How do Random Forests work?
একটি Random Forest হ'ল একটি জড়ো কৌশল যা একাধিক সিদ্ধান্ত গাছ এবং(Bootstrap Aggregation) বুটস্ট্র্যাপ অগ্রিগেশন নামে পরিচিত একটি প্রযুক্তি যা সাধারণত (bagging)ব্যাগিং নামে পরিচিত, ব্যবহার করে উভয়ই রিগ্রেশন এবং শ্রেণিবিন্যাস কার্য সম্পাদন করতে সক্ষম। আপনি জিজ্ঞাসা করতে পারেন ব্যাগিং কি? ব্যাগিং, Random Forest পদ্ধতিতে প্রতিটি সিদ্ধান্ত গাছকে একটি আলাদা ডেটা নমুনায় প্রশিক্ষণের সাথে জড়িত যেখানে প্রতিস্থাপনের সাথে নমুনা দেওয়া হয়।
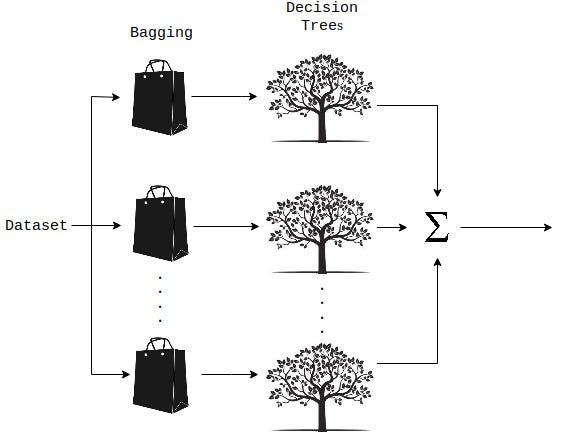
এর পিছনে মূল ধারণাটি পৃথক সিদ্ধান্ত গাছের উপর নির্ভর না করে চূড়ান্ত আউটপুট নির্ধারণে একাধিক সিদ্ধান্ত গাছকে একত্রিত করা। আপনি যদি র্যান্ডম অরণ্যে আরও পড়তে চান তবে আমি কয়েকটি রেফারেন্স লিঙ্ক অন্তর্ভুক্ত করেছি যা এই বিষয়ে গভীরতার ব্যাখ্যা সরবরাহ করে।
এখন আমি আপনাকে দেখাব কিভাবে পাইথন ব্যবহার এলোমেলো বন রিগ্রেশন মডেল বাস্তবায়ন করতে হবে। শুরু করতে, আমাদের কয়েকটি লাইব্রেরি আমদানি করতে হবে।
from sklearn.model_selection import cross_val_score, GridSearchCV
from sklearn.ensemble import RandomForestRegressor
from sklearn.preprocessing import MinMaxScaler
from sklearn.ensemble import RandomForestRegressor
from sklearn.preprocessing import MinMaxScaler
The star here is the scikit-learn library.
Let’s skip straight into the forest. Here’s how everything goes down,
def rfr_model(X, y):# Perform Grid-Search gsc = GridSearchCV( estimator=RandomForestRegressor(), param_grid={ 'max_depth': range(3,7), 'n_estimators': (10, 50, 100, 1000), }, cv=5, scoring='neg_mean_squared_error', verbose=0, n_jobs=-1) grid_result = gsc.fit(X, y) best_params = grid_result.best_params_ rfr = RandomForestRegressor(max_depth=best_params["max_depth"], n_estimators=best_params["n_estimators"], random_state=False, verbose=False)# Perform K-Fold CV scores = cross_val_score(rfr, X, y, cv=10, scoring='neg_mean_absolute_error') return scores
প্রথমে আমরা বৈশিষ্ট্যগুলি (X) এবং ডেটা সেটের নির্ভরশীল (y) পরিবর্তনশীল মানগুলি পাস করি, এলোমেলো বন রেগ্রেশন মডেলের জন্য তৈরি পদ্ধতিতে। তারপরে আমরা স্কেলার্ন গ্রন্থাগার থেকে গ্রিড অনুসন্ধান ক্রস বৈধকরণ পদ্ধতি (আরও তথ্যের জন্য এই নিবন্ধটি পড়ুন) ব্যবহার করি যা নির্দিষ্ট মডেলের মানগুলির একটি নির্দিষ্ট পরিসর থেকে আমাদের মডেলের হাইপারপ্যারামিটারগুলির জন্য ব্যবহার করার অনুকূল মানগুলি নির্ধারণ করে। এখানে, আমরা দুই hyperparameters চয়ন করেছেন; max_depth এবং n_estimators, অপ্টিমাইজ করা হয়। sklearn documentation, মতে, max_depth গাছ ও n_estimators বন গাছের সংখ্যা সর্বাধিক গভীরতা বোঝায়। আদর্শভাবে, আপনি আপনার মডেল থেকে একটি ভাল পারফরম্যান্স আশা করতে পারেন যখন আরো গাছ আছে। যাইহোক, আপনার মডেলটি কীভাবে সম্পাদন করে তা দেখতে আপনাকে অবশ্যই নির্দিষ্ট করা মান সীমাটি সম্পর্কে সতর্ক থাকতে হবে এবং বিভিন্ন মান ব্যবহার করে পরীক্ষা করতে হবে।
একটি এলোমেলো বন রেজিস্ট্রার অবজেক্ট তৈরি করার পরে, আমরা এটিকে cross_val_score() function পাস করি যা প্রদত্ত ডেটাতে K-Fold cross বৈধকরণ (K-Fold cross বৈধকরণ সম্পর্কিত আরও তথ্যের জন্য এই নিবন্ধটি পড়ুন) সম্পাদন করে এবং আউটপুট হিসাবে সরবরাহ করে, error metric value, যা মডেল কর্মক্ষমতা নির্ধারণ করতে ব্যবহার করা যেতে পারে।
scores = cross_val_score(rfr, X, y, cv=10, scoring='neg_mean_absolute_error')
scores = cross_val_score(rfr, X, y, cv=10,
scoring='neg_mean_absolute_error')
এখানে আমরা 10-fold cross validation (cv parameter দ্বারা নির্দিষ্ট) ব্যবহার করেছি যেখানে negative অ্যাবসুলিউট Error(MAE) error metric হিসাবে নেওয়া হয় ( scoring parameter ব্যবহার করে নির্দিষ্ট করা হয়) মডেল কর্মক্ষমতা পরিমাপ করতে। MAE যত কম হবে তত ভাল। আপনি মডেলটি ব্যবহার করে predicted করা মানগুলির তালিকা পেতে cross_val_predict() ফাংশনটিও ব্যবহার করতে পারেন।
predictions = cross_val_predict(rfr, X, y, cv=10)
0 comments:
Post a Comment