধারণত স্ট্যান্ডার্ড এসভিএমের চেয়ে ভাল are
3) এসভিএম + এস-সিএনএন প্রায় কোনও তদারকি করা নমুনা না দিয়ে খুব খারাপভাবে সম্পাদন করে।
4) প্রস্তাবিত ডিএনএসএল পদ্ধতিটি এনএন শ্রেণিবদ্ধ (ডিএফএসএল + এনএন) এবং এসভিএম শ্রেণিবদ্ধ (ডিএফএসএল + এসভিএম) সহ অন্যান্য পদ্ধতির চেয়ে উচ্চতর। বিশেষত, প্রতিটি শ্রেণীর 5 টি লেবেলযুক্ত নমুনার ছোট্ট নমুনাগুলির জন্য, ডিএফএসএল + এনএন দুর্দান্ত শ্রেণিবিন্যাস সম্পাদন করে।
Comparison with CNN-based methods
প্রস্তাবিত পদ্ধতির কার্যকারিতা আরও প্রমাণ করতে লেখক চারটি টেস্ট ডেটা সেটগুলিতে প্রস্তাবিত পদ্ধতির সাথে সিএনএন ভিত্তিক কয়েকটি পদ্ধতির তুলনা করেছেন। পরীক্ষামূলক ফলাফলগুলি টেবিল 10-13-এ প্রদর্শিত হয়েছে।
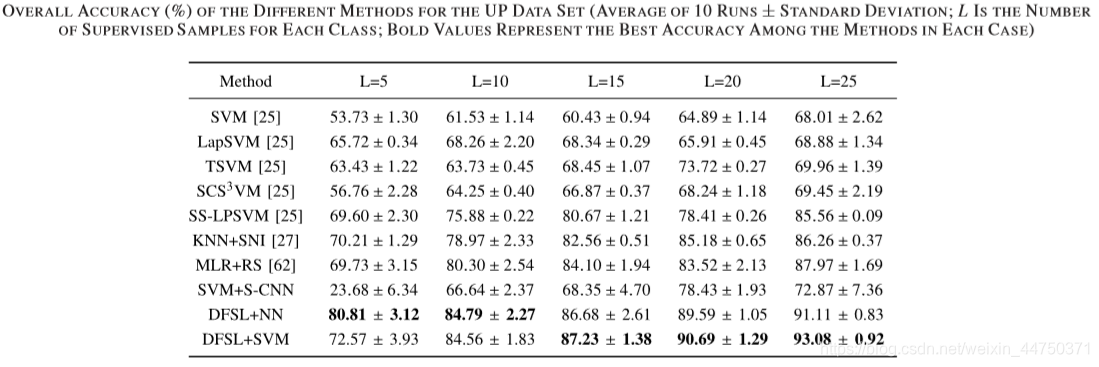
Table 9 accuracy in the dataset UP
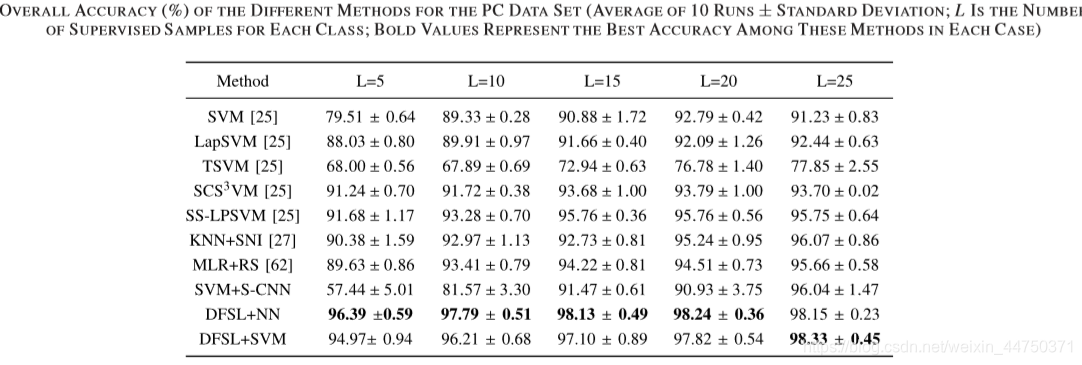
table 10 on the PC accuracy data set
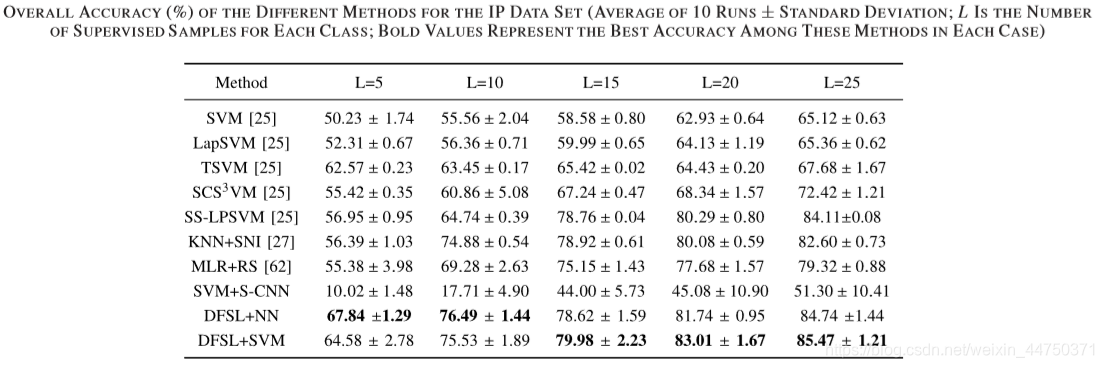
table 11 the IP data set in the accuracy of
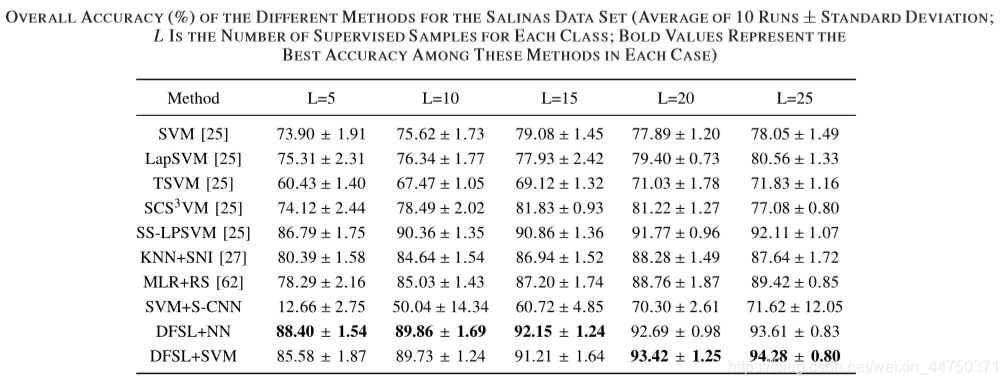
the table 12 on the accuracy of the data set SALINAS
পর্যবেক্ষণ, খুঁজে পাওয়া যেতে পারে প্রথম সব, D-Res- 3-D CNN CNN and R-PCA-CNN সুখ্যাতি করতে পারেন D-Res-3-D CNN. কার্যকারিতা প্রমাণ করেছিলেন।উপরন্তু, আমরা দেখতে পারেন DFSL + NN and DFSL + SVM সবচেয়ে উন্নত CNN-ভিত্তিক পদ্ধতি তুলনায় প্রতিযোগিতামূলক ফলাফল প্রদান করতে পারেন।এটি দেখায় যে প্রস্তাবিত পদ্ধতিটি যখন লেবেলযুক্ত নমুনাগুলি তুলনামূলকভাবে পর্যাপ্ত থাকে তখন আরও ভাল ফলাফল পেতে পারে। নির্দিষ্টভাবে, DFSL + + SVM ইউপি, আইপি এবং Salinas ডেটা সেট মধ্যে সেরা পারফরম্যান্স হয়েছে। এটি দেখায় যে পর্যাপ্ত লেবেলযুক্ত নমুনাগুলি সহ, DFSL + SVM, DFSL + NN এর চেয়ে ভাল ফলাফল পেতে পারেন।
চতুর্থ, সংক্ষিপ্তসার
এই নিবন্ধটি DFSL পদ্ধতির প্রস্তাব করেছে, যা ছোট নমুনা HSI শ্রেণিবিন্যাস সমাধানের জন্য একটি নতুন পদ্ধতি সরবরাহ করে। মূল ধারণাটি হ'ল DFAL পদ্ধতিটি নেটওয়ার্ককে প্রশিক্ষণ দেয় (নিবন্ধে গভীর অবশেষ 3-D CNN) মেট্রিক স্পেস শিখতে, যেখানে একই বর্গের নমুনাগুলি কাছাকাছি থাকে এবং বিভিন্ন শ্রেণির নমুনা দূরত্বে পৃথক করা হয়। এই জাতীয় জায়গায় শ্রেণিবিন্যাস একটি সাধারণ শ্রেণিবদ্ধ (যেমন, NN) দ্বারা সম্পাদন করা যেতে পারে। চারটি বহুল ব্যবহৃত HSI ডেটাসেটগুলিতে পরীক্ষা-নিরীক্ষা করা হয়েছিল এবং ফলাফলগুলি প্রশিক্ষণ মডেলের সাধারণীকরণের দক্ষতা প্রমাণ করেছিল।
0 comments:
Post a Comment